欢迎来到PA2,个人感觉是ICS2024中任务量最重的一个。
阶段1
不停计算的机器
理解YEMU如何执行程序
这里状态机就不画了……就简单讲讲YEMU是如何执行一条指令的。
根据图灵机的运行方式:
while (1)
{
从PC指示的存储器位置取出指令;
执行指令;
更新PC;
}教程中提到的代码中取指、更新PC已经很显然了。其中译码部分比较有意思,需要用到C语言中的union、struct的bit-field等技巧,其代码中先用指令的高4位确定其操作码,再根据不同的指令类型译出操作数,并对操作数进行执行。
我们的代码确定了状态机的每一步的状态转换。
RTFSC(2)
这里我看的是《RISC-V开放架构设计之道》,它是中文的,我们很容易能知道这些RISC-V指令的编码
 同时,具体每个指令的具体行为在附录-A里也有说明。
同时,具体每个指令的具体行为在附录-A里也有说明。
立即数背后的故事
- 假设我们需要将NEMU运行在Motorola 68k的机器上(把NEMU的源代码编译成Motorola 68k的机器码)
问题主要出在内存访问上,也就是NEMU的内存(大端)和NEMU内运行的程序(小端)所认为的字节序不同。那么我们需要一字节一字节地按照小端模式把映像加载入NEMU,然后pmem_read和pmem_write函数也需要修改成一字节一字节地按照小端模式读取/存储。
- 假设我们需要把Motorola 68k作为一个新的ISA加入到NEMU中
现在则是NEMU的内存(小端)而NEMU运行的程序(大端)认为的字节序不同了。同理,那么需要一字节一字节地按照大端模式把映像加载入NEMU,然后pmem_read和pmem_write函数也要照样改动。
总之,就是要让NEMU的字节序去配合里面运行的程序。
立即数背后的故事(2)
对于RISC-V32,addi可以加载一个放在低12位的立即数,而lui则可以加载一个高20位的立即数,两个拼一块就是32位的数字了。
我要被宏定义绕晕了, 怎么办?
首先可以通过AI再用man确认了GCC编译时加个-E的flag就可以只让编译器输出预处理后的代码就行了。然后我们改改Makefile,把编译C源文件的地方加个-E即可。
INCLUDES = $(addprefix -I, $(INC_PATH))
CFLAGS := -O2 -MMD -Wall -Werror -E $(INCLUDES) $(CFLAGS)
LDFLAGS := -O2 $(LDFLAGS)
OBJS = $(SRCS:%.c=$(OBJ_DIR)/%.o) $(CXXSRC:%.cc=$(OBJ_DIR)/%.o)
# Compilation patterns
$(OBJ_DIR)/%.o: %.c
@echo + CC $<
@mkdir -p $(dir $@)
@$(CC) $(CFLAGS) -c -o $@ $<
$(call call_fixdep, $(@:.o=.d), $@)最后make clean; make,这样就能输出宏定义展开的内容,方便我们进行理解:
static int decode_exec(Decode *s)
{
int rd = 0;
int rs1 = 0;
int rs2 = 0;
word_t src1 = 0, src2 = 0, imm = 0;
s->dnpc = s->snpc;
# 126 "src/isa/riscv32/inst.c"
{ const void ** __instpat_end = &&__instpat_end_;;
do { uint64_t key, mask, shift; pattern_decode("??????? ????? ????? ??? ????? 00101 11", (sizeof("??????? ????? ????? ??? ????? 00101 11") - 1), &key, &mask, &shift); if ((((uint64_t)((s)->isa.inst.val) >> shift) & mask) == key) { { decode_operand(s, &rd, &rs1, &rs2, &src1, &src2, &imm, TYPE_U); (cpu.gpr[check_reg_idx(rd)]) = s->pc + imm; }; goto *(__instpat_end); } } while (0)
;
do { uint64_t key, mask, shift; pattern_decode("??????? ????? ????? ??? ????? 01101 11", (sizeof("??????? ????? ????? ??? ????? 01101 11") - 1), &key, &mask, &shift); if ((((uint64_t)((s)->isa.inst.val) >> shift) & mask) == key) { { decode_operand(s, &rd, &rs1, &rs2, &src1, &src2, &imm, TYPE_U); (cpu.gpr[check_reg_idx(rd)]) = imm; }; goto *(__instpat_end); } } while (0);
do { uint64_t key, mask, shift; pattern_decode("??????? ????? ????? 100 ????? 00000 11", (sizeof("??????? ????? ????? 100 ????? 00000 11") - 1), &key, &mask, &shift); if ((((uint64_t)((s)->isa.inst.val) >> shift) & mask) == key) { { decode_operand(s, &rd, &rs1, &rs2, &src1, &src2, &imm, TYPE_I); (cpu.gpr[check_reg_idx(rd)]) = vaddr_read(src1 + imm, 1); }; goto *(__instpat_end); } } while (0)
;RTFSC理解指令执行的过程
- 准备工作 在
exec_once中设置decode结构体的pc和snpc为当前pc值。 - 取指令 在
isa_exec_once中第一行就从内存中的snpc处读入指令并放到decode结构体中。 - 译码、执行 首先由
pattern_decode生成NEMU中已实现的各个指令的掩码等信息,然后在decode_exec中顺着各个INSTPAT一个一个用函数decode_operand进行检测,若匹配上则执行该指令,若无一匹配则表明是无效指令。 - 更新PC 用执行过程中可能会更改的dnpc更新pc值。
其中译码部分的宏值得一提:
- 利用GCC提供的标签地址扩展进行跳转。
pattern_decode的生成的操作码(key),操作码的掩码(mask)和偏移(shift)。可能让我来写就是写一个循环遍历,但是框架代码中用的是利用宏递归的展开,然后去一个一个地从左往右得到信息。根据下面这段代码,能够理解这三个信息的用法:$NEMU_HOME/include/cpu/decode.h #define INSTPAT(pattern, ...) \ do \ { \ uint64_t key, mask, shift; \ pattern_decode(pattern, STRLEN(pattern), &key, &mask, &shift); \ if ((((uint64_t)INSTPAT_INST(s) >> shift) & mask) == key) \ { \ INSTPAT_MATCH(s, ##__VA_ARGS__); \ goto *(__instpat_end); \ } \ } while (0)- 关于
__VA_ARGS__的使用技巧。Note: some compilers offer an extension that allows
##to appear after a comma and before__VA_ARGS__, in which case the##does nothing when the variable arguments are present, but removes the comma when the variable arguments are not present: this makes it possible to define macros such asfprintf (stderr, format, ##__VA_ARGS__). This can also be achieved in a standard manner using__VA_OPT__, such asfprintf (stderr, format __VA_OPT__(, ) __VA_ARGS__).(since C++20) - 关于符号扩展
SEXT(x, len)的技巧,其中用到了GCC的语句表达式扩展。对于这个代码$NEMU_HOME/include/macro.h #define SEXT(x, len) ({ struct { int64_t n : len; } __x = { .n = x }; (uint64_t)__x.n; })x赋给这里的n,按照PA1中讲到的整形转换问题的方法,这里的n将会存储成符号扩展成len长度的有符号数,然后转成无符号数。这些过程都只是添加了原有数字x前面的所谓的“符号位”。
不禁感叹会写宏的人都太牛了,况且宏还很难调试。
为什么执行了未实现指令会出现上述报错信息
会匹配上最后一个INSTPAT,进而通过函数invalid_inst输出相关信息,并设置nemu_state为NEMU_ABORT,退出码为-1,这会决定cpu_exec函数中的退出日志。
运行第一个客户程序
很简单,反复运行程序,查看报错信息对应的指令,查手册得到对应指令的含义并予以实现即可。
实现更多的指令
当然需要模仿immU,实现其他指令类型的取立即数的方式,也需要添加大量其他的INSTPAT以实现指令。
需要注意的是srai指令是一个坑,对于一般的I型指令,其立即数和srai的shamt的域并不相同,shamt相对于立即数少了。

 因此需要实现为:
因此需要实现为:
INSTPAT("010000? ????? ????? 101 ????? 00100 11", srai, I, R(rd) = ((sword_t)src1 >> (imm - (1 << 10))));mips32的分支延迟槽
还没学mips32,也许可以放进去一些没什么意义的指令,比如把某个寄存器的值复制到R0?反正R0始终会是0,所以不会有什么影响。
指令名对照
伪指令本身的二进制表达肯定不是一个伪指令,所以可以试着对照指令集手册。
事实上还可以给objdump添加-M no-aliases以禁用伪指令:
riscv64-linux-gnu-objdump -M no-aliases -d unalign-riscv32-nemu.elf阶段2
任务量最重的阶段,没有之一。
程序,运行时环境与AM
这又能怎么样呢
解耦后,能在debug的时候更容易找到bug所存在的层次。例如库和上层程序,它俩是分离的能方便分别测试。
为什么要有AM? (建议二周目思考)
AM给的运行时环境比较粗糙且简单,比较靠底层,并未为安全着想。而操作系统本身是运行在AM上的软件,其运行时环境更加复杂且多样,会更加考虑操作系统中的概念(例如进程、文件系统)以方便在操作系统上的程序的开发。
了解一下volatile关键字:
An object that has volatile-qualified type may be modified in ways unknown to the implementation or have other unknown side effects. Therefore any expression referring to such an object shall be evaluated strictly according to the rules of the abstract machine, as described in 5.1.2.3. Furthermore, at every sequence point the value last stored in the object shall agree with that prescribed by the abstract machine, except as modified by the unknown factors mentioned previously. What constitutes an access to an object that has volatile-qualified type is implementation-defined.
A volatile declaration may be used to describe an object corresponding to a memory-mapped input/output port or an object accessed by an asynchronously interrupting function. Actions on objects so declared shall not be ‘‘optimized out’’ by an implementation or reordered except as permitted by the rules for evaluating expressions.
再读一读C99手册里关于side effects的说法:
Accessing a volatile object, modifying an object, modifying a file, or calling a function that does any of those operations are all side effects,11) which are changes in the state of the execution environment. Evaluation of an expression may produce side effects. At certain specified points in the execution sequence called sequence points, all side effects of previous evaluations shall be complete and no side effects of subsequent evaluations shall have taken place. (A summary of the sequence points is given in annex C.)
这样我们就会知道,volatile关键字的作用是把对这个volatile对象的读操作也视为一种side effects,这会让它的读操作不会被优化,而是严格按照语义执行。因此它事实上并不能用于多线程环境中。
阅读Makefile
这一块的Makefile有点复杂,所以我们先直接在这里梳理一下AM中的程序是如何构建的。
对于cpu_tests里的小例子dummy,假设我们用这样的命令来运行:
make ARCH=riscv32-nemu ALL=dummy run首先会通过cpu_tests里的Makefile生成一个Makefile.dummy,这个Makefile.dummy会include$AM_HOME/Makefile,使得cpu_tests里的东西和abstract_machine连动起来,同时会运行$AM_HOME/Makefile里的run目标。因此Makefile会打印如下信息:
# Building dummy-run [riscv32-nemu]
这个run目标也不是直接存在于$AM_HOME/Makefile的,而是通过里面的两层include,实际上在$AM_HOME/scripts/platform/nemu.mk里面。然后这个run目标依赖于insert_arg,又依赖于image,接着依赖于image-dep,最后可以看到在$AM_HOME/Makefile里image-dep又依赖于$(LIBS)和$(IMAGE).elf。接着读源码,这个$(LIBS)就可以又去make$AM_HOME/Makefile里的archieve目标,这个archieve目标就会去把库里的.c编译成.o后,用AR打包成一个静态库。因此会打印如下信息:
# Building am-archive [riscv32-nemu]
+ CC src/platform/nemu/trm.c
+ CC src/platform/nemu/ioe/ioe.c
+ CC src/platform/nemu/ioe/timer.c
+ CC src/platform/nemu/ioe/input.c
+ CC src/platform/nemu/ioe/gpu.c
+ CC src/platform/nemu/ioe/audio.c
+ CC src/platform/nemu/ioe/disk.c
+ CC src/platform/nemu/mpe.c
+ AS src/riscv/nemu/start.S
+ CC src/riscv/nemu/cte.c
+ AS src/riscv/nemu/trap.S
+ CC src/riscv/nemu/vme.c
+ AR -> build/am-riscv32-nemu.a
以及:
# Building klib-archive [riscv32-nemu]
+ CC src/int64.c
+ CC src/string.c
+ CC src/stdlib.c
+ CC src/stdio.c
+ CC src/cpp.c
+ AR -> build/klib-riscv32-nemu.a
而这个$(IMAGE).elf则会先把cpu_tests里指定的dummy.c编译成dummy.o,然后用LD和之前已经构建好的.a静态库进行链接,得到elf文件,这样image-dep目标就已经完成了。所以会输出以下内容。
+ CC tests/dummy.c
# Creating image [riscv32-nemu]
+ LD -> build/dummy-riscv32-nemu.elf
然后在$AM_HOME/scripts/platform/nemu.mk里完成image目标,其实这里就是先用objdump进行反汇编,输出到一个txt文件中,再用objcopy创建一个bin文件。到这里image目标就完成了,然后再是完成insert-arg目标,最后在run目标中,把这个bin文件作为映像放到NEMU中运行。
通过批处理模式运行NEMU
只要看了Makefile的源码,这块就变得十足的简单了。甚至考查的地方都是最简单的部分。整个AM中的Makefile和NEMU连动的地方有且只有image目标里,即:
run: insert-arg
$(MAKE) -C $(NEMU_HOME) ISA=$(ISA) run ARGS="$(NEMUFLAGS)" IMG=$(IMAGE).bin注意到NEMU里面有一个参数-b(--batch),它可以通过函数sdb_set_batch_mode启用批处理模式,而通过阅读NEMU的Makefile,我们可以知道实际上上面传入的ARGS就是给NEMU运行时的参数:
override ARGS ?= --log=$(BUILD_DIR)/nemu-log.txt
override ARGS += $(ARGS_DIFF)
# Command to execute NEMU
IMG ?=
NEMU_EXEC := $(BINARY) $(ARGS) $(IMG)
run-env: $(BINARY) $(DIFF_REF_SO)
run: run-env
$(call git_commit, "run NEMU")
$(NEMU_EXEC)所以我们在$AM_HOME/scripts/platform/nemu.mk的NEMUFLAGS里添个--batch就行了。
NEMUFLAGS += -l $(shell dirname $(IMAGE).elf)/nemu-log.txt --batch --elf=$(IMAGE).elf RISC-V指令测试
没专门去下载测试用例去测试,懒了。
实现字符串处理函数
为了跑通cpu-tests中的string,只需要实现strcmp、strcat、strcpy、memcmp、memset这几个函数就够了,不过查阅手册是很重要的。比如你会在man strcpy发现这个东西:
The strings src and dst may not overlap.
试想一下,如果没有这个假设,那么两个重叠的字符串的strcpy的实现将会变得更加复杂一些。这是我的strcmp的实现:
int strcmp(const char *s1, const char *s2)
{
size_t i = 0;
int diff = 0;
while (!diff)
{
diff = s1[i] - s2[i];
if (s1[i] == '\0' || s2[i] == '\0')
break;
i++;
}
return diff;
}下面教程中的警告也提示了这一内容,真的很贴心了,不断地警告你每个细节都要有详细真实的手册作为支撑。
UB, 编译优化和datalab
之后再学习一下整数溢出的知识吧~
不过根据下面截取自cppreference的描述,虽然有符号数的溢出是UB,但是似乎好像对于(C++ 20及以上)的有符号数的溢出都是wrap around的结果了。
Overflows
Unsigned integer arithmetic is always performed modulo 2n
where n is the number of bits in that particular integer. E.g. for unsigned int, adding one to UINT_MAX gives 0, and subtracting one from 0 gives UINT_MAX.When signed integer arithmetic operation overflows (the result does not fit in the result type), the behavior is undefined, — the possible manifestations of such an operation include:
- it wraps around according to the rules of the representation (typically two’s complement),
- it traps — on some platforms or due to compiler options (e.g.
-ftrapvin GCC and Clang),- it saturates to minimal or maximal value (on many DSPs),
- it is completely optimized out by the compiler.
However, all C++ compilers use two’s complement representation, and as of C++20, it is the only representation allowed by the standard, with the guaranteed range from to (e.g. −128 to 127 for a signed 8-bit type).
实现sprintf
孩子们,我并不是那么容易实现。思路很简单,但是写的比较屎山,如果要改得更加易读还是觉得用正则表达式比较好。而且可以把sprintf中的一部分放到vsprintf中去做,这样能避免重复性代码。唯一可能不太熟悉的就是C语言里面可变参数的使用,我在下一小节会简单介绍。
static void putchar_to_c_str(const char ch, int *tot, char **out) {
*((*out)++) = ch;
(*tot)++;
}
static bool isalpha(char ch) {
return (ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z');
}
static void analyze_fmtch(const char* fmt, size_t *i, int *tot, void (*out_func)(const char, int *, char **), char **out, va_list *args) {
#define OUT(ch) do {out_func(ch, tot, out); } while (0)
if (fmt[*i] == '%') {
size_t l = *i;
size_t r = *i;
size_t dot = *i;
bool left_align = false;
bool sign = false;
while (!isalpha(fmt[*i])) (*i)++;
r = *i - 1;
char pre = ' ';
size_t width = 1;
bool fnum = true;
for (size_t j = l; j <= r; j++) {
if (fmt[j] == '.') {
dot = j;
break;
}
}
for (size_t j = l; j < dot; j++) {
switch (fmt[j]) {
case '-':
left_align = true;
break;
case '+':
sign = true;
break;
case ' ':
pre = ' ';
break;
default:
if (fmt[j] == '0' && fnum)
pre = '0';
if (fnum)
width = 0;
width *= 10;
width += fmt[j] - '0';
fnum = false;
}
}
switch (fmt[*i]) {
case 's':
char *str = (char *)va_arg(*args, const char *);
while (*str) {
OUT(*str);
str++;
}
break;
case 'c':
char ch = va_arg(*args, int);
OUT(ch);
break;
case 'i':
case 'x':
case 'o':
case 'd':
int tmp_num = va_arg(*args, int);
unsigned int num = abs(tmp_num);
char num_str[15];
int j = 0;
int base = 10;
switch (fmt[*i]) {
case 'i':
case 'd':
base = 10;
break;
case 'x':
base = 16;
break;
case 'o':
base = 8;
break;
}
do {
int bit = num % base;
char ch_bit = bit < 10 ? bit + '0' : bit - 10 + 'a';
num_str[j++] = ch_bit;
num /= base;
} while(num);
size_t num_len = j;
if (tmp_num < 0 || (tmp_num > 0 && sign))
num_len++;
if (!left_align && pre == ' ') {
for (int cnt = width - num_len; cnt > 0; cnt--)
OUT(' ');
}
if (tmp_num < 0)
OUT('-');
if (tmp_num > 0 && sign)
OUT('+');
if (!left_align && pre == '0') {
for (int cnt = width - num_len; cnt > 0; cnt--)
OUT('0');
}
for (--j ;j >= 0; j--) {
OUT(num_str[j]);
}
if (left_align) {
for (int cnt = width - num_len; cnt > 0; cnt--)
OUT(' ');
}
break;
default:
panic("Not implemented");
}
}
else {
OUT(fmt[*i]);
}
(*i)++;
#undef OUT
}
int sprintf(char *out, const char *fmt, ...) {
va_list args;
va_start(args, fmt);
int tot = 0;
size_t i = 0;
while (fmt[i]) {
analyze_fmtch(fmt, &i, &tot, putchar_to_c_str, &out, &args);
}
*out = '\0';
va_end(args);
return tot;
}stdarg是如何实现的?
观察到实际上我们的klib中include的stdarg.h是直接include的本地host机上的stdarg.h,即/usr/lib/gcc-cross/riscv64-linux-gnu/13/include/stdarg.h,于是简单地看一下,就会发现有这些内容:
#if defined __STDC_VERSION__ && __STDC_VERSION__ > 201710L
#define va_start(v, ...) __builtin_va_start(v, 0)
#else
#define va_start(v,l) __builtin_va_start(v,l)
#endif
#define va_end(v) __builtin_va_end(v)
#define va_arg(v,l) __builtin_va_arg(v,l)
#if !defined(__STRICT_ANSI__) || __STDC_VERSION__ + 0 >= 199900L \
|| __cplusplus + 0 >= 201103L
#define va_copy(d,s) __builtin_va_copy(d,s)
#endif
#define __va_copy(d,s) __builtin_va_copy(d,s)从cppreference里面可以知道这些:
va_listis a complete object type suitable for holding the information needed by the macrosva_start,va_copy,va_arg, andva_end.
If a
va_listinstance is created, passed to another function, and used viava_argin that function, then any subsequent use in the calling function should be preceded by a call tova_end.
可以看到,对于C99标准,首先利用的是va_start把va_list用可变参数前面的那一个参数初始化一下,然后再用va_arg去遍历,最后用va_end去结束。由于不同的ISA的函数调用ABI不同,像GCC里面就是用的GCC内建函数。
先看下GCC是如何实现的,我们简单地编写了这么一段代码如下:
#include <stdio.h>
#include <stdarg.h>
int good_code(int count, ...) {
va_list args;
va_start(args, count);
return 1;
}
int main()
{
int sum = good_code(3, 1, 2, 3);
printf("sum = %d.", sum);
return 0;
}然后把它编译、汇编后看看它的汇编代码:
00000000 <good_code>:
0: fb010113 addi sp,sp,-80
4: 02112623 sw ra,44(sp)
8: 02812423 sw s0,40(sp)
c: 03010413 addi s0,sp,48
10: fca42e23 sw a0,-36(s0)
14: 00b42223 sw a1,4(s0)
18: 00c42423 sw a2,8(s0)
1c: 00d42623 sw a3,12(s0)
20: 00e42823 sw a4,16(s0)
24: 00f42a23 sw a5,20(s0)
28: 01042c23 sw a6,24(s0)
2c: 01142e23 sw a7,28(s0)
30: 00000797 auipc a5,0x0
34: 0007a783 lw a5,0(a5) # 30 <good_code+0x30>
38: 0007a703 lw a4,0(a5)
3c: fee42623 sw a4,-20(s0)
40: 00000713 li a4,0
44: 02040793 addi a5,s0,32
48: fcf42c23 sw a5,-40(s0)
4c: fd842783 lw a5,-40(s0)
50: fe478793 addi a5,a5,-28
54: fef42423 sw a5,-24(s0)
58: 00100793 li a5,1
5c: 00078713 mv a4,a5
60: 00000797 auipc a5,0x0
64: 0007a783 lw a5,0(a5) # 60 <good_code+0x60>
68: fec42683 lw a3,-20(s0)
6c: 0007a783 lw a5,0(a5)
70: 00f6c7b3 xor a5,a3,a5
74: 00000693 li a3,0
78: 00078663 beqz a5,84 <.L3>
7c: 00000097 auipc ra,0x0
80: 000080e7 jalr ra # 7c <good_code+0x7c>
00000084 <.L3>:
84: 00070513 mv a0,a4
88: 02c12083 lw ra,44(sp)
8c: 02812403 lw s0,40(sp)
90: 05010113 addi sp,sp,80
94: 00008067 ret
00000098 <main>:
98: fe010113 addi sp,sp,-32
9c: 00112e23 sw ra,28(sp)
a0: 00812c23 sw s0,24(sp)
a4: 02010413 addi s0,sp,32
a8: 00300693 li a3,3
ac: 00200613 li a2,2
b0: 00100593 li a1,1
b4: 00300513 li a0,3
b8: 00000097 auipc ra,0x0
bc: 000080e7 jalr ra # b8 <main+0x20>
c0: fea42623 sw a0,-20(s0)
c4: fec42583 lw a1,-20(s0)
c8: 00000517 auipc a0,0x0
cc: 00050513 mv a0,a0
d0: 00000097 auipc ra,0x0
d4: 000080e7 jalr ra # d0 <main+0x38>
d8: 00000793 li a5,0
dc: 00078513 mv a0,a5
e0: 01c12083 lw ra,28(sp)
e4: 01812403 lw s0,24(sp)
e8: 02010113 addi sp,sp,32
ec: 00008067 ret在main函数里,若干个参数被传入,显然是把这些参数放在了寄存器里面。然后在good_code里,首先把这些参数从寄存器里挪到了内存里面去。然后va_start的实现看上去就是把va_list
当作一个指针指向了可变参数里的第一个参数。
这样就能揣摩出这几个宏是怎么实现的了。首先声明一下,下面的sizeof对应的大小都是跟4字节对齐了的sizeof,比如一个short是2字节的,也得当作4字节。首先,va_start需要传入va_list和可变参数前面的那一个参数,于是我们可以取得这个参数的地址,然后加上sizeof这个参数,就可以得到可变参数里的第一个参数的地址,并赋给va_list。
然后va_arg就对应的是遍历参数,这里我们的实现思路就是:根据给出的不同的类型,解引用当前的va_list,得到这个参数,然后给va_list加上sizeof这个类型。
最后的va_end就当作给va_list赋值为空指针吧。
另外还有个va_copy,在这里就被直接当作普普通通的指针的复制就行了。
基础设施(2)
现在我们又回到了NEMU去完成一些必要的基础设施。
指定trace输出的时机和条件
根据教程中所说,很容易能找到记录itrace的地方,而指定其输出条件的地方则是在这里:
static void trace_and_difftest(Decode *_this, vaddr_t dnpc)
{
#ifdef CONFIG_ITRACE_COND
if (ITRACE_COND)
{
log_write("%s\n", _this->logbuf);
}
#endif
if (g_print_step)
{
IFDEF(CONFIG_ITRACE, puts(_this->logbuf));
}
IFDEF(CONFIG_DIFFTEST, difftest_step(_this->pc, dnpc));
#ifdef CONFIG_WATCHPOINT
bool check_wp();
bool checked = check_wp();
if (checked)
{
nemu_state.state = NEMU_STOP;
}
#endif
}而这个ITRACE_COND一开始是在Kconfig生成出来的一个C语言的宏CONFIG_ITRACE_COND,然后通过Makefile中给cflags添进去的宏:
CFLAGS_TRACE += -DITRACE_COND=$(if $(CONFIG_ITRACE_COND),$(call remove_quote,$(CONFIG_ITRACE_COND)),true)itrace因为是大佬们写的,所以输出挺规整的。因此可以考虑用grep,awk,sed等等工具进行筛选处理。这些我还都不是很熟。之后学学吧。
实现iringbuf
说实话,如果实现成像教程里面那样的格式还挺难的,一般来说我只能保证最后一行是导致崩溃的那一条指令。因为在之后添加了输入、中断机制等等之后没有办法去预测接下来会执行的指令。
不过还是照样可以用ring buffer来实现的。很典型的要用两个指针来表示数据的开头和结尾。不过需要注意的是为了判断空和满需要特殊处理,因为这两个状态下的两个指针的相对状态都一样。
核心代码如下:
static size_t nxt_idx(int idx)
{
return (idx + 1) % NR_IRINGBUF;
}
IR *push_ir()
{
IR *tmp = iringbuf + tail;
if (tail == head && !first)
{
head = nxt_idx(head);
}
tail = nxt_idx(tail);
first = false;
return tmp;
}
void print_ir()
{
if (first)
return;
size_t idx = head;
puts(iringbuf[idx].logbuf);
log_write("%s\n", iringbuf[idx].logbuf);
idx = nxt_idx(idx);
while (idx != tail)
{
puts(iringbuf[idx].logbuf);
log_write("%s\n", iringbuf[idx].logbuf);
idx = nxt_idx(idx);
}
}这是使用方式:
static void exec_once(Decode *s, vaddr_t pc)
{
s->pc = pc;
s->snpc = pc;
isa_exec_once(s);
cpu.pc = s->dnpc;
#ifdef CONFIG_ITRACE
char *p = s->logbuf;
p += snprintf(p, sizeof(s->logbuf), FMT_WORD ":", s->pc);
int ilen = s->snpc - s->pc;
int i;
uint8_t *inst = (uint8_t *)&s->isa.inst.val;
for (i = ilen - 1; i >= 0; i--)
{
p += snprintf(p, 4, " %02x", inst[i]);
}
int ilen_max = MUXDEF(CONFIG_ISA_x86, 8, 4);
int space_len = ilen_max - ilen;
if (space_len < 0)
space_len = 0;
space_len = space_len * 3 + 1;
memset(p, ' ', space_len);
p += space_len;
void disassemble(char *str, int size, uint64_t pc, uint8_t *code,
int nbyte);
disassemble(p, s->logbuf + sizeof(s->logbuf) - p,
MUXDEF(CONFIG_ISA_x86, s->snpc, s->pc),
(uint8_t *)&s->isa.inst.val, ilen);
IR *new_ir = push_ir();
strcpy(new_ir->logbuf, s->logbuf);
#endif
}
...
void assert_fail_msg()
{
isa_reg_display();
print_ir();
statistic();
}效果如图,这是模拟器自带的映像跑得结果,和itrace的输出格式上长的一模一样:
0x80000000: 00 00 02 97 auipc t0, 0
0x80000004: 00 02 88 23 sb zero, 0x10(t0)
0x80000008: 01 02 c5 03 lbu a0, 0x10(t0)
0x8000000c: 00 10 00 73 ebreak
实现mtrace
实现方式很简单,就像教程里面所说的一样。
static void print_paddr_read(paddr_t addr, int len, word_t res)
{
#ifdef CONFIG_MTRACE
if (MTRACE_COND)
{
log_write(FMT_WORD ",%d,r"
": " FMT_WORD "\n",
addr, len, res);
}
#endif
// printf(FMT_WORD ",%d,r" ": " FMT_WORD "\n", addr, len, res);
}
word_t paddr_read(paddr_t addr, int len)
{
word_t res = 0;
if (likely(in_pmem(addr)))
{
res = pmem_read(addr, len);
print_paddr_read(addr, len, res);
return res;
}
IFDEF(CONFIG_DEVICE, res = mmio_read(addr, len); return res);
out_of_bound(addr);
return 0;
}
static void print_paddr_write(paddr_t addr, int len, word_t res)
{
#ifdef CONFIG_MTRACE
if (MTRACE_COND)
{
log_write(FMT_WORD ",%d,w"
": " FMT_WORD "\n",
addr, len, res);
}
#endif
// printf(FMT_WORD ",%d,w" ": " FMT_WORD "\n", addr, len, res);
}
void paddr_write(paddr_t addr, int len, word_t data)
{
if (likely(in_pmem(addr)))
{
pmem_write(addr, len, data);
print_paddr_write(addr, len, data);
return;
}
IFDEF(CONFIG_DEVICE, mmio_write(addr, len, data); return);
out_of_bound(addr);
}然后我们可以照猫画虎地,像itrace一样做一个mtrace的Kconfig的配置:
config MTRACE
depends on TRACE && TARGET_NATIVE_ELF && ENGINE_INTERPRETER
bool "Enable memory tracer"
default y
config MTRACE_COND
depends on MTRACE
string "Only trace memory when the condition is true"
default "true"然后测试一下NEMU自带的映像,会输出这样的内存访问踪迹:
0x80000000,4,r: 0x00000297
0x80000004,4,r: 0x00028823
0x80000010,1,w: 0x00000000
0x80000008,4,r: 0x0102c503
0x80000010,1,r: 0x00000000
0x8000000c,4,r: 0x00100073
消失的符号
原因是这些东西不会被add.c以外的文件所用到,所以也就不必出现在符号表中。
参考《Learning Linux Binary Analysis》书中对ELF符号的定义:
Symbols are a symbolic reference to some type of data or code such as a global variable or function.
而对于宏而言,它既不是变量也更不是函数,所以也不会出现在符号表中。
寻找”Hello World!”
写个简单Hello World之后,发现事情并不简单。利用上述方法,首先发现这个字符串放在了ELF文件的0x2000附近:
00002000 01 00 02 00 48 65 6c 6c 6f 20 57 6f 72 6c 64 21 |....Hello World!|
然后观察到,它实际上是在.rodata这个section里面。
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
...
[18] .rodata PROGBITS 0000000000002000 00002000
0000000000000011 0000000000000000 A 0 0 4
...
[29] .strtab STRTAB 0000000000000000 000033a0
00000000000001da 0000000000000000 0 0 1
猜测可能是因为字符串字面量属于是一种不可变的量,然后把它放在rodata里更合适。更重要的是,程序运行并不需要有.strtab,也就是说它都不用被载入到内存中去,如果Hello World被放在这.strtab里面那运行时都找不到了。
实现ftrace
实现ftrace的主要难点在于读明白man 5 elf,然后就会写了。
关于ELF文件的知识,教程里已经说的很详细了,不过要注意的是,在Section Headers里面识别出每个Section的名字当然是需要另一个特别给出的字符串表,即.shstrtab。它所在的section下标能在ELF的head里面找到。另外,由于ELF格式是跨平台的,为了include解析ELF文件内容所需要的elf.h,可以直接include host机上的elf.h。
我的ftrace实现策略如下:
- 在
parse_args中添加一个参数选项,允许放一个ELF文件的文件路径在那儿。 - 在程序运行前初始化ftrace,读入符号表识别其中的所有函数,把函数的地址信息、名字放到NEMU的一个线性表里。
- 阅读riscv32手册后,会知道
ra是放返回地址的寄存器。显然如果要函数返回的话,必须从ra读出值来,所以肯定是让jalr来做的。而函数调用则既可以用jal来小跳,也可以用jalr来大跳,具体可以参考伪指令call和ret。然后就在之前指令执行的地方稍微改改代码就可以了。 - 修改一下Kconfig等等内容,让它更加易用。
下面是我的实现:
INSTPAT("??????? ????? ????? ??? ????? 11011 11", jal , J,
R(rd) = s->snpc;
s->dnpc = imm + s->pc;
call_trace(s->pc, s->dnpc);
);
INSTPAT("??????? ????? ????? 000 ????? 11001 11", jalr , I,
R(rd) = s->snpc;
s->dnpc = (src1 + imm) & (~1);
if (rd == 0 && rs1 == 1)
return_trace(s->pc);
else
call_trace(s->pc, s->dnpc);
);#include <cpu/ftrace.h>
#include <elf.h>
#include <common.h>
#define TYPE_CALL true
#define TYPE_RETURN false
static Elf32_Off strtab_off;
static uint32_t strtab_size;
static Elf32_Off symtab_off;
static uint32_t symtab_size;
static uint16_t sh_off;
static uint16_t sh_size;
static uint16_t sh_num;
static size_t func_num = 0;
static int spaces = 0;
typedef struct Func_Info {
union {
char name[255];
uint32_t idx;
};
paddr_t addr;
paddr_t size;
} FI;
FI *finfo = NULL;
void init_ftrace(const char *elf_file) {
func_num = 0;
spaces = 0;
//use assert() to make sure elf_file is a valid elf file.
FILE *f = fopen(elf_file, "rb");
assert(f);
Elf32_Ehdr ehdr;
size_t fread_res = 0;
fread_res = fread(&ehdr, 1, sizeof(ehdr), f);
assert(fread_res);
assert(ehdr.e_ident[EI_MAG0] == ELFMAG0);
assert(ehdr.e_ident[EI_MAG1] == ELFMAG1);
assert(ehdr.e_ident[EI_MAG2] == ELFMAG2);
sh_off = ehdr.e_shoff;
sh_size = ehdr.e_shentsize;
sh_num = ehdr.e_shnum;
Elf32_Shdr shdr;
uint16_t shstrndx = ehdr.e_shstrndx;
fseek(f, sh_off + shstrndx * sizeof(shdr), SEEK_SET);
fread_res = fread(&shdr, 1, sizeof(shdr), f);
Elf32_Off shstrtab_off = shdr.sh_offset;
char buf[255];
for (int i = 0; i < sh_num; i++) {
fseek(f, sh_off + i * sizeof(shdr), SEEK_SET);
fread_res = fread(&shdr, 1, sizeof(shdr), f);
assert(fread_res);
if (shdr.sh_type == SHT_SYMTAB) {
symtab_off = shdr.sh_offset;
symtab_size = shdr.sh_size;
}
else if (shdr.sh_type == SHT_STRTAB) {
uint32_t name = shdr.sh_name;
fseek(f, shstrtab_off + name, SEEK_SET);
char *_ = fgets(buf, 255, f);
assert(_);
if (strcmp(buf, ".strtab") == 0) {
strtab_off = shdr.sh_offset;
strtab_size = shdr.sh_size;
}
}
}
Elf32_Sym stbl;
size_t sym_num = symtab_size / sizeof(stbl);
fseek(f, symtab_off, SEEK_SET);
for (size_t i = 0; i < sym_num; i++) {
fread_res = fread(&stbl, 1, sizeof(stbl), f);
assert(fread_res);
func_num += stbl.st_info == 18;
}
finfo = (FI *)malloc(sizeof(FI) * func_num);
fseek(f, symtab_off, SEEK_SET);
size_t idx = 0;
for (size_t i = 0; i < sym_num; i++) {
fread_res = fread(&stbl, 1, sizeof(stbl), f);
assert(fread_res);
if (stbl.st_info != 18)
continue;
finfo[idx].addr = stbl.st_value;
finfo[idx].size = stbl.st_size;
finfo[idx++].idx = stbl.st_name;
}
char *_ = NULL;
for (size_t i = 0; i < func_num; i++) {
fseek(f, strtab_off + finfo[i].idx, SEEK_SET);
_ = fgets(finfo[i].name, 255, f);
assert(_);
}
fclose(f);
}
__attribute__((unused)) static void print_trace(vaddr_t inst_addr, size_t func_idx, bool type) {
/*
printf(FMT_WORD ": " , inst_addr);
for (int j = 0; j < spaces; j++)
printf(" ");
if (type)
printf("call ");
else
printf("ret ");
printf("[%s@" FMT_WORD "]\n", finfo[func_idx].name, finfo[func_idx].addr);
*/
#ifdef CONFIG_FTRACE
if (FTRACE_COND) {
log_write(FMT_WORD ": ", inst_addr);
for (int j = 0; j < spaces; j++)
log_write(" ");
if (type)
log_write("call ");
else
log_write("ret ");
log_write("[%s@" FMT_WORD "]\n", finfo[func_idx].name, finfo[func_idx].addr);
}
#endif
}
void call_trace(vaddr_t inst_addr, vaddr_t pc) {
#ifdef CONFIG_FTRACE
for (size_t i = 0; i < func_num; i++) {
if (pc == finfo[i].addr) {
print_trace(inst_addr, i, TYPE_CALL);
spaces += 2;
break;
}
}
#endif
}
void return_trace(vaddr_t inst_addr) {
#ifdef CONFIG_FTRACE
for (size_t i = 0; i < func_num; i++) {
if (inst_addr >= finfo[i].addr &&
inst_addr < finfo[i].addr + finfo[i].size) {
spaces -= 2;
print_trace(inst_addr, i, TYPE_RETURN);
break;
}
}
#endif
}其他的诸如修改Kconfig、改NEMU参数传入的事情就和之前的差不多,这里就不过多赘述。
这是跑cpu-tests/tests/string.c的一个ftrace的输出案例:
0x8000000c: call [_trm_init@0x8000012c]
0x8000013c: call [main@0x80000028]
0x80000044: call [strcmp@0x800001ec]
0x80000214: ret [strcmp@0x800001ec]
0x8000004c: call [check@0x80000010]
0x80000014: ret [check@0x80000010]
0x80000058: call [strcmp@0x800001ec]
0x80000214: ret [strcmp@0x800001ec]
0x80000060: call [check@0x80000010]
0x80000014: ret [check@0x80000010]
0x80000074: call [strcmp@0x800001ec]
0x80000214: ret [strcmp@0x800001ec]
0x8000007c: call [check@0x80000010]
0x80000014: ret [check@0x80000010]
0x80000090: call [strcmp@0x800001ec]
0x80000214: ret [strcmp@0x800001ec]
0x80000098: call [check@0x80000010]
0x80000014: ret [check@0x80000010]
0x800000ac: call [strcmp@0x800001ec]
0x80000214: ret [strcmp@0x800001ec]
0x800000b4: call [check@0x80000010]
0x80000014: ret [check@0x80000010]
0x800000c8: call [strcpy@0x8000014c]
0x80000178: ret [strcpy@0x8000014c]
0x800000d0: call [strcat@0x80000188]
0x800001dc: ret [strcat@0x80000188]
0x800000d8: call [strcmp@0x800001ec]
0x80000214: ret [strcmp@0x800001ec]
0x800000e0: call [check@0x80000010]
0x80000014: ret [check@0x80000010]
0x800000f4: call [memset@0x80000218]
0x80000234: ret [memset@0x80000218]
0x80000100: call [memcmp@0x80000238]
0x80000270: ret [memcmp@0x80000238]
0x80000108: call [check@0x80000010]
0x80000014: ret [check@0x80000010]
0x8000011c: ret [main@0x80000028]
这里的_trm_init函数没有返回很正常,因为根据$AM_HOME/am/src/platform/nemu/trm.c,它跑完main函数的东西就直接进了个halt函数,这个函数直接触发NEMU_TRAP了,也就是直接一个ebreak指令,然后机器就停机了,所以那肯定没有返回。
不匹配的函数调用和返回
由于编译器不同,我的函数调用踪迹略显不同,但是仍然具有代表性:
0x8000000c: call [_trm_init@0x80000258]
0x80000268: call [main@0x800001cc]
0x800001ec: call [f0@0x80000010]
0x80000050: call [f3@0x80000108]
0x8000016c: call [f2@0x800000a4]
0x800000f0: call [f1@0x8000005c]
0x80000098: call [f0@0x80000010]
0x80000050: call [f3@0x80000108]
0x8000016c: call [f2@0x800000a4]
0x800000f0: call [f1@0x8000005c]
0x80000098: call [f0@0x80000010]
0x80000050: call [f3@0x80000108]
0x8000016c: call [f2@0x800000a4]
0x800000f0: call [f1@0x8000005c]
0x80000098: call [f0@0x80000010]
0x80000050: call [f3@0x80000108]
0x8000016c: call [f2@0x800000a4]
0x800000f0: call [f1@0x8000005c]
0x80000098: call [f0@0x80000010]
0x80000050: call [f3@0x80000108]
0x8000016c: call [f2@0x800000a4]
0x800000f0: call [f1@0x8000005c]
0x80000098: call [f0@0x80000010]
0x80000058: ret [f0@0x80000010]
0x80000100: ret [f2@0x800000a4]//注释
比如这里的注释处的call和ret并不匹配,正好出现在f0作为一个叶子函数被f1调用的时候。
为了更好的理解这一行为,我们可以对照地看一下f1的C语言实现和反汇编:
8000005c <f1>:
8000005c: 00000797 auipc a5,0x0
80000060: 27878793 addi a5,a5,632 # 800002d4 <lvl>
80000064: 0007a703 lw a4,0(a5)
80000068: 00b75463 bge a4,a1,80000070 <f1+0x14>
8000006c: 00b7a023 sw a1,0(a5)
80000070: 00000717 auipc a4,0x0
80000074: 26870713 addi a4,a4,616 # 800002d8 <rec>
80000078: 00072783 lw a5,0(a4)
8000007c: 00178793 addi a5,a5,1
80000080: 00f72023 sw a5,0(a4)
80000084: 00a05c63 blez a0,8000009c <f1+0x40>
80000088: 00158593 addi a1,a1,1
8000008c: fff50513 addi a0,a0,-1
80000090: 00000797 auipc a5,0x0
80000094: 2347a783 lw a5,564(a5) # 800002c4 <func>
80000098: 00078067 jr a5
8000009c: 00100513 li a0,1
800000a0: 00008067 retint f1(int n, int l) {
if (l > lvl) lvl = l;
rec ++;
return n <= 0 ? 1 : func[0](n - 1, l + 1);
};然后我们设想一下,已知这个f1函数一定是另一个函数(比如f2)调用的,然后假设f1里面参数n被传入的是一个1,那么f1又调用了f0函数,那么就一定会有f0的返回值被返回给f1,然后f1又将它原封不动地返回给了f2。所以,如果你是编译器,为什么不直接把f0的返回值直接给f2呢?
于是,编译器就是这么做的:f1在调用f0采取的是jr伪指令,其实就是jalr x0, 0(rs1),这就意味着他不会把f1的返回地址保存到ra寄存器里,而是让ra寄存器仍然保存的是f2处的返回地址,这样,当f0返回时,就会直接返回到f2了,能够提升一些效率。
冗余的符号表
经过试验,hello程序可以运行。很显然,符号表里面存储的ELF符号信息对于程序的执行并没有什么作用。而且从ELF文件的Program Headers里面并不需要加载这些符号信息到内存中去也证实了这一点。
用缺失了符号表的hello.o去尝试链接自然是不行的,例如一个程序要从_start开始,这个外部的_start要去调用hello.o里的main,结果在符号表里根本找不到main,就直接链接不上了。
trace与性能优化
暂时还没给我的NEMU做过任何优化,跑个马里奥都卡卡的。
如何生成native的可执行文件
之前的解耦的架构起了效果,现在可以试着把AM里的软件先在native上调对再来运行!不过为了弄懂native,还是看看Makefile比较好。
接上文的AM中的程序是如何构建的,为数不多的区别就在于,$AM_HOME/Makefile里include的是$AM_HOME/scripts/native.mk,并且所用的工具链都是本机的原生工具链,没有进行交叉编译。
奇怪的错误码
对于为什么错误码是1,我们可以先假设一下check失败。所以我们可以看一下check函数的native实现:
__attribute__((noinline)) void check(bool cond)
{
if (!cond)
halt(1);
}这里会调用TRM的halt,参数为1。而native里面TRM是这样实现的halt:
void halt(int code)
{
const char *fmt = "Exit code = 40h\n";
for (const char *p = fmt; *p; p++)
{
char ch = *p;
if (ch == '0' || ch == '4')
{
ch = "0123456789abcdef"[(code >> (ch - '0')) & 0xf];
}
putch(ch);
}
__am_exit_platform(code);
putstr("Should not reach here!\n");
while (1)
;
}这里有关输出退出码信息到串口上的方式感觉非常炫技,挺有意思。不过更重要的是在__am_exit_platform中干了调用了exit(code),因此这个运行在Linux上的native程序的退出码是1。
对于make程序如何得到这个错误码,我认为应该是因为make程序作为父进程,可以读它的子进程(运行在native上的软件)结束后的PCB所记录的退出码。在这里我用系统调用踪迹证实了这一点。
这是我的检查步骤:
- 我略微修改了
$AM_HOME/tests/cpu-tests/tests/add.c,让它一定会check失败。 - 我把
$AM_HOME/tests/cpu-tests/Makefile中删除掉了“删除生成的Makefile.add的命令” - 利用strace进行追踪,并用nvim看内容。具体而言是
strace -f make -s -f Makefile.add ARCH=native run &| nvim -这条命令
下面就是strace的输出内容了:
...
clone3({flags=CLONE_VM|CLONE_VFORK|CLONE_CLEAR_SIGHAND, exit_signal=SIGCHLD, stack=0x7babf327c000, stack_size=0x9000}, 88strace: Process 342900 attached
<unfinished ...>
[pid 342900] rt_sigprocmask(SIG_BLOCK, NULL, ~[KILL STOP], 8) = 0
[pid 342900] getuid() = 1000
[pid 342900] setresuid(-1, 1000, -1) = 0
[pid 342900] getgid() = 1000
[pid 342900] setresgid(-1, 1000, -1) = 0
[pid 342900] rt_sigprocmask(SIG_SETMASK, [], NULL, 8) = 0
[pid 342900] execve("/home/lijn/ics2024/am-kernels/tests/cpu-tests/build/add-native.elf", ["/home/lijn/ics2024/am-kernels/te"...], 0x5bab3011c4c0 /* 86 vars */ <unfinished ...>
...
[pid 342900] write(1, "E", 1E) = 1
[pid 342900] write(1, "x", 1x) = 1
[pid 342900] write(1, "i", 1i) = 1
[pid 342900] write(1, "t", 1t) = 1
[pid 342900] write(1, " ", 1 ) = 1
[pid 342900] write(1, "c", 1c) = 1
[pid 342900] write(1, "o", 1o) = 1
[pid 342900] write(1, "d", 1d) = 1
[pid 342900] write(1, "e", 1e) = 1
[pid 342900] write(1, " ", 1 ) = 1
[pid 342900] write(1, "=", 1=) = 1
[pid 342900] write(1, " ", 1 ) = 1
[pid 342900] write(1, "0", 10) = 1
[pid 342900] write(1, "1", 11) = 1
[pid 342900] write(1, "h", 1h) = 1
[pid 342900] write(1, "\n", 1) = 1
[pid 342900] exit_group(1) = ?
[pid 342900] +++ exited with 1 +++
<... wait4 resumed>[{WIFEXITED(s) && WEXITSTATUS(s) == 1}], 0, NULL) = 342900
write(2, "make: *** [/home/lijn/ics2024/ab"..., 82make: *** [/home/lijn/ics2024/abstract-machine/scripts/native.mk:21: run] Error 1
) = 82
rt_sigprocmask(SIG_BLOCK, [HUP INT QUIT TERM XCPU XFSZ], NULL, 8) = 0
rt_sigprocmask(SIG_UNBLOCK, [HUP INT QUIT TERM XCPU XFSZ], NULL, 8) = 0
chdir("/home/lijn/ics2024/am-kernels/tests/cpu-tests") = 0
close(1) = 0
exit_group(2) = ?
+++ exited with 2 +++显然pid为342900的进程就是跑的测试程序,也就是add-native.elf,而make程序用一个wait4系统调用去获取了它所clone3出来的进程的退出信息。由于退出码为1,所以make程序就这样输出出来了。
感觉这个问题多少有点超纲,我是做了清华大学的rCore-OS进而对操作系统有了更深入的了解之后才能够合理猜测出来的。
这是如何实现的?
注意到klib库的一些C源文件中有这么一些东西:
#if !defined(__ISA_NATIVE__) || defined(__NATIVE_USE_KLIB__)
...
#endif这就意味着,如果我们选择ARCH=native并且在klib.h中没有定义宏__NATIVE_USE_KLIB__,那么stdio.c里面的各个函数的定义不会被编译,自然,链接的时候是不会链接klib的。
而如果我们选择ARCH=native并且在klib.h中定义了宏__NATIVE_USE_KLIB__,情况就不一样了。这样stdio.c里面的各个函数的定义会被编译。
再看看Makefile里是如何链接的:
### Rule (link): objects (`*.o`) and libraries (`*.a`) -> `IMAGE.elf`, the final ELF binary to be packed into image (ld)
$(IMAGE).elf: $(LINKAGE) $(LDSCRIPTS)
@echo \# Creating image [$(ARCH)]
@echo + LD "->" $(IMAGE_REL).elf
ifneq ($(filter $(ARCH),native),)
$(CXX) -o $@ -Wl,--whole-archive $(LINKAGE) -Wl,-no-whole-archive $(LDFLAGS_CXX)
else
$(LD) $(LDFLAGS) -o $@ --start-group $(LINKAGE) --end-group
endif在高亮行中这些库都被显式地静态链接了,所以它们比glibc的优先级更高,因而klib中的函数会被优先链接上去。
之后打算读一读《程序员的自我修养》和《CS:APP》两本书,希望能对编译、链接这一块有更加深入的理解。
编写可移植的程序
用sizeof代替固定的指针大小。
编写更多的测试(2)
前面两个选做任务:编写更多的测试 和 这些库函数这么简单, 我可以不测试吗? 没什么好说的,但是我的klib-tests由于没置入git管理所以在误删后现在已经没了。
要得到只读函数的测试的预期输出,完全可以把自己写的测试在host机上先跑出来一个结果,再用check去检查。
编写更多的测试(3)
感觉这个才是最重要的,因为格式化输出还真有点难写。同样,预期输出的生成同上。
实现DiffTest
DiffTest的核心就在于每条指令步步执行并用另一个正确的实现来检查程序状态是否一致,这是一种检查硬件实现的好方法。比如上面srai指令实现的坑就是这样检查出来的。
为了解决这个选做题,那肯定要先找到检查寄存器的位置:
void difftest_step(vaddr_t pc, vaddr_t npc)
{
CPU_state ref_r;
if (skip_dut_nr_inst > 0)
{
ref_difftest_regcpy(&ref_r, DIFFTEST_TO_DUT);
if (ref_r.pc == npc)
{
skip_dut_nr_inst = 0;
checkregs(&ref_r, npc);
return;
}
skip_dut_nr_inst--;
if (skip_dut_nr_inst == 0)
panic("can not catch up with ref.pc = " FMT_WORD
" at pc = " FMT_WORD,
ref_r.pc, pc);
return;
}
if (is_skip_ref)
{
// to skip the checking of an instruction, just copy the reg state to
// reference design
ref_difftest_regcpy(&cpu, DIFFTEST_TO_REF);
is_skip_ref = false;
return;
}
ref_difftest_exec(1);
ref_difftest_regcpy(&ref_r, DIFFTEST_TO_DUT);
checkregs(&ref_r, pc);
}所以要想办法了解ref_difftest_regcpy的实现。看源码(init_difftest函数)能够得知这个函数是动态加载进来的,其在动态链接库里的名字是difftest_regcpy。
然后通过看$NEMU_HOME/script/native.mk、$NEMU_HOME/tools/difftest.mk可以知道加载的这个动态链接库是这样的:
DIFF_REF_SO = $(DIFF_REF_PATH)/build/$(GUEST_ISA)-$(call remove_quote,$(CONFIG_DIFFTEST_REF_NAME))-so对于我们的riscv32,默认就是$NEMU_HOME/tools/spike-diff/build/riscv32-spike-so。
所以在$NEMU_HOME/tools/spike-diff下面找函数difftest_regcpy就行了。
...
struct diff_context_t {
word_t gpr[MUXDEF(CONFIG_RVE, 16, 32)];
word_t pc;
};
...
static state_t *state = NULL;
...
void sim_t::diff_get_regs(void* diff_context)
{
struct diff_context_t* ctx = (struct diff_context_t*)diff_context;
for (int i = 0; i < NR_GPR; i++)
{
ctx->gpr[i] = state->XPR[i];
}
ctx->pc = state->pc;
}
...
__EXPORT void difftest_regcpy(void* dut, bool direction)
{
if (direction == DIFFTEST_TO_REF)
{
s->diff_set_regs(dut);
}
else
{
s->diff_get_regs(dut);
}
}
...然后再看看spike里面的寄存器实现:
struct state_t
{
void reset(processor_t* const proc, reg_t max_isa);
reg_t pc;
regfile_t<reg_t, NXPR, true> XPR;
regfile_t<freg_t, NFPR, false> FPR;
...template <class T, size_t N, bool zero_reg>
class regfile_t
{
public:
void write(size_t i, T value)
{
if (!zero_reg || i != 0)
data[i] = value;
}
const T& operator [] (size_t i) const
{
return data[i];
}
...发现spike里面就是第i个寄存器就对应XPR的第i个regfile_t,并且spike的difftest_context_t和NEMU的riscv32_CPU_state完全一致。所以教程里完全在唬人罢了
所以我们就这样简单地实现isa_difftest_checkregs即可:
bool isa_difftest_checkregs(CPU_state *ref_r, vaddr_t pc)
{
size_t reg_num = MUXDEF(CONFIG_RVE, 16, 32);
for (size_t i = 0; i < reg_num; i++)
{
if (gpr(i) != ref_r->gpr[i])
return false;
}
return true;
}匪夷所思的QEMU行为 (有点难度)
以后学学MIPS32后再看看这个问题吧。
捕捉死循环(有点难度)
发生死循环应该是有跳转、分支语句参与其中的,并且这些语句至少有一个是让PC往之前跳的。因此我们需要去分析PC从被跳到前面到这个跳转、分支语句之间的指令会始终让这个跳转、分支语句的判断条件为真,且让PC往之前跳。不过这好像有点困难。
网上查询原来这就是停机问题,已经证明了是不存在一个方法可以检测所有程序能不能停机的。不过对于特定程序还是可以判定的。
阶段3
输入输出
教程上说了很多,不过一句话总结就是:输入输出对于RISCV软件开发者还是挺简单的,只需要访问特定的内存地址就可以了;然而硬件工程师考虑的就有很多了。
不过有了输入输出后,软件的状态机模型也变得更加复杂了,在不同的输入面前,程序的状态是不确定的。
理解volatile关键字
之前已经略微理解了一些了呢~在这里我们用教程中给出的示例代码来验证一下:
这是有-O2,有volatile:
0000000000001180 <fun>:
1180: f3 0f 1e fa endbr64
1184: c6 05 8d 2e 00 00 00 movb $0x0,0x2e8d(%rip) # 4018 <_end>
118b: 48 8d 15 86 2e 00 00 lea 0x2e86(%rip),%rdx # 4018 <_end>
1192: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)
1198: 0f b6 02 movzbl (%rdx),%eax
119b: 3c ff cmp $0xff,%al
119d: 75 f9 jne 1198 <fun+0x18>
119f: c6 05 72 2e 00 00 33 movb $0x33,0x2e72(%rip) # 4018 <_end>
11a6: c6 05 6b 2e 00 00 34 movb $0x34,0x2e6b(%rip) # 4018 <_end>
11ad: c6 05 64 2e 00 00 86 movb $0x86,0x2e64(%rip) # 4018 <_end>
11b4: c3 ret这是有-O2,没有volatile:
0000000000001180 <fun>:
1180: f3 0f 1e fa endbr64
1184: c6 05 8d 2e 00 00 00 movb $0x0,0x2e8d(%rip) # 4018 <_end>
118b: eb fe jmp 118b <fun+0xb>因为没有volatile,所以在给*p赋值为0之后的while条件判断里读取*p直接被优化没了,直接当作死循环处理了。因为C编译器直接假定这个*p是不会变的。
所以这个volatile关键字在内存映射I/O中非常有用:因为从软件层面上看,我们读取IO设备是用读取内存的方式进行的。我们在读取它的时候从硬件角度来看它可能会变,但是从C编译器的角度上它就不会变,而volatile防止了C编译器这样的不合适的优化。
这里有个小问题:_end是什么。我们man 3 end一下就会知道了:
endThis is the first address past the end of the uninitialized data segment (also known as the BSS segment).
随便从一个编译出来的ELF文件中也可以看到,_end符号正好就是BSS段的末尾。
通过内存进行数据交互的输入输出
这里的意思是,普通的IO的数据流若是要读到内存中去,那么是必须走这么个流程:IO设备->CPU寄存器->内存,而有了DMA,则可以直接IO设备->内存。
运行Hello World
因为我选择的是riscv32所以很简单,不用实现新的指令。不过最好还是梳理一下如何输出的。我们先看看运行在裸机运行时环境的软件是什么样子的:首先在hello.c中调用了putch,这个putch调用了outb,实质上就是在串口设备对应的内存地址写入了一字节的一个字符。而这个事情会被编译器编译成这个东西:
8000008c <putch>:
8000008c: a00007b7 lui a5,0xa0000
80000090: 3ea78c23 sb a0,1016(a5) # a00003f8 <_end+0x1fff73f8>
80000094: 00008067 ret其实就是一个sb存字节指令。然后视角转到NEMU,NEMU在执行这一条指令的时候,按照该指令的语义,是肯定要调用vaddr_write这个函数的,接着就是调用paddr_write,发现这个地址是对应于设备地址的,所以会调用mmio_write这个函数,在通过地址找到对应的IOMap后,会触发之前注册好的回调函数,在这里也就是触发serial_io_handler。
void map_write(paddr_t addr, int len, word_t data, IOMap *map)
{
assert(len >= 1 && len <= 8);
check_bound(map, addr);
paddr_t offset = addr - map->low;
host_write(map->space + offset, len, data);
invoke_callback(map->callback, offset, len, true);
#ifdef CONFIG_DTRACE
if (DTRACE_COND)
{
log_write("%s," FMT_WORD ",%d,w: " FMT_WORD "\n", map->name, addr, len,
data);
}
#endif
}void init_serial()
{
serial_base = new_space(8);
#ifdef CONFIG_HAS_PORT_IO
add_pio_map("serial", CONFIG_SERIAL_PORT, serial_base, 8,
serial_io_handler);
#else
add_mmio_map("serial", CONFIG_SERIAL_MMIO, serial_base, 8,
serial_io_handler);
#endif
}理解mainargs
对于$ISA-nemu而言,首先应该看看Makefile程序:
MAINARGS_MAX_LEN = 64
MAINARGS_PLACEHOLDER = The insert-arg rule in Makefile will insert mainargs here.
CFLAGS += -DMAINARGS_MAX_LEN=$(MAINARGS_MAX_LEN) -DMAINARGS_PLACEHOLDER=\""$(MAINARGS_PLACEHOLDER)"\"
insert-arg: image
@python $(AM_HOME)/tools/insert-arg.py $(IMAGE).bin $(MAINARGS_MAX_LEN) "$(MAINARGS_PLACEHOLDER)" "$(mainargs)"这个Makefile程序的CFLAGS里定义的宏在这个C源文件会起作用:
...
static const char mainargs[MAINARGS_MAX_LEN] = MAINARGS_PLACEHOLDER; // defined in CFLAGS
...
void _trm_init() {
int ret = main(mainargs);
halt(ret);
}所以说,在编译的时候会有一个占位的The insert-arg rule in Makefile will insert mainargs here.字符串作为mainargs,这个mainargs未来会被传送到main函数的参数中。
然后在NEMU上运行这个程序之前,会在insert-arg目标中用一个Python程序去插入真正的mainargs,插入的方式也很简单,首先在ELF文件中找到这个占位的字符串,然后用真正的mainargs连同后面补位的\0去替代之前占位的字符串就好了。这样一来就成功插入了mainargs。不过我觉得这样做不是很好,因为有极小的可能性,这个ELF文件里存在另外一块数据,它的二进制表达形式和这个占位的字符串的UTF-8码一样,而且它还在这个占位的字符串前面就会坏事了,可能会导致替换错误。
而对于native,似乎很浅显,它把mainargs放在环境变量里,然后读取它:
const char *args = getenv("mainargs");
halt(main(args ? args : "")); // call main here!而mainargs是怎么被放进环境变量的就很有意思了。我们先追踪一下make过程中的系统调用execve的环境变量,即strace -f -e trace=execve -s 65535 -v make ARCH=native mainargs=114514 run &| nvim -,发现是第一次递归调用Make之后,才在环境变量中第一次出现了mainargs。对应的Make程序就是这个:
### Rule (recursive make): build a dependent library (am, klib, ...)
$(LIBS): %:
@$(MAKE) -s -C $(AM_HOME)/$* archive关于为什么递归调用会在环境变量中出现之前的Makefile变量,可以看这篇文章。
会写Makefile的人真是神仙。
实现printf
printf和sprintf之间唯一的区别就在于,sprintf把输出的每一个字符输出到了dst所在的内存中,而printf把输出的每一个字符输出到了串口所对应的内存地址。因此,只是输出的地方不一样,其他都一样。因此可以把之前的字符串分析部分包装成一个函数,然后用不同的函数指针表示不同的输出即可,就像下面这样。
static void putchar_to_serial(const char ch, int *tot, char **) {
putch(ch);
(*tot)++;
}
static void putchar_to_c_str(const char ch, int *tot, char **out) {
*((*out)++) = ch;
(*tot)++;
}
...
static void analyze_fmtch(const char* fmt, size_t *i, int *tot, void (*out_func)(const char, int *, char **), char **out, va_list *args);运行alu-tests
编译得似乎真的很慢。。。
实现IOE
为了实现AM_TIMER_UPTIME,可以在开机的时候先从NEMU获取时间,然后在每次想要获取AM系统启动时间的时候用获取的时间减去开机时获取的时间即可。
那么先看一下NEMU中计时器的硬件实现:
static void rtc_io_handler(uint32_t offset, int len, bool is_write)
{
assert(offset == 0 || offset == 4);
if (!is_write && offset == 4)
{
uint64_t us = get_time();
rtc_port_base[0] = (uint32_t)us;
rtc_port_base[1] = us >> 32;
}
}当读取的offset是4的时候,会把获取的微秒数放到rtc_port_base数组里,然后会在map_read中被读入。所以在我们的驱动程序中,应当先读取offset=4,更新rtc_port_base,得到微秒数的高32位,然后读取offset=0,这不会更新rtc_port_base,得到微秒数的低32位。最后把它们组合起来,放到uptime里面。
这些诸如AM_TIMER_UPTIME_T的结构体,在$AM_HOME/am/include/amdev.h里面定义的。
所以我是这样实现的:
uint64_t boot_time = 0;
void __am_timer_init()
{
boot_time += inl(RTC_ADDR + 4);
boot_time <<= 32;
boot_time += inl(RTC_ADDR);
}
void __am_timer_uptime(AM_TIMER_UPTIME_T *uptime)
{
uptime->us = 0;
uptime->us += inl(RTC_ADDR + 4);
uptime->us <<= 32;
uptime->us += inl(RTC_ADDR);
uptime->us -= boot_time;
}RTFSC尽可能了解一切细节
看一眼am-kernels/tests/am-tests/src/main.c就可以,就是mainargs传个t就可以,所以就在am-kernels/tests/am-tests/执行一下下面这个就可以。
make ARCH=riscv32-nemu mainargs=t run看看NEMU跑多快
执行这行代码进行一个microbench的评测:
make ARCH=riscv32-nemu mainargs=ref run我的机器是AMD Ryzen 7 8745H,在ARCH=native下获得分数109109分,在ARCH=riscv32-nemu下获得分数510分。
然后试了试coremark评测,我在ARCH=native下获得分数116856分,在ARCH=riscv32-nemu下获得分数393分。
最后是dhrystone评测,在ARCH=native下获得分数80081分,在ARCH=riscv32-nemu下获得分数153分。感谢这个dhrystone评测,因为我由此发现了我的slti指令的实现有问题。
RTFSC了解一切细节
在NEMU硬件实现中,只有读取offset=4才会更新计时器。如果你先读取offset=0,再读取offset=4,那么就会导致一开始读的是计时器的旧时间,而之后读的是计时器的新时间,这就会导致读取的时间有误。
NEMU和语言解释器
不是很感兴趣,所以没看。
运行演示程序
首先需要实现一个简单的malloc和free函数:按照教程里的说法就是,只管申请,别管释放了。这虽然很粗暴,但是确实很有效。在查阅手册后,需要注意malloc的返回值需要对齐,原文如下:
The malloc(), calloc(), realloc(), and reallocarray() functions return a pointer to the allocated memory, which is suitably aligned for any type that fits into the requested size or less. On error, these func‐ tions return NULL and set errno. Attempting to allocate more than PTRDIFF_MAX bytes is considered an error, as an object that large could cause later pointer subtraction to overflow.
所以我们可以这样实现:
void *addr = NULL;
void *malloc(size_t size)
{
// On native, malloc() will be called during initializaion of C runtime.
// Therefore do not call panic() here, else it will yield a dead recursion:
// panic() -> putchar() -> (glibc) -> malloc() -> panic()
if (!addr)
addr = heap.start;
void *ret = addr;
if ((uintptr_t)ret % size != 0)
{
ret -= (uintptr_t)ret % size;
ret += size;
}
uint8_t *new_addr = ret;
new_addr += size;
addr = new_addr;
return ret;
#if !(defined(__ISA_NATIVE__) && defined(__NATIVE_USE_KLIB__))
panic("Not implemented");
#endif
return NULL;
}
void free(void *ptr)
{
}截取一个高尔顿钉板的运行图示:
观看”Bad Apple!!” PV
豪堪!

运行红白机模拟器
豪玩!
native和klib
从Makefile里面可以看到,链接出native所需的ELF时,动态链接上了SDL的库。
LDFLAGS_CXX = $(addprefix -Wl$(comma), $(LDFLAGS)) -pie -ldl $(shell sdl2-config --libs)在我这台机器上,这个库对应的文件就是/usr/lib/x86_64-linux-gnu/libSDL2-2.0.so.0.3000.0,用ldd libSDL2-2.0.so.0.3000.0,看一下,发现有对libc.so.6的依赖,这似乎就链接上glibc了。
但这好像是和教程中说的有点不符合,毕竟应该是一个小技巧才对。然后我注意到了这个:
// save the address of memcpy() in glibc, since it may be linked with klib
memcpy_libc = dlsym(RTLD_NEXT, "memcpy");
assert(memcpy_libc != NULL);dlsym就是获取一个符号在动态链接库或者可执行文件里的地址,这没啥好说的。但是RTLD_NEXT挺有意思,它的解释如下:
Find the next occurrence of the desired symbol in the search order after the current object. This allows one to provide a wrapper around a function in another shared object, so that, for example, the definition of a function in a preloaded shared object (see LD_PRELOAD in ld.so(8)) can find and invoke the “real” function provided in another shared object (or for that matter, the “next” definition of the function in cases where there are multiple layers of preloading).
其中提到:它会去找下一个有这个符号的这个object。在之前阅读的Makefile里可以知道,像am、klib等等都被静态链接进了这个ELF文件,在klib中是有memcpy的定义,不过这是当前的object,因此要找下一个object,就会去找glibc中的memcpy了。
实现dtrace
非常简单,这里不多做赘述。就在map_read和map_write里面加点日志操作就行了。
实现IOE(2)
首先还是看一下键盘的硬件实现。在每次执行完一个指令后会更新设备,进而利用SDL库把当前按下或松开的按键放在一个循环队列里。然后每次读入就会从这个循环队列里弹出来一个。
具体在循环队列里存放的元素的信息,则是这样子的:
#define KEYDOWN_MASK 0x8000
void send_key(uint8_t scancode, bool is_keydown)
{
if (nemu_state.state == NEMU_RUNNING && keymap[scancode] != NEMU_KEY_NONE)
{
uint32_t am_scancode =
keymap[scancode] | (is_keydown ? KEYDOWN_MASK : 0);
key_enqueue(am_scancode);
}
}这个keymap[scancode]的值通过RTF宏可以知道就是SDL2里面的各个按键的scancode,通过查阅SDL手册,了解到这些scancode最多只占三个16进制位,而KEYDOWN_MASK是0x8000,所以一定不会在编码上产生冲突。
所以我们的驱动程序可以这样子编写:
void __am_input_keybrd(AM_INPUT_KEYBRD_T *kbd)
{
uint32_t data = inl(KBD_ADDR);
kbd->keydown = (data & KEYDOWN_MASK);
kbd->keycode = (data & (~KEYDOWN_MASK));
}如何检测多个键同时被按下?
因为键盘码指明了这个键被是按下还是松开,所以可以在得到按下键的时候把这个键放入集合中,在松开时从集合中去除这个键。那么这样的集合就代表着同时按下的键。
运行红白机模拟器(2)
能玩,就是字符画有点抽象。
神奇的调色板
我猜测是使用了多个调色盘,用不同的调色盘代表颜色的深浅,然后在做渐入渐出效果的时候只是更改了调色盘,而存入到像素中的调色盘的下标并不变化。
实现IOE(3)
实现IOE(4)
这两个任务我是一块做的。
AM_GPU_CONFIG的实现很简单,因为硬件已经完全实现好了,软件上面读取一下VGACTL_ADDR就行了。注意的是硬件上要注意vgactl_port_base[0]是表示屏幕长宽的只读数据,而vgactl_port_base[1]是表示是否立刻同步的只写数据:
static void vga_ctl_io_handler(uint32_t offset, int len, bool is_write)
{
if (offset == 0)
{
assert(len == 4);
assert(!is_write);
}
else if (offset == 4)
{
assert(len == 4);
assert(is_write);
if (vgactl_port_base[1])
vga_update_screen();
vgactl_port_base[1] = 0;
}
else
{
panic("do not support offset = %d", offset);
}
}然后是实现AM_GPU_FBDRAW。在硬件上其实完成一个同步操作即可,但是软件上面就需要把屏幕当作二维数组把数据填写进去,然后指定是否需要同步:
void __am_gpu_fbdraw(AM_GPU_FBDRAW_T *ctl)
{
uint32_t *fb = (uint32_t *)(uintptr_t)FB_ADDR;
uint32_t *pixels = (uint32_t *)ctl->pixels;
for (int j = 0; j < ctl->h; j++)
{
for (int i = 0; i < ctl->w; i++)
{
int col = ctl->x + i;
int row = ctl->y + j;
fb[row * width + col] = pixels[j * ctl->w + i];
}
}
if (ctl->sync)
{
outl(SYNC_ADDR, 1);
}
}效果如图:

运行演示程序(2)
豪堪。
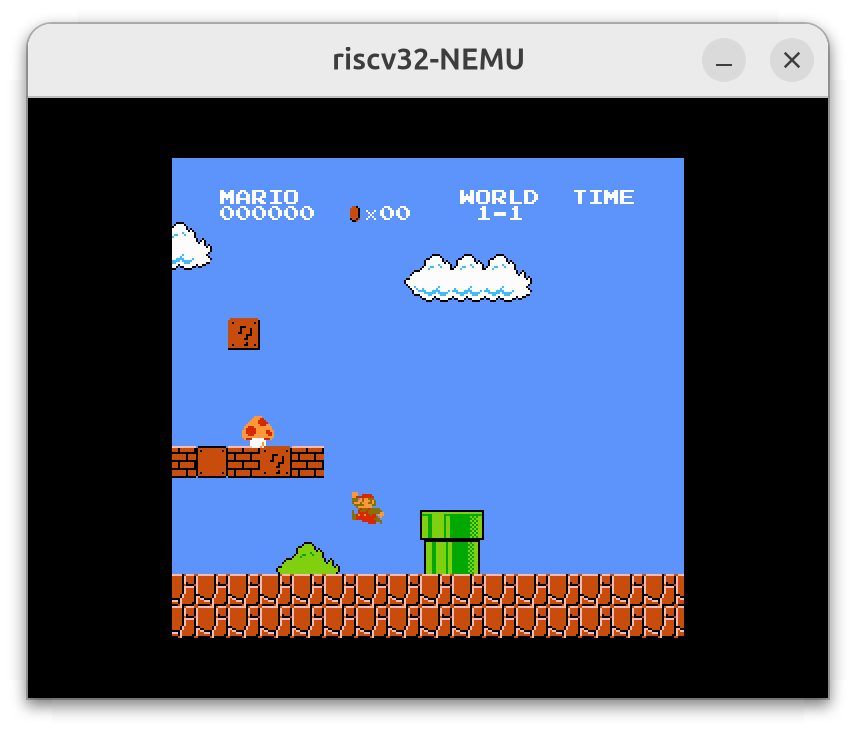
运行红白机模拟器(3)
卡成几秒钟一帧,近乎不能玩😭。毕竟相当于是套了两层虚拟机,性能着实糟糕。
实现声卡
这个任务有点困难。首先我们要在NEMU中用SDL2库去实现音频,实现的方式需要STFW,我这里采用的是回调函数实现的。
具体来说,我在init_sound里面注册了SDL2的回调函数sound_callback,这个回调函数内部会从我的缓冲区中读入音频数据,然后写到SDL2的流里面去。而对于软件写进来的音频数据,我在audio_buf_io_handler中维护了缓冲区的数据区间。注意我的实现中缓冲区并非是环形队列。
而音频方面的配置则由audio_ctl_io_handler处理,这里的sbuf_size和count还是很重要的,是用来告诉软件能写入多少音频数据的。
#include <common.h>
#include <device/map.h>
#include <SDL2/SDL.h>
enum
{
reg_freq,
reg_channels,
reg_samples,
reg_sbuf_size,
reg_init,
reg_count,
nr_reg
};
static uint8_t *sbuf = NULL;
static int buf_l = 0, buf_r = 0;
static uint32_t *audio_base = NULL;
static int buf_use()
{
return buf_r - buf_l;
}
int min(int x, int y)
{
return ((x < y) ? x : y);
}
static void sound_callback(void *userdata, Uint8 *stream, int len)
{
SDL_memset(stream, 0, len);
len = min(len, buf_use());
SDL_MixAudio(stream, sbuf + buf_l, len, SDL_MIX_MAXVOLUME);
buf_l = buf_l + len;
if (buf_l == buf_r)
buf_l = buf_r = 0;
}
static SDL_AudioSpec audio_spec = {.format = AUDIO_S16SYS,
.userdata = NULL,
.silence = 0,
.padding = 0,
.size = CONFIG_SB_SIZE,
.callback = sound_callback};
static void init_sound()
{
SDL_Init(SDL_INIT_AUDIO);
SDL_OpenAudio(&audio_spec, NULL);
SDL_PauseAudio(0);
}
static void audio_ctl_io_handler(uint32_t offset, int len, bool is_write)
{
assert(len == 4);
switch (offset / 4)
{
case reg_freq:
assert(is_write);
audio_spec.freq = audio_base[reg_freq];
break;
case reg_channels:
assert(is_write);
audio_spec.channels = audio_base[reg_channels];
break;
case reg_samples:
assert(is_write);
audio_spec.samples = audio_base[reg_samples];
break;
case reg_init:
assert(is_write);
if (audio_base[reg_init])
init_sound();
audio_base[reg_init] = 0;
break;
case reg_sbuf_size:
assert(!is_write);
break;
case reg_count:
assert(!is_write);
audio_base[reg_count] = buf_r;
break;
default:
panic("do not support offset: %d", offset);
}
}
static void audio_buf_io_handler(uint32_t offset, int len, bool is_write)
{
assert(is_write);
buf_r = buf_r + len;
}
void init_audio()
{
uint32_t space_size = sizeof(uint32_t) * nr_reg;
audio_base = (uint32_t *)new_space(space_size);
audio_base[reg_sbuf_size] = CONFIG_SB_SIZE;
audio_base[reg_init] = 0;
audio_base[reg_count] = 0;
#ifdef CONFIG_HAS_PORT_IO
add_pio_map("audio", CONFIG_AUDIO_CTL_PORT, audio_base, space_size,
audio_ctl_io_handler);
#else
add_mmio_map("audio", CONFIG_AUDIO_CTL_MMIO, audio_base, space_size,
audio_ctl_io_handler);
#endif
sbuf = (uint8_t *)new_space(CONFIG_SB_SIZE);
add_mmio_map("audio-sbuf", CONFIG_SB_ADDR, sbuf, CONFIG_SB_SIZE,
audio_buf_io_handler);
}下面是软件上的实现,其写入音频数据的方式简要叙述就是:计算需要写入的大小和缓冲区中的空闲大小,然后把不超过缓冲区空闲大小的数据写入,反复如此,便能把所有数据全部写进去。不过这可能会有一些并发问题。
#include <am.h>
#include <nemu.h>
#define AUDIO_FREQ_ADDR (AUDIO_ADDR + 0x00)
#define AUDIO_CHANNELS_ADDR (AUDIO_ADDR + 0x04)
#define AUDIO_SAMPLES_ADDR (AUDIO_ADDR + 0x08)
#define AUDIO_SBUF_SIZE_ADDR (AUDIO_ADDR + 0x0c)
#define AUDIO_INIT_ADDR (AUDIO_ADDR + 0x10)
#define AUDIO_COUNT_ADDR (AUDIO_ADDR + 0x14)
size_t bufsize;
void __am_audio_init()
{
bufsize = inl(AUDIO_SBUF_SIZE_ADDR);
}
void __am_audio_config(AM_AUDIO_CONFIG_T *cfg)
{
cfg->present = true;
cfg->bufsize = inl(AUDIO_SBUF_SIZE_ADDR);
}
void __am_audio_ctrl(AM_AUDIO_CTRL_T *ctrl)
{
outl(AUDIO_FREQ_ADDR, ctrl->freq);
outl(AUDIO_CHANNELS_ADDR, ctrl->channels);
outl(AUDIO_SAMPLES_ADDR, ctrl->samples);
outl(AUDIO_INIT_ADDR, 1);
}
void __am_audio_status(AM_AUDIO_STATUS_T *stat)
{
stat->count = inl(AUDIO_COUNT_ADDR);
}
void __am_audio_play(AM_AUDIO_PLAY_T *ctl)
{
AM_AUDIO_STATUS_T stt;
__am_audio_status(&stt);
uint8_t *dst = (uint8_t *)(uintptr_t)AUDIO_SBUF_ADDR + stt.count;
uint8_t *dst_end = (uint8_t *)(uintptr_t)AUDIO_SBUF_ADDR + bufsize;
uint8_t *src_beg = (uint8_t *)ctl->buf.start;
uint8_t *src_end = (uint8_t *)ctl->buf.end;
size_t need = src_end - src_beg;
size_t provide = bufsize - stt.count;
while (need > provide)
{
while (dst != dst_end)
{
*(dst++) = *(src_beg++);
}
__am_audio_status(&stt);
dst = (uint8_t *)(uintptr_t)AUDIO_SBUF_ADDR + stt.count;
provide = bufsize - stt.count;
need = src_end - src_beg;
}
while (src_beg != src_end)
{
*(dst++) = *(src_beg++);
}
}音频播放的原理
经过试验发现:
channels调得越大播放得更快,声音更尖锐。freq调得越大也是播放得更快,声音更尖锐。samples没听出来有什么区别
播放自己的音乐
之后自己再试试。
观看”Bad Apple!!” PV(2)
声音比较正常,虽然有点杂音。
消除播放音频时的杂音
这个之后再做吧。
运行红白机模拟器(4)
真的好卡啊。
展示你的计算机系统
这是slider程序的截图

游戏是如何运行的
从静态视角而言,游戏会在这里访问键盘设备进而得到输入,并检测从代码逻辑上是否命中。这个io_read本质上是访问一个设备寄存器,进而调用我之前实现的键盘设备驱动,进而访问特定的内存地址。然后这会被编译成一个读内存的指令。在NEMU上运行时遇到这个指令将会进行一个访存,然后发现地址对应着的是键盘设备,于是调用了键盘设备的回调函数,得到了具体的键盘事件。
while (1)
{
AM_INPUT_KEYBRD_T ev = io_read(AM_INPUT_KEYBRD);
if (ev.keycode == AM_KEY_NONE)
break;
if (ev.keydown && ev.keycode == AM_KEY_ESCAPE)
halt(0);
if (ev.keydown && lut[ev.keycode])
{
check_hit(lut[ev.keycode]);
}
};这里就会更新chars数组的数据,然后在下面的render函数中就会访问VGA设备把具体的画面输出出去。
不过从动态视角,比如dtrace,就会发现游戏中大部分时间都在空转,也就是读的键盘输入是没有,并且由于计算速度较快,而帧数并不高(30帧),往往game_logic_update并不是经常被调用,而ftrace也可以印证这一点。
需要注意的是,要在Kconfig中把When tracing is disabled (unit: number of instructions)设置成一个较大的值,不然trace会提前结束。
体会到AM的好处了吧?
以后再说,我并不是南京大学的学生😭,现在不是,以后估计也不会是。
LiteNES如何工作?
优化LiteNES
关于LiteNES的内容,以后再说吧。
在NEMU上运行NEMU
这实际上有点复杂,因为如果把NEMU当作一个运行在NEMU上的程序,那它所处于的环境就是AM的裸机运行时环境,因此还需要添加一些库函数等等才可以成功运行。
我这里并没有成功让NEMU运行在NEMU上,不过我尝试着RTFSC解决这个问题,以读取按键举个例子,访问过程如下:typing-game调用io_read->访问内层NEMU的AM的IOE驱动->通过访存指令访问内层的NEMU的硬件实现(由于内层NEMU是跑在外层NEMU的AM上的,所以这个硬件实现调用的是io_read)->外层NEMU的AM的IOE驱动->通过访存指令访问外层NEMU的硬件实现(利用SDL2库实现)-> 本机的Linux环境
实验报告
编译与链接1
经过实验,分别去掉static、inline都可以编译成功,而都去掉后不会编译成功。
都去掉后编译失败的原因是,这个函数所在的cpu/ifetch.h被hostcall.c和inst.cinclude了,被编译后在hostcall.o和inst.o里的inst_fetch都是强符号,因此会导致符号重复定义,使得链接失败。
而单独留下static的时候,编译出来的hostcall.o和inst.o里的inst_fetch在符号表中会看到,其Bind属性为LOCAL,是不会发生冲突的。
单独留下inline的时候,编译出来的hostcall.o和inst.o里根本不存在inst_fetch这个符号,甚至连函数都没有,因为它被优化得插入到被“调用”的地方了,所以也不会造成冲突。实际上根据C99手册中所说,inline并不一定inline,但是这样的一个inline definition一定不会提供一个external definition,这就确保了不会造成多重定义。
两者都存在的时候,偏向于了inline,也就是在符号表里看不到了,不会出错的原因也同理。
编译与链接2
可以让gcc输出预处理后的结果,然后在预处理的文件里计volatile static int dummy;的数量就可以了。先可以照上面的方法改改Makefile,然后构建预处理的结果,进而用下面的命令得出数量。
find . -type f | xargs cat | grep "volatile static int dummy;" | wc -l这样得出数量是35个。
在debug.h中添加了volatile static int dummy;后,查询到的数量来到了70个,但是实际上还是35个。原因是debug.h中包含了common.h,common.h中包含了debug.h,并且它们都用了宏机制防止二次包含,这就导致这些dummy会成对出现,不过实际上变量实体个数没变,原因在下面。
在添加了 = 0之后,会导致重复定义的问题。而之前没有出现这样的重复定义的问题靠的是这个特性,具体分析就是,之前的两个定义因为没有初始化,所以都是tentative definition,实际上就是这个dummy被empty-initializes了,实际上只有一个它。而其中一个初始化之后,被初始化的那个是一个正常的definition,而没被初始化的那个是tentative definition。两个都被初始化,那就没一个是tentative definition,就导致了重复定义。