引言
文章要解决的问题就是如何高效地优化SAT求解器:
挑战:
- SAT求解器已经高度演化,领域知识极为丰富,学习门槛很高
- SAT求解器众多启发式策略和参数以及算法变体的设计空间太大,难以人工调优
机遇:LLM在数学、编程方面的能力大幅度提升,并推动了一些科学发现。我们可以尝试使用LLM来优化SAT求解器,进而提高SAT求解器的性能。
现有不足:Google做的agent(AlphaEvolve)如下的一些不足之处
- 只能进化一个完整的代码文件
- 最多只能处理数百行级别的代码
- 在评估过程会花费数小时的时间
- 缺少人工设计的验证器
针对以上的问题,本文中所构建的自进化的编码框架(self-evolving coding framework)SATLUTION具有以下特征:
- 可处理仓库级别的代码
- 具有一个规则系统,分为自进化的动态规则库和一个静态的规则库。
- 强制的验证环节,保障代码的正确性
- 大型的分布式的评估设施,可收集多个的指标
- 击败了SAT Competition 2025中所有人类设计的求解器
SATLUTION 框架
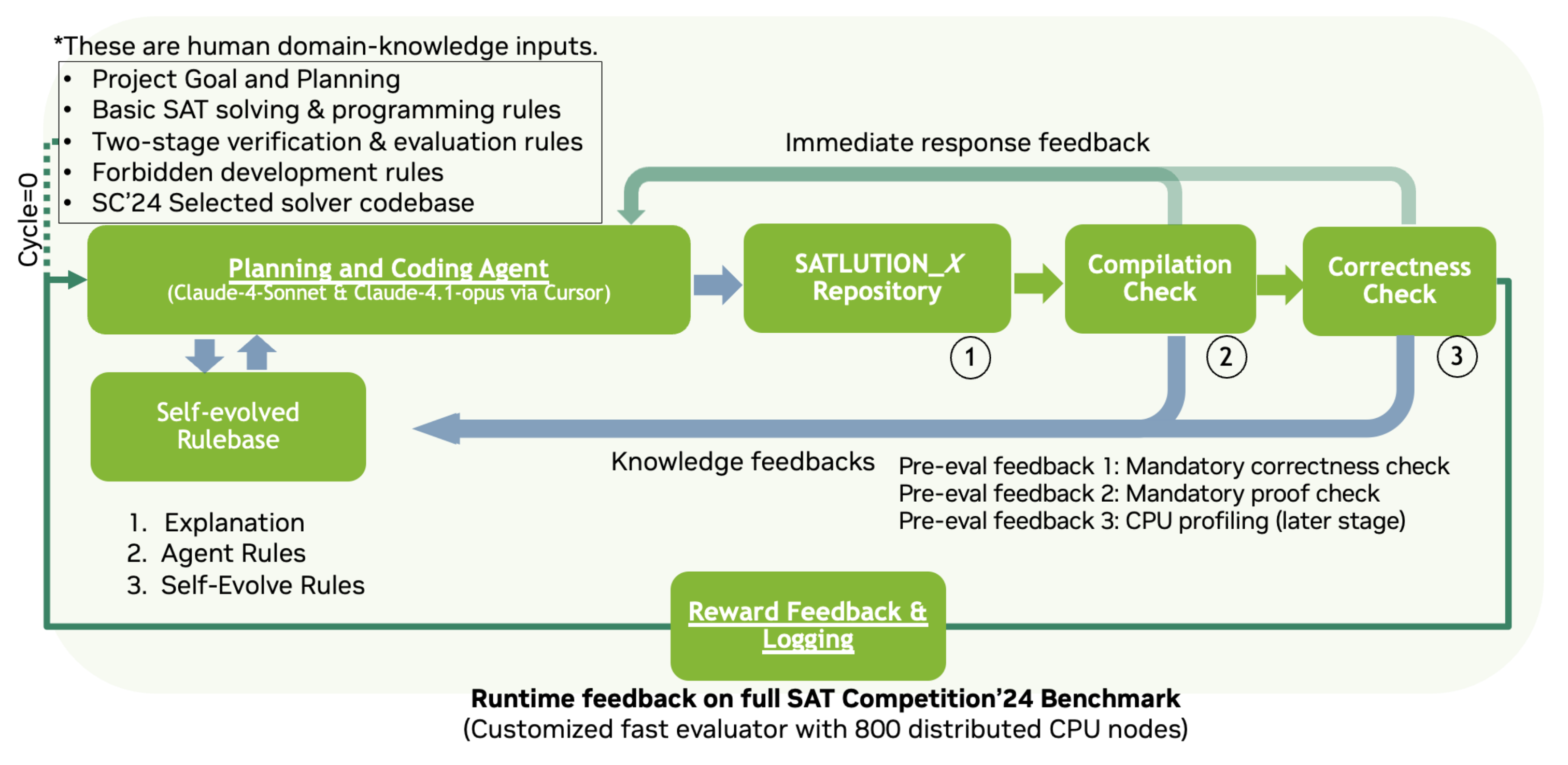
该框架本质上是一个冠军/挑战者模型,经过“代码生成->编译->测试->分析和推理->进化”这一流程的不断迭代,成功的挑战者会取代原有的冠军,进而可以不断地提升代码质量。
框架流程可以分为以下的4个部分:
- 左上角的规划和编码agent模块。这里负责根据代码和规则库的内容推理出下一次迭代有前景的方向和不应该做的事情,并用LLM予以实现。这会生成一个版本的代码仓库。
- 右上角的验证模块。它是用来检查上一步编码agent生成的代码的正确性的模块。它具体分为编译检查和正确性检查两个模块。如果发生错误则会立即停止接下来的动作,然后会收集错误信息更新规则库并尝试用编码agent重新生成代码。
- 下方的评估模块。这里负责把已经正确性检查“通过”的代码拿去跑benchmark,跑出来的结果会用于更新规则库。
- 规则库。规则库的规则用于引导LLM,也会根据验证和评估结果不断进化,并用于分析和推理。
框架基于Cursor实现,采用Claude模型优化求解器。其生成的代码仓库的固定结构如下:

初始化
初始化分为两个步骤,一个是仓库初始化,另一个是规则库初始化。
仓库初始化
作者在这里挑选了SAT Competition 2024中表现良好的5个高性能SAT求解器作为初始种子求解器。相比于只选择一个基准求解器,这会有助于LLM结合它们所用的不同的策略。
规则库初始化
向规则库写入静态规则。包含项目目标、SAT相关的领域知识、代码仓库的结构和SATLUTION框架的基本工作流等静态规则。同时也会把一些动态规则的初始规则设定好,比如禁止的编码模式规则的初始禁止内容。

规划和编码agent
文章中采用LLM作为agent,总共分为规划和编码两个阶段。
规划阶段负责推理,它会根据代码的更改、性能指标、发现的错误和规则库推理出下次迭代的计划。这些计划应该会被写入到HYPOTHESIS.md中。
编码阶段负责写代码和debug,一方面会根据规划阶段推理出的计划修改程序代码(也包括用于构建项目的Makefile代码),另一方面也会就之后验证模块中发现的错误进行debug。
验证模块
在编码agent顺利生成一版仓库代码后,考虑到可能会有很多bug,框架不会直接让这一版代码去跑benchmark,而是编译通过后用少量的计算资源用于测试。如果直接去跑benchmark,因为求解器可能是错的,那么一方面可能会浪费很多时间,另一方面也有可能因为这种错误的迭代污染了打分,破坏了整个进化流程。
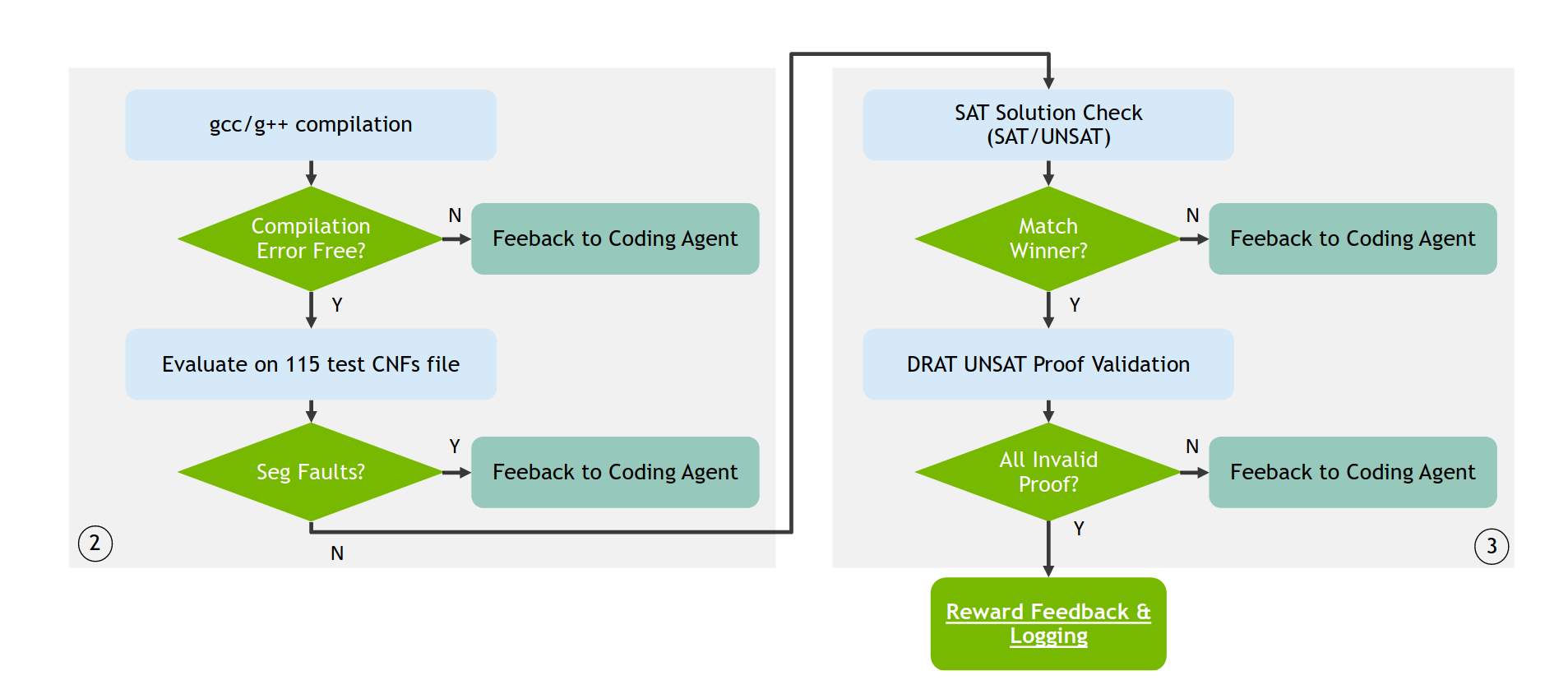
流程
在仓库建成后,实际上会有一个中间步骤用于验证仓库构建是否合法。
重点的验证模块也分为两个部分,分别是编译检查与冒烟测试和正确性检查。
第一阶段是基础的编译检查与冒烟测试。流程是先对代码仓库进行编译、构建检查是否有编译错误,在没有错误的情况下则会运行一组简单的测试,并检查是否会发生一些运行时错误和不一致的结果。如果在这个阶段遇到错误,将会自动地把错误信息反馈给之前的编码agent,使其重新尝试修复代码。(实际上修复代码的工作往往要人工干预)
第二阶段是正确性检查。针对前面跑出来的结果,如果是SAT的,就会检查返回的赋值是否确实是满足的;如果是UNSAT的,则会使用外部的DRAT证明检查器予以证明。如果发现有误则会人工地处理错误信息,并反馈给编码agent。(实际上修复代码的工作往往也要人工干预)
特征
- 任何错误都会导致重新debug生成新代码
- 验证器的代码是人工编写的
- 与规则系统集成,按照规则约束代码,也会因为新的错误添加新的规则
作用
- 尽量避免LLM生成错误代码
- 减少用错误代码运行评估而造成的时间浪费
- 确保之后评估的反馈是有效的
评估模块
评估模块会让上面通过了验证的求解器去跑2024年SAT比赛的400个例子,收集如下指标:
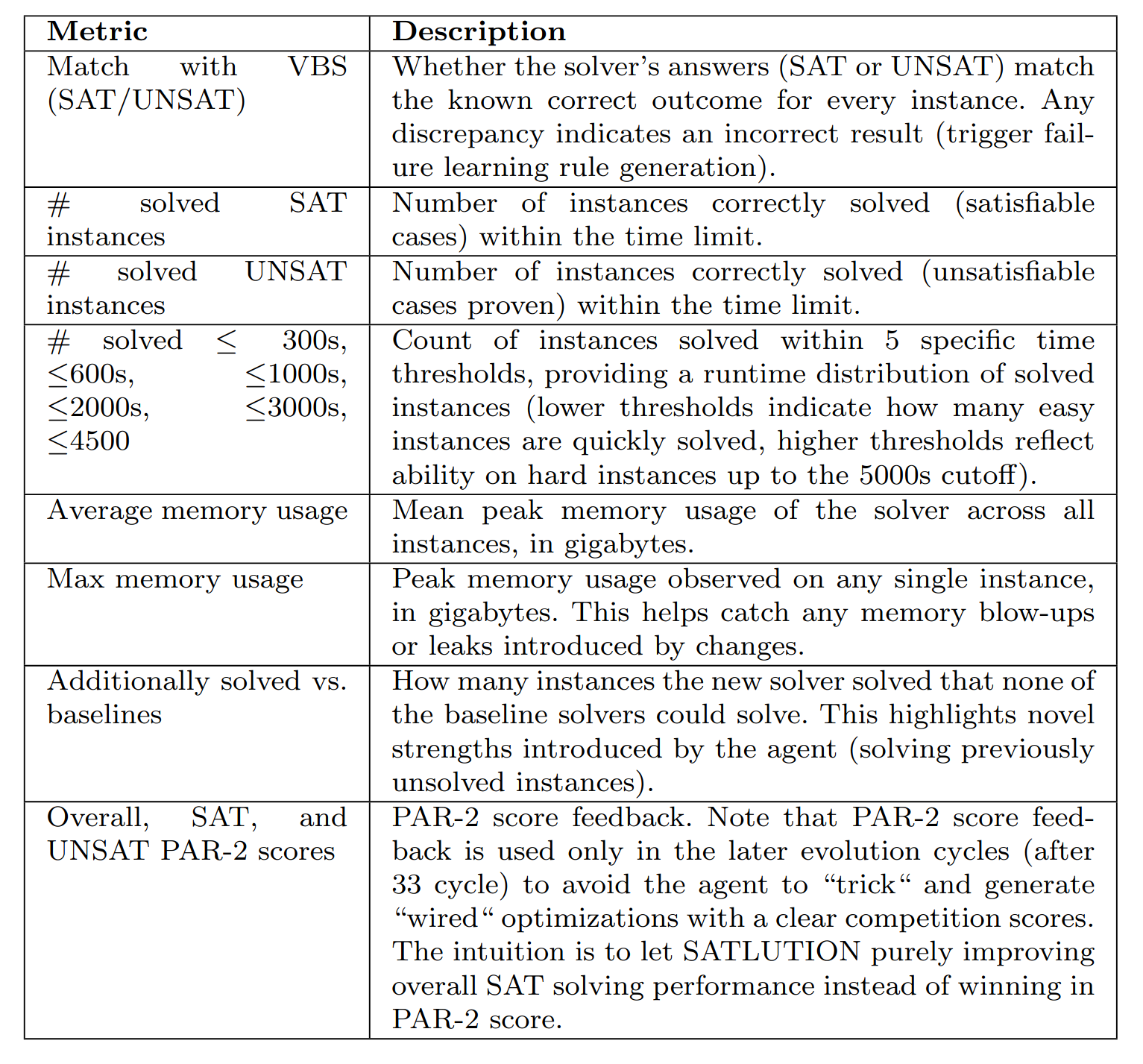
其中VBS全称为虚拟最佳求解器,它汇总了选择的种子求解器的求解结果。评估反馈的打分主要是和PAR-2分数有关。评估出来的这些信息会被写入仓库代码的RESULTS.md中。
实验中发现反馈的打分对于求解器进化的影响也很大。如果打分单单与求解数量有关,那么往往会选择优化UNSAT的例子;而如果引入了PAR-2打分和表格中第3个指标,则会倾向于优化SAT的例子。
规则库
规则库是SATLUTION的一个关键组件。规则分为静态的初始规则和动态的自进化规则。
作用
- 规划:帮助规划agent解析求解器的代码修改并生成迭代策略
- 基本的C/C++编程:确保C/C++的语法、代码风格正确,确保内存安全并遵守求解器的接口。
- 评估前的验证:在跑benchmark前确保代码的正确性。
- 评估后的分析:引导benchmark的结果的分析,区分出性能提升和退化
- 知识学习:保留好的策略、禁止一些错误的策略以防止重复犯错
实现
这些规则会直接作用到Cursor上,放在.cursor/rules/目录里面,具体有以下文件:
- 00 rule compliance verification.md
- 01 pre evaluation testing.md
- 02 critical correctness.md
- 03 mandatory logging.md
- 04 forbidden patterns.md
- 05 automatic rule evolution.md
静态的初始规则是规则库初始化所涉及的规则,除开上文提到的项目目标、SAT相关的领域知识、代码仓库的结构和SATLUTION框架的流程,还有关于编码安全、种子求解器只是的相关内容。
缺乏静态规则,可能会导致更多的结果验证错误、负优化、不可复现的优化等等问题。
动态自进化规则是在验证机制结束后,会有分析器把各种错误日志转化为规则补丁,并用这些补丁更新规则,确保Cursor能用最新的规则指导代码的进化。
在编码agent生成一版代码仓库后到进入上述的验证模块前,就是这些规则进行验证的主要的时机。文中建议的是在git中添加一个pre-commit的hook,确保每次提交都会自动触发合规性验证,当然也可以配合按时触发的检测。
SATLUTION 学习到的策略
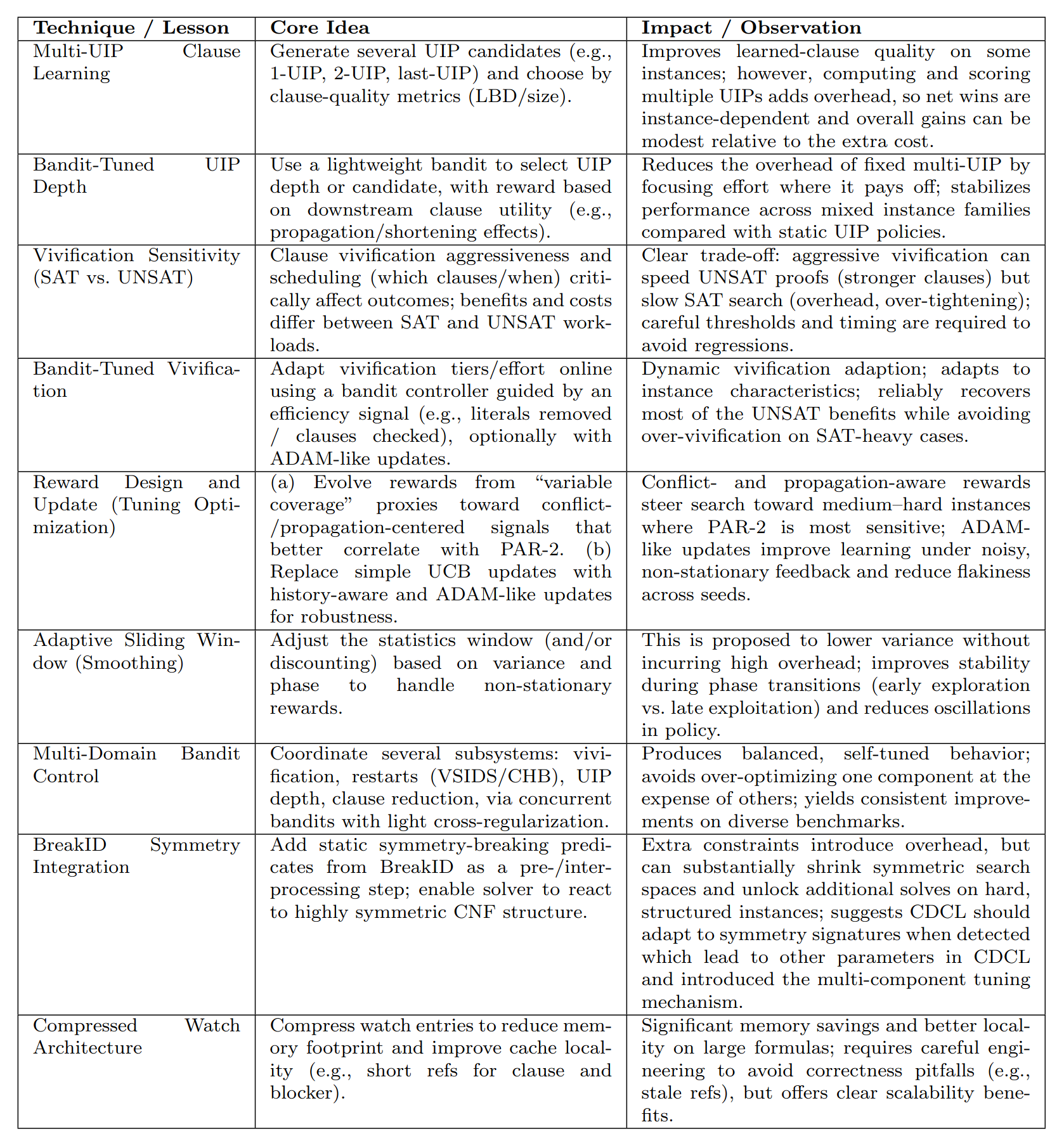
改进点
- 目前的SATLUTION框架只支持单线程的C/C++程序,不允许外部库和非标准的API。
- 优化的目的性不强,可以在评估后生成的反馈中针对的关键模块记录其时间占用等信息,方便予以优化。