虽然PA3更复杂,需要思考的内容比PA2要更多(主要是因为我没有书去学习理论知识,在做这个实验之前都没听说过系统调用和中断/异常的知识),但是PA3的代码量相比PA2有所减少。
阶段1
最简单的操作系统
什么是操作系统? (建议二周目思考)
操作系统是管理计算机资源的软件,它将各个进程和操作系统内核做隔离,并给予各个进程所需的资源。
穿越时空的旅程
特殊的原因? (建议二周目思考)
不能。例如对于riscv32,若不在硬件中实现保存mepc,mstatus,mcause的操作,那么用户态程序在发起一个异常的时候就需要用户态程序自己去设定这些寄存器,但是为了处理器安全,用户态是不可以访问这些寄存器的,所以只能让硬件去实现。
另一个UB
看$AM_HOME/scripts/linker.ld的内容,AM提供的栈的大小是0x8000字节。
实现异常响应机制
在cte_init()中,模板代码用一个内嵌汇编设置了异常入口地址是__am_asm_trap,它定义在$AM_HOME/am/src/riscv/nemu/trap.S。
具体需要实现的新指令就是ecall:
INSTPAT("0000000 00000 00000 000 00000 11100 11", ecall, I,
s->dnpc = isa_raise_intr(11, s->pc));而异常响应的具体操作,即isa_raise_intr应当这样实现:
word_t isa_raise_intr(word_t NO, vaddr_t epc)
{
/* TODO: Trigger an interrupt/exception with ``NO''.
* Then return the address of the interrupt/exception vector.
*/
csr(MEPC) = epc;
csr(MCAUSE) = NO;
return csr(MTVEC);
}这里我的csr是用宏实现的,用了语句表达式等特性,具体如下:
#define MSTATUS 0x300
#define MTVEC 0x305
#define MEPC 0x341
#define MCAUSE 0x342
#define _csr(idx) \
({ \
word_t *ret = NULL; \
switch (idx) \
{ \
case MSTATUS: \
ret = &(cpu.mstatus); \
break; \
case MTVEC: \
ret = &(cpu.mtvec); \
break; \
case MEPC: \
ret = &(cpu.mepc); \
break; \
case MCAUSE: \
ret = &(cpu.mcause); \
break; \
default: \
panic("no such csr, wrong csr number is %d.", idx); \
} \
ret; \
})
#define csr(idx) (*_csr(idx))让DiffTest支持异常响应机制
这个任务就需要我们去好好读一读RISCV的手册了,也就是说我们的异常响应机制应该要和Spike做的一样。不过我研究了很久也没弄懂Spike的机制,所以先放着。
异常号的保存
对于用户态的进程而言并不可以,因为用户态不能够直接操作mcause这个寄存器。不过可以让用户态的进程把异常号放在一个通用寄存器中,然后让异常入口处的软件程序把这个通用寄存器的值保存到mcause中去。
对比异常处理与函数调用
首先是因为CTE不存在一个“被调用者保存寄存器”,所以要把大多数通用寄存器都存下来。而CTE的返回地址其实就是进入CTE之前的pc+4,所以要保存pc。处理器状态自然也要保存,因为特权级发生了变动。此外,保存异常号是为了能让异常处理程序知道关于这个异常的信息。最后地址空间是因为在PA4中会引入进程的概念,为了安全,异常调用有可能会切换地址空间而函数调用却不会。
诡异的x86代码
以后再说吧。
重新组织Context结构体
保存上下文的工作是软件做的,具体而言是在$AM_HOME/am/src/riscv/nemu/trap.S里面做的。下面的高亮代码就是其保存上下文的实现:
__am_asm_trap:
addi sp, sp, -CONTEXT_SIZE
MAP(REGS, PUSH)
csrr t0, mcause
csrr t1, mstatus
csrr t2, mepc
STORE t0, OFFSET_CAUSE(sp)
STORE t1, OFFSET_STATUS(sp)
STORE t2, OFFSET_EPC(sp)
# set mstatus.MPRV to pass difftest
li a0, (1 << 17)
or t1, t1, a0
csrw mstatus, t1
mv a0, sp
call __am_irq_handle
LOAD t1, OFFSET_STATUS(sp)
LOAD t2, OFFSET_EPC(sp)
csrw mstatus, t1
csrw mepc, t2
MAP(REGS, POP)
addi sp, sp, CONTEXT_SIZE
mret这里可以注意到文件后缀名是.S,代表的是这个汇编代码是会被预处理的。 而这里宏太多了,可以预处理一下再查看,通过下面的命令输出预处理后的结果。
gcc -E trap.S -o trap.s得到以下的汇编程序:
__am_asm_trap:
addi sp, sp, -((32 + 4) * 8)
sd x1, (1 * 8)(sp); sd x3, (3 * 8)(sp); sd x4, (4 * 8)(sp); sd x5, (5 * 8)(sp); sd x6, (6 * 8)(sp); sd x7, (7 * 8)(sp); sd x8, (8 * 8)(sp); sd x9, (9 * 8)(sp); sd x10, (10 * 8)(sp); sd x11, (11 * 8)(sp); sd x12, (12 * 8)(sp); sd x13, (13 * 8)(sp); sd x14, (14 * 8)(sp); sd x15, (15 * 8)(sp); sd x16, (16 * 8)(sp); sd x17, (17 * 8)(sp); sd x18, (18 * 8)(sp); sd x19, (19 * 8)(sp); sd x20, (20 * 8)(sp); sd x21, (21 * 8)(sp); sd x22, (22 * 8)(sp); sd x23, (23 * 8)(sp); sd x24, (24 * 8)(sp); sd x25, (25 * 8)(sp); sd x26, (26 * 8)(sp); sd x27, (27 * 8)(sp); sd x28, (28 * 8)(sp); sd x29, (29 * 8)(sp); sd x30, (30 * 8)(sp); sd x31, (31 * 8)(sp);
csrr t0, mcause
csrr t1, mstatus
csrr t2, mepc
sd t0, ((32 + 0) * 8)(sp)
sd t1, ((32 + 1) * 8)(sp)
sd t2, ((32 + 2) * 8)(sp)
# set mstatus.MPRV to pass difftest
li a0, (1 << 17)
or t1, t1, a0
csrw mstatus, t1
mv a0, sp
call __am_irq_handle
ld t1, ((32 + 1) * 8)(sp)
ld t2, ((32 + 2) * 8)(sp)
csrw mstatus, t1
csrw mepc, t2
ld x1, (1 * 8)(sp); ld x3, (3 * 8)(sp); ld x4, (4 * 8)(sp); ld x5, (5 * 8)(sp); ld x6, (6 * 8)(sp); ld x7, (7 * 8)(sp); ld x8, (8 * 8)(sp); ld x9, (9 * 8)(sp); ld x10, (10 * 8)(sp); ld x11, (11 * 8)(sp); ld x12, (12 * 8)(sp); ld x13, (13 * 8)(sp); ld x14, (14 * 8)(sp); ld x15, (15 * 8)(sp); ld x16, (16 * 8)(sp); ld x17, (17 * 8)(sp); ld x18, (18 * 8)(sp); ld x19, (19 * 8)(sp); ld x20, (20 * 8)(sp); ld x21, (21 * 8)(sp); ld x22, (22 * 8)(sp); ld x23, (23 * 8)(sp); ld x24, (24 * 8)(sp); ld x25, (25 * 8)(sp); ld x26, (26 * 8)(sp); ld x27, (27 * 8)(sp); ld x28, (28 * 8)(sp); ld x29, (29 * 8)(sp); ld x30, (30 * 8)(sp); ld x31, (31 * 8)(sp);
addi sp, sp, ((32 + 4) * 8)
mret这就能很清楚的知道实现细节了:首先是在栈里预留CONTEXT_SIZE大小的空间用来存放上下文,然后是由低地址到高地址按次序存放通用寄存器、mcause、mstatus、mepc这几个寄存器。
所以Context结构体也应该这样摆放成员:
struct Context
{
uintptr_t gpr[NR_REGS], mcause, mstatus, mepc;
void *pdir;
};不过注意到一个事实:因为有pdir,虽然暂时没用,但是我们的Context的实际大小也应该是 个字节,所以要修改trap.S的CONTEXT_SIZE宏。这很重要,因为我当时在做PA3的时候就没改,然后在PA4中因此造成的栈溢出的问题让我感到十分诡异,很难debug。
要实现的指令就是csrrs指令,看看手册轻松秒杀。
INSTPAT("??????? ????? ????? 010 ????? 11100 11", csrrs, I,
word_t t = csr(imm);
csr(imm) = t | src1; R(rd) = t;);给一些提示吧
好像也没这么难吧,我没有ICS课本一样瞪眼法瞪出来了。
我乱改一通, 居然过了, 嘿嘿嘿
我可没有乱改,都是有依据的。
必答题(需要在实验报告中回答) - 理解上下文结构体的前世今生
查看RISC-V手册就会知道这个a0通用寄存器就是用来放函数的第一个参数的。看看上面的汇编就会发现是mv a0, sp把参数给传给__am_irq_hendle这个函数了。为什么要传sp寄存器呢?由于我们把上下文从低地址到高地址相对于sp存的,所以sp实际上就是上下文结构体的首地址了,所以把它当作指针的值传过去也很合理吧。
这里面成员的赋值的位置,看看刚才的预处理后的结果就知道了,都是相对于sp的分别的一个偏移处。
这四部分的联系:
riscv.h指定了上下文结构体的定义,方便CTE去使用上下文。trap.S负责异常发生后对之前的程序状态进行保存,然后调用__am_irq_handle进一步处理异常,然后再恢复之前的程序状态。- 上面的讲义文字把这一切的大纲给阐明了。
- 实现的新指令让这些东西能在NEMU上作为一个个指令能执行得动。具体而言
ecall让程序具有了跳到异常处理程序的能力,csrrw和csrrs使得可以读取、写入CSR,让保存、恢复CSR的状态成为可能。
识别自陷事件
其实这里有点怪。因为从RISC-V的手册中没有任何一个异常叫作自陷异常,自然是没有对应的异常号的:
而我们这里都是在M模式引发的ecall,自然,异常号都是11。那我们只能猜测是yield实现中的设置a7为-1表示一个自陷事件。
void yield()
{
#ifdef __riscv_e
asm volatile("li a5, -1; ecall");
#else
asm volatile("li a7, -1; ecall");
#endif
}所以我们这样实现__am_irq_handle:
Context *__am_irq_handle(Context *c)
{
if (user_handler)
{
Event ev = {0};
switch (c->mcause)
{
case 11:
if (c->gpr[17] == -1) // $a7 == -1
ev.event = EVENT_YIELD;
break;
default:
ev.event = EVENT_ERROR;
break;
}
c = user_handler(ev, c);
assert(c != NULL);
}
return c;
}这样,就能在注册的异常处理函数user_handler,即simple_trap中识别出来是EVENT_YIELD,进而输出一个y。
从加4操作看CISC和RISC
CISC交给硬件做,可能会效率更高;RISC交给软件做,那么就需要在识别出EVENT_YIELD之后就把Context里的mepc修改了,也就是在__am_irq_handle里加一行就完事儿。
感觉得把x86的做一下才能锐评一下谁更合理。
恢复上下文
实现这个指令,它可以用来恢复csr寄存器。其他软件上的东西什么也不用动,因为框架软件程序已经完成了上下文恢复的逻辑。然后就是mret指令,用来恢复一下pc:
INSTPAT("??????? ????? ????? 001 ????? 11100 11", csrrw, I,
word_t t = csr(imm);
csr(imm) = src1; R(rd) = t;);
INSTPAT("0011000 00010 00000 000 00000 11100 11", mret, R,
s->dnpc = csr(MEPC););必答题(需要在实验报告中回答) - 理解穿越时空的旅程
yield() -> 在a7寄存器放入自陷的标志,并要求执行ecall指令-> NEMU根据之前设定的异常处理入口,让pc指到异常处理入口__am_asm_trap-> 保存通用寄存器和CSR到栈上->以刚才保存的上下文为参数,调用__am_irq_handle-> 根据上下文的信息识别事件类型,修改mepc,并调用注册好了的simple_trap->输出y-> 从栈上恢复CSR和通用寄存器->调用mret->NEMU根据mepc的实现,恢复pc到mepc-> 继续跑之前的程序。
mips32延迟槽和异常
不懂mips32😭
实现etrace
这当然秒杀了~,在ecall的实现处输出一下异常号和异常所在的地址即可。
阶段2
用户程序和系统调用
为了了解系统调用的概念,现在开始做一些简单的操作系统相关的东西了!
操作系统是个C程序
这个C程序,用不了之前我们写的C程序所用的操作系统的环境,只能用AM的环境。
为Nanos-lite实现正确的事件分发
很简单,知道init_irq是用来注册事件处理程序,因此修改事件处理程序的代码即可:
static Context *do_event(Event e, Context *c)
{
switch (e.event)
{
case EVENT_YIELD:
printf("yield\n");
break;
default:
panic("Unhandled event ID = %d", e.event);
}
return c;
}Nanos-lite上的用户程序的链接位置
教程里说的查看的Makefile文件不对,对于riscv而言,应该看$NAVY_HOME/scripts/riscv/common.mk。
堆和栈在哪里?
堆是程序被加载到内存时操作系统给它分配的,而堆是进程运行过程中动态找操作系统分配的空间。这些都不是ELF文件所能控制的,而是操作系统应该管的事情。
如何识别不同格式的可执行文件?
很简单,ELF文件有一个魔数,assert()一下就知道了。
冗余的属性?
阅读手册可知,FileSiz表示这个segment在文件映像中占有的字节数量,而MemSiz表示这个segment在内存映像中占有的字节数量。
对于Type属性为PT_LOAD的段,因为是要把这个段从文件搬到内存中去,所以应该让其在内存映像中的字节数量更多,才能搬得过去。并且也明确了文件映像的大小一定不能比内存映像大。至于为什么有时候内存映像比文件映像更大,可以看下这个问题。
为什么要清零?
手册中说内存映像中多出来的部分应当用0初始化,不过看了上面的问题后,可以猜测是.bss段的问题。根据定义.bss段要求在程序准备运行时应当初始化为0。
实现loader
由于现在还没有引入虚拟内存,其实这个问题还挺简单的。就是把需要加载的程序段放入内存中对应的地方,然后设定程序入口地址即可。
size_t ramdisk_read(void *buf, size_t offset, size_t len);
static uintptr_t loader(PCB *pcb, const char *filename)
{
#if defined(__ISA_AM_NATIVE__)
#define EXPECT_TYPE EM_X86_64
#elif defined(__ISA_RISCV32__)
#define EXPECT_TYPE EM_RISCV
#else
#error Unsupported ISA
#endif
Elf_Ehdr ehdr;
ramdisk_read(&ehdr, 0, sizeof(Elf_Ehdr));
assert(ehdr.e_ident[EI_MAG0] == ELFMAG0);
assert(ehdr.e_ident[EI_MAG1] == ELFMAG1);
assert(ehdr.e_ident[EI_MAG2] == ELFMAG2);
assert(ehdr.e_machine == EXPECT_TYPE);
size_t phdr_offset = ehdr.e_phoff;
size_t phdr_num = ehdr.e_phnum;
Elf_Phdr phdr;
for (size_t i = 0; i < phdr_num; i++)
{
size_t off = phdr_offset + i * sizeof(Elf_Phdr);
ramdisk_read(&phdr, off, sizeof(Elf_Phdr));
if (phdr.p_type != PT_LOAD) continue;
void *mem = (void *)(uintptr_t)phdr.p_vaddr;
ramdisk_read(mem, phdr.p_offset, phdr.p_filesz);
mem += phdr.p_filesz;
memset(mem, 0, phdr.p_memsz - phdr.p_filesz);
}
return (uintptr_t)ehdr.e_entry;
}被触发的未处理事件,其实就是之后要讲的系统调用。
检查ELF文件的魔数
已做,上面已说明。
检测ELF文件的ISA类型
已做。ELF头里有个e_machine,表示这个ELF文件对应的架构。而这个宏定义在这里:
CFLAGS += -O2 -MMD -Wall -Werror $(INCFLAGS) \
-D__ISA__=\"$(ISA)\" -D__ISA_$(shell echo $(ISA) | tr a-z A-Z)__ \
-D__ARCH__=$(ARCH) -D__ARCH_$(shell echo $(ARCH) | tr a-z A-Z | tr - _) \
-D__PLATFORM__=$(PLATFORM) -D__PLATFORM_$(shell echo $(PLATFORM) | tr a-z A-Z | tr - _) \
-DARCH_H=\"$(ARCH_H)\" \
-fno-asynchronous-unwind-tables -fno-builtin -fno-stack-protector \
-Wno-main -U_FORTIFY_SOURCE -fvisibility=hidden系统调用的必要性
是必须的。首先它破坏了操作系统的一层屏蔽和封装,导致批处理程序实质上运行在了AM上,能做任何它想做的事情,变得不安全。并且,批处理系统要求程序一个接一个完成,而如果没有系统调用,单个程序的结束只能靠halt来停机,这下整个NEMU都停机了,没办法运行下一个程序了。
识别系统调用
查看dummy.c知道它是调用了一个_syscall_函数,然后找到它的定义在这里:
intptr_t _syscall_(intptr_t type, intptr_t a0, intptr_t a1, intptr_t a2) {
register intptr_t _gpr1 asm (GPR1) = type;
register intptr_t _gpr2 asm (GPR2) = a0;
register intptr_t _gpr3 asm (GPR3) = a1;
register intptr_t _gpr4 asm (GPR4) = a2;
register intptr_t ret asm (GPRx);
asm volatile (SYSCALL : "=r" (ret) : "r"(_gpr1), "r"(_gpr2), "r"(_gpr3), "r"(_gpr4));
return ret;
}阅读这个C源文件的宏定义,可以知道对于riscv32而言,这个函数实际上就发起了一个ecall指令,并以a7作为系统调用的类型;a0,a1,a2作为系统调用的参数;a0作为系统调用的返回值。为了支持系统调用,我们首先需要改AM里的CTE,使其通过a7识别系统调用事件:
Context *__am_irq_handle(Context *c)
{
if (user_handler)
{
Event ev = {0};
switch (c->mcause)
{
case 11:
if (c->GPR1 == -1) // $a7 == -1
ev.event = EVENT_YIELD;
else if (c->GPR1 <= 19)
ev.event = EVENT_SYSCALL;
c->mepc += 4;
break;
default:
ev.event = EVENT_ERROR;
break;
}
c = user_handler(ev, c);
assert(c != NULL);
}
return c;
}而且CTE里面GPR1、GPR2等等宏定义也得改改,因为这些东西都是AM环境,OS会用到的。实际上,GPR1对应系统调用的类型;GPR2,GPR3,GPR4对应系统调用的参数;而GPRx对应系统调用的返回值。
至于为什么这里有c->GPR1 <= 19,这是因为这个头文件表明了所有可能的系统调用,最大的一个也才是19:
#ifndef __SYSCALL_H__
#define __SYSCALL_H__
enum {
SYS_exit,
SYS_yield,
SYS_open,
SYS_read,
SYS_write,
SYS_kill,
SYS_getpid,
SYS_close,
SYS_lseek,
SYS_brk,
SYS_fstat,
SYS_time,
SYS_signal,
SYS_execve,
SYS_fork,
SYS_link,
SYS_unlink,
SYS_wait,
SYS_times,
SYS_gettimeofday
};
#endif然后是修改OS中的事件处理模块,使其对于系统调用事件做出合适的反应:
static Context *do_event(Event e, Context *c)
{
switch (e.event)
{
case EVENT_YIELD:
printf("yield\n");
break;
case EVENT_SYSCALL:
do_syscall(c);
break;
default:
panic("Unhandled event ID = %d", e.event);
}
return c;
}实现SYS_yield系统调用
很简单,改改do_syscall的实现就好了。之前的GPR?宏都已经完成好了。
void do_syscall(Context *c)
{
uintptr_t a[4];
a[0] = c->GPR1;
a[1] = c->GPR2;
a[2] = c->GPR3;
a[3] = c->GPR4;
switch (a[0])
{
case SYS_yield:
yield();
c->GPRx = 0;
break;
default:
panic("Unhandled syscall ID = %d", a[0]);
}
}关于为什么在发生SYS_yield后又会发生一个SYS_exit,可以了解一个navy-app的执行全过程。首先从程序入口_start开始,这会跳到call_main去。
int main(int argc, char *argv[], char *envp[]);
extern char **environ;
void call_main(uintptr_t *args) {
char *empty[] = {NULL };
environ = empty;
exit(main(0, empty, empty));
assert(0);
}这个call_main会调用用户程序中的main函数,然后以这个main函数的返回值作为参数调用exit函数,而这个exit最终会调用SYS_exit系统调用。
实现SYS_exit系统调用
很简单啊,改一下do_syscall的实现就好了。
void do_syscall(Context *c)
{
uintptr_t a[4];
a[0] = c->GPR1;
a[1] = c->GPR2;
a[2] = c->GPR3;
a[3] = c->GPR4;
switch (a[0])
{
case SYS_yield:
yield();
c->GPRx = 0;
break;
case SYS_exit:
halt(a[1]);
break;
default:
panic("Unhandled syscall ID = %d", a[0]);
}
}RISC-V系统调用号的传递
也许是因为a0在函数调用中往往被当作是第一个参数和返回值,因此就被当作是系统调用的第一个参数了。
实现strace
实现strace是一个简单的任务,但是要做的漂亮有点麻烦。只需要在do_syscall里添加一点代码,记录系统调用号、参数和返回值就可以了。
为了让它能打印系统调用的名字,我特地做了这么个数组:
const char *syscall_names[] = {"SYS_exit", "SYS_yield", "SYS_open",
"SYS_read", "SYS_write", "SYS_kill",
"SYS_getpid", "SYS_close", "SYS_lseek",
"SYS_brk", "SYS_fstat", "SYS_time",
"SYS_signal", "SYS_execve", "SYS_fork",
"SYS_link", "SYS_unlink", "SYS_wait",
"SYS_times", "SYS_gettimeofday"};在Nanos-lite上运行Hello world
实现write()也并不困难,首先在libos库里修改一下_write的实现,这里的具体接口要查手册:
int _write(int fd, void *buf, size_t count)
{
_syscall_(SYS_write, fd, (intptr_t)buf, count);
return 0;
}因为现在的SYS_write只需要输出到stdout或者是stderr就可以了,所以简单实现一下,将buf里的各个字符输出即可。注意它的返回值是实际写出去的字节数。
static int sys_write(Context *c, uintptr_t *a)
{
int fd = a[1];
uint8_t *buf = (void *)a[2];
size_t count = a[3];
int ret = 0;
switch (fd)
{
case 1:
case 2:
for (size_t i = 0; i < count; i++)
{
putch(buf[i]);
ret++;
}
break;
default:
panic("Invalid fd = %d\n", fd);
}
return ret;
}
void do_syscall(Context *c)
{
uintptr_t a[4];
a[0] = c->GPR1;
a[1] = c->GPR2;
a[2] = c->GPR3;
a[3] = c->GPR4;
switch (a[0])
{
case SYS_yield:
yield();
c->GPRx = 0;
break;
case SYS_exit:
halt(a[1]);
break;
case SYS_write:
c->GPRx = sys_write(c, a);
break;
default:
panic("Unhandled syscall ID = %d", a[0]);
}
}实现堆区管理
教程里已经写的很详细了。关于_end的问题在之前已经了解过了。不过这里可以简单地详细讲一下:这个_end会在链接后出现在ELF文件的符号表中,并不是$NAVY_HOME/libs/libos/src/syscall.c编译出来的syscall.o会生成的符号,所以要用extern声明变量end。
extern uintptr_t end;
static uintptr_t brk_offset = 0;
void *_sbrk(intptr_t increment)
{
uintptr_t old_brk = (uintptr_t)&end + brk_offset;
int ret = _syscall_(SYS_brk, old_brk + increment, 0, 0);
if (ret)
return (void *)-1;
// OK
brk_offset += increment;
return (void *)old_brk;
}在OS上的实现先简单处理一下,实际上就是随便sbrk:
static int sys_brk(Context *c, uintptr_t *a)
{
void *addr __attribute__((unused)) = (void *)a[1];
return 0;
}缓冲区与系统调用开销
之后再实验一下。
printf和换行
其实也就是这一小段代码:
if (++n == fp->_bf._size || (fp->_flags & __SLBF && c == '\n'))
if (_fflush_r (ptr, fp))
return EOF;不过更加应该让人关注的是,要记住fread和fwrite不会立即处理,而是放缓冲区里把多次化一次系统调用处理。
必答题(需要在实验报告中回答) - hello程序是什么, 它从而何来, 要到哪里去
hello程序一开始在哪里?
hello程序在编译后一开始人为地放在了build/ramdisk.img的磁盘映像中。
它是怎么出现内存中的?
OS启动后通过naive_uload去读取磁盘映像中的ELF文件,将ELF文件的需要加载到内存里的program segment放在内存中的指定位置。
为什么会出现在目前的内存位置?
首先,在链接时LDFLAGS规定了-Ttext-segment $(LNK_ADDR),其中$(LNK_ADDR)为0x83000000,这代表着被链接到了0x83000000。因此在ELF文件中地址就长这样了。然后我们也没有引入虚拟内存,所以ELF文件里被链接到哪儿就载入到内存的哪儿。
它的第一条指令在哪里?
观察到它的程序入口在0x830000bc,实际上就是_start,默认的入口符号名。
究竟是怎么执行到它的第一条指令的?
在naive_uload的loader结束后,拿到了程序的入口,然后直接把它强转成了一个没有参数,返回值为void的函数指针然后去调用了。
hello程序在不断地打印字符串, 每一个字符又是经历了什么才会最终出现在终端上?
hello程序调用printf->OS上的libc->系统调用write()->指令ecall,并给对应寄存器附上参数->(…异常处理程序到保存上下文的流程…)->调用事件处理程序->识别事件类型->调用OS给的处理程序->识别为系统调用->识别为SYS_write系统调用->读保存在上下文的寄存器参数,遍历buf并利用AM的putch打印字符出去->访问了串口对应的内存地址->一个访存指令->NEMU解释其为访问设备,并调用设备的回调函数进行处理->调用了本Linux机的putc,输出到了终端上。
支持多个ELF的ftrace
这个东西之后再做吧。
阶段3
文件系统
文件本质上就是字节序列。我们的文件系统就是为了管理文件到ramdisk中的位置的映射并为上层用户程序提供文件操作的接口。
不过这里的文件是抽象的,并不一定每个文件都有“名字”,所以用文件描述符表示一个正在打开的文件,让OS来维护文件描述符到具体文件的映射。
文件偏移量和用户程序
如果偏移量放在了文件记录表中, 那么对于每一个进程而言它们所对应的文件系统的状态就是一样的。这就意味着无法让两个进程并发地读同一个文件,因为显然这需要这个文件为不同的进程提供不同的偏移量。
让loader使用文件
现在引入了好几个系统调用,其中lseek其实有点说法。因为lseek可以直接指定一个文件的offset,这就意味着它所操作的文件(字节序列)一定要有“位置”的概念。像磁盘(块设备)中的文件就是有位置的概念的,它可以被lseek;但是像键盘(字符设备)输入、串口(字符设备)输出就是没有的,不能被lseek。因此需要在FInfo结构体里添加一个字段表示这个文件是在块设备上还是字符设备上。
typedef size_t (*ReadFn) (void *buf, size_t offset, size_t len);
typedef size_t (*WriteFn) (const void *buf, size_t offset, size_t len);
typedef struct
{
char *name;
size_t size;
size_t disk_offset;
size_t open_offset;
int not_support_lseek;
ReadFn read;
WriteFn write;
} Finfo;Finfo file_table[] __attribute__((used)) = {
[FD_STDIN] = {"stdin", 0, 0, 0, 1, invalid_read, invalid_write},
[FD_STDOUT] = {"stdout", 0, 0, 0, 1, invalid_read, serial_write},
[FD_STDERR] = {"stderr", 0, 0, 0, 1, invalid_read, serial_write},
#include "files.h"
};
int fs_open(const char *pathname, int flags, int mode)
{
size_t file_cnt = sizeof(file_table) / sizeof(Finfo);
for (int i = 0; i < file_cnt; i++)
{
if (strcmp(file_table[i].name, pathname) == 0)
{
file_table[i].open_offset = 0;
return i;
}
}
panic("Invalid pathname: %s\n", pathname);
}
size_t fs_read(int fd, void *buf, size_t len)
{
Finfo *fi = file_table + fd;
ReadFn read_fn = fi->read;
if (!read_fn)
read_fn = &ramdisk_read;
if (!fi->not_support_lseek)
len = min(len, fi->size - fi->open_offset);
size_t ret = read_fn(buf, fi->disk_offset + fi->open_offset, len);
if (!fi->not_support_lseek)
fi->open_offset += ret;
return ret;
}
size_t fs_lseek(int fd, size_t offset, int whence)
{
size_t *fi_open_offset = &(file_table[fd].open_offset);
switch (whence)
{
case SEEK_SET:
*fi_open_offset = offset;
break;
case SEEK_CUR:
*fi_open_offset += offset;
break;
case SEEK_END:
*fi_open_offset = file_table[fd].size + offset;
break;
default:
panic("Undefined whence = %d\n", whence);
}
return *fi_open_offset;
}
int fs_close(int fd)
{
return 0;
}在此之后,我们就可以利用FS提供的接口去读取文件了,进而在加载程序这里也用上FS的接口。
static uintptr_t loader(PCB *pcb, const char *filename)
{
#if defined(__ISA_AM_NATIVE__)
#define EXPECT_TYPE EM_X86_64
#elif defined(__ISA_RISCV32__)
#define EXPECT_TYPE EM_RISCV
#else
#error Unsupported ISA
#endif
int fd = fs_open(filename, 0, 0);
Elf_Ehdr ehdr;
fs_read(fd, &ehdr, sizeof(Elf_Ehdr));
assert(ehdr.e_ident[EI_MAG0] == ELFMAG0);
assert(ehdr.e_ident[EI_MAG1] == ELFMAG1);
assert(ehdr.e_ident[EI_MAG2] == ELFMAG2);
assert(ehdr.e_machine == EXPECT_TYPE);
size_t phdr_num = ehdr.e_phnum;
Elf_Phdr phdr;
for (size_t i = 0; i < phdr_num; i++)
{
fs_lseek(fd, ehdr.e_phoff + i * sizeof(Elf_Phdr), SEEK_SET);
fs_read(fd, &phdr, sizeof(Elf_Phdr));
if (phdr.p_type != PT_LOAD)
continue;
void *mem = (void *)(uintptr_t)phdr.p_vaddr;
fs_lseek(fd, phdr.p_offset, SEEK_SET);
fs_read(fd, mem, phdr.p_filesz);
mem += phdr.p_filesz;
memset(mem, 0, phdr.p_memsz - phdr.p_filesz);
}
fs_close(fd);
return (uintptr_t)ehdr.e_entry;
}实现完整的文件系统
其实上面我们已经实现了fs_lseek了,而事实上fs_write和fs_read的实现很类似,这里就不多做赘述。当然,还需要实现一下串口写的函数serial_write,不过这很简单。
最后,因为要让用户程序能用到我们新添加的FS,我们应该在系统调用处更新一下接口:
static int sys_write(Context *c, uintptr_t *a)
{
int fd = a[1];
uint8_t *buf = (void *)a[2];
size_t count = a[3];
#ifdef CONFIG_STRACE
extern Finfo file_table[];
printf("%s %p %u\n", file_table[fd].name, buf, count);
#endif
return fs_write(fd, buf, count);
}
static size_t sys_read(Context *c, uintptr_t *a)
{
int fd = a[1];
uint8_t *buf = (void *)a[2];
size_t count = a[3];
#ifdef CONFIG_STRACE
extern Finfo file_table[];
printf("%s %p %u\n", file_table[fd].name, buf, count);
#endif
return fs_read(fd, buf, count);
}
static size_t sys_lseek(Context *c, uintptr_t *a)
{
int fd = a[1];
size_t offset = a[2];
int whence = a[3];
#ifdef CONFIG_STRACE
extern Finfo file_table[];
printf("%s %u %d\n", file_table[fd].name, offset, whence);
#endif
return fs_lseek(fd, offset, whence);
}
static int sys_open(Context *c, uintptr_t *a)
{
const char *pathname = (void *)a[1];
int flags = a[2];
int mode = a[3];
#ifdef CONFIG_STRACE
printf("%s %d %d\n", pathname, flags, mode);
#endif
return fs_open(pathname, flags, mode);
}
static int sys_close(Context *c, uintptr_t *a)
{
int fd = a[1];
#ifdef CONFIG_STRACE
extern Finfo file_table[];
printf("%s\n", file_table[fd].name);
#endif
return fs_close(fd);
}这样我们的file-test就可以轻松通过了。
支持sfs的strace
上面系统调用的实现中被#ifdef和#endif围起来的部分就是干这个事情的。
用C语言模拟面向对象编程
之后再看看。
把串口抽象成文件
之前实现时已经考虑到VFS的抽象了,所以这一点已经提前实现了。
实现gettimeofday
本题难点在于读手册:
If either tv or tz is NULL, the corresponding structure is not set or returned. (However, compilation warnings will result if tv is NULL.)
The use of the timezone structure is obsolete; the tz argument should normally be specified as NULL. (See NOTES below.)
意思差不多就是说,tz这个参数没啥用,一般传个NULL就得了。
对于timeval的定义,man 3 timeradd里有写,就是
struct timeval {
time_t tv_sec; /* seconds */
suseconds_t tv_usec; /* microseconds */
};这俩类型其实都是long。
已知我们AM上的__am_timer_uptime会给出微秒数,根据简单的单位换算的数学知识,就能很快得到下面的代码了:
static int sys_gettimeofday(Context *c, uintptr_t *a)
{
struct timeval *tv = (void *)a[1];
struct timezone *tz __attribute__((unused)) = (void *)a[2];
#ifdef CONFIG_STRACE
printf("%p %p\n", tv, tz);
#endif
uint64_t us = io_read(AM_TIMER_UPTIME).us;
tv->tv_usec = us % 1000000;
tv->tv_sec = us / 1000000;
return 0;
}测试程序每半秒钟就会输出一句话,证明我们的实现是正确的。
实现NDL的时钟
实现策略可以仿照原先的time-test,只是单位从半秒变成了毫秒而已:
uint32_t NDL_GetTicks()
{
struct timeval tv;
gettimeofday(&tv, NULL);
uint32_t ret = tv.tv_sec * 1000 + tv.tv_usec / 1000;
return ret;
}然后这是修改后的time-test:
#include <stdio.h>
#include <NDL.h>
int main()
{
NDL_Init(0);
int half_sec = 1;
while (1)
{
while (1)
{
uint32_t res = NDL_GetTicks();
res /= 500;
if (res >= half_sec)
break;
}
printf("%d half-seconds\n", half_sec);
half_sec++;
}
NDL_Quit();
return 0;
}把按键输入抽象成文件
首先实现一下events_read(),需要注意的是,虽然假设一次最多只会读出一个事件,但是也会有可能读出来半个事件,这时候我们就需要做一些特殊处理:
static char event_buf[300] = {0};
size_t events_read(void *buf, size_t offset, size_t len)
{
size_t event_buf_len = strlen(event_buf);
if (event_buf_len == 0)
{
AM_INPUT_KEYBRD_T keybrd = io_read(AM_INPUT_KEYBRD);
if (keybrd.keycode == AM_KEY_NONE)
return 0;
sprintf(event_buf, "k%c %s\n", keybrd.keydown ? 'd' : 'u',
keyname[keybrd.keycode]);
}
event_buf_len = strlen(event_buf);
size_t ret = (event_buf_len < len ? event_buf_len : len);
memcpy(buf, event_buf, ret);
memmove(event_buf, event_buf + ret, event_buf_len - ret + 1);
return ret;
}也就是只有读了完整事件的时候才会重新从键盘设备获取新按的键,然后把事件字符串写到buf里,否则就只把len限制的部分写过去,留下剩下的残缺的事件字符串,等下次再读。
由于用户程序要读取键盘事件得靠VFS,所以得在文件目录中注册/dev/events:
[FD_EVENT] = {"/dev/events", 0, 0, 0, 1, events_read, invalid_write},最后是在用户程序那边的NDL库中包装一下获取键盘事件的过程:
int NDL_PollEvent(char *buf, int len)
{
int fd = open("/dev/events", O_RDONLY);
int ok = read(fd, buf, len);
buf[ok] = '\0';
close(fd);
return ok != 0;
}跑测试的时候会发现打印一个事件的字符串后会跟上一个空行。原因是事件本身有一个\n,然后event-test程序里又有一个\n。
用fopen()还是open()?
当然是用open(),因为上面提到经过库包装后的可能会有缓冲区等等东西。我们在这里并不希望它会有缓冲。
在NDL中获取屏幕大小
根据README.md中所说,应该这样实现dispinfo_read():
int screen_width, screen_height;
size_t dispinfo_read(void *buf, size_t offset, size_t len)
{
char info_buf[100];
size_t sz =
sprintf(info_buf, "WIDTH:%d\nHEIGHT:%d\n", screen_width, screen_height);
size_t ret = (sz < len ? sz : len);
memcpy(buf, info_buf, ret);
return ret;
}
void init_device()
{
Log("Initializing devices...");
ioe_init();
AM_GPU_CONFIG_T conf = io_read(AM_GPU_CONFIG);
screen_width = conf.width;
screen_height = conf.height;
}为了能让用户程序从系统调用来访问VFS,应该添加文件目录:
[FD_FBINFO] = {"/proc/dispinfo", 0, 0, 0, 1, dispinfo_read, invalid_write},在navy-app这边,则需要简单实现一下NDL库里的内容。我在NDL_init()的时候调用了read_dispinfo函数得到屏幕的长宽信息,然后才好实现NDL_OpenCanvas。
static int screen_w = 0, screen_h = 0;
static int canvas_w = 0, canvas_h = 0;
void NDL_OpenCanvas(int *w, int *h)
{
if (getenv("NWM_APP"))
{
int fbctl = 4;
fbdev = 5;
screen_w = *w;
screen_h = *h;
char buf[64];
int len = sprintf(buf, "%d %d", screen_w, screen_h);
// let NWM resize the window and create the frame buffer
write(fbctl, buf, len);
while (1)
{
// 3 = evtdev
int nread = read(3, buf, sizeof(buf) - 1);
if (nread <= 0)
continue;
buf[nread] = '\0';
if (strcmp(buf, "mmap ok") == 0)
break;
}
close(fbctl);
}
if (*w == 0 && *h == 0)
{
*w = canvas_w = screen_w;
*h = canvas_h = screen_h;
return;
}
canvas_w = *w;
canvas_h = *h;
}
static void read_dispinfo()
{
int fd = open("/proc/dispinfo", O_RDONLY);
char key[2][50], value[2][50];
char buf[200] = {0};
read(fd, buf, sizeof(buf));
int ptr = 0;
for (int i = 0; i < 2; i++)
{
int mid = ptr;
while (buf[mid] != ':')
mid++;
strncpy(key[i], buf + ptr, mid - ptr);
key[i][mid - ptr] = '\0';
while (buf[ptr] != '\n')
ptr++;
strncpy(value[i], buf + mid + 1, ptr - mid - 1);
value[i][ptr - mid - 1] = '\0';
ptr++;
}
for (int i = 0; i < 2; i++)
{
char *k = key[i];
char *v = value[i];
if (strcmp(k, "WIDTH") == 0)
sscanf(v, "%d", &screen_w);
else if (strcmp(k, "HEIGHT") == 0)
sscanf(v, "%d", &screen_h);
else
assert(0);
}
}
int NDL_Init(uint32_t flags)
{
if (getenv("NWM_APP"))
{
evtdev = 3;
}
read_dispinfo();
return 0;
}把VGA显存抽象成文件
教程中说的很详细了,首先初始化/dev/fb的大小,这里的vmemsz必须现算,因为native的IOE中vmemsz是0:
void init_fs()
{
// TODO: initialize the size of /dev/fb
AM_GPU_CONFIG_T conf = io_read(AM_GPU_CONFIG);
file_table[FD_FB].size = conf.width * conf.height * 4;
}然后是实现fb_write(),这需要一点点小技巧。在AM的IOE里面给的接口是在屏幕上的一个矩形区域内填色,而这里只能连着填色。我们可以考虑成这两种情况:
- 连着填只有一行:1个
io_write就行了,因为一行本身就是一个矩形。 - 连着多行:可能需要3个
io_write,第1个io_write处理第1行(可能没填满),第2个io_write处理第2到倒数第2行(这些是全满的行,所以是一个大矩形),第3个io_write处理最后1行即可。
要记住在OS里的坐标都是屏幕坐标!
代码实现如下:
size_t fb_write(const void *buf, size_t offset, size_t len)
{
assert(len % 4 == 0);
assert(offset % 4 == 0);
offset /= 4;
len /= 4;
int y = offset / screen_width;
int x = offset % screen_width;
int yy = (offset + len) / screen_width;
int xx = (offset + len) % screen_width;
size_t buf_off = 0;
if (yy > y)
{
io_write(AM_GPU_FBDRAW, x, y, (void *)buf, screen_width - x, 1, false);
buf_off += screen_width - x;
io_write(AM_GPU_FBDRAW, 0, y + 1, (void *)buf + buf_off, screen_width,
yy - y - 1, false);
buf_off += screen_width * (yy - y - 1);
io_write(AM_GPU_FBDRAW, 0, yy, (void *)buf + buf_off, xx, 1, true);
}
else
{
io_write(AM_GPU_FBDRAW, x, y, (void *)buf, xx - x + 1, 1, true);
}
return len;
}然后是在navy-app中实现NDL库。这里的画布是由用户程序通过NDL_OpenCancas创建的,它本身其实就是抽象给用户程序来绘图的,用户程序绘图到画布上的接口就是NDL_DrawRect。而画布究竟在屏幕的哪里完全取决于NDL库的实现。所以我做了一个函数canvas2screen表示画布的坐标所线性映射到的屏幕的坐标,然后在NDL_DrawRect中先把画布坐标转化为屏幕坐标,然后再调用系统调用去画。
static void canvas2screen(int cx, int cy, int *sx, int *sy)
{
*sx = cx;
*sy = cy;
}
void NDL_DrawRect(uint32_t *pixels, int x, int y, int w, int h)
{
int sx, sy;
canvas2screen(x, y, &sx, &sy);
int fd = open("/dev/fb", 0);
for (int i = sy; i < sy + h; i++)
{
int offset = i * screen_w + sx;
offset = offset * 4;
lseek(fd, offset, SEEK_SET);
int len = w * 4;
write(fd, pixels, len);
pixels += w;
}
close(fd);
}看上述代码就知道,我目前是把画布就当作屏幕的,所以画的东西会出现在屏幕的左上角。
测试程序如下:

上面我的实现中是在NDL_DrawRect函数体里面open了/dev/fb文件,然后写完之后对它进行了close操作。这样做的原因是我们在OS中的open和close系统调用实现并不会产生很大的副作用,随便开开关关也没事。但是这和native(也就是navy用户程序直接在本机Linux上)的运行环境并不一致。下面我们来认真探讨一下:
首先我们要确信,native的作用就是在navy用户程序所用的系统调用和本机Linux给出的系统调用接口之间做了一个中间层,把本机Linux给出的系统调用接口虚拟成了navy用户程序所需的系统调用接口。于是我们重点在于看在native里/dev/fb这个文件是如何被处理的:
static void open_display()
{
fb_memfd = memfd_create("fb", 0);
assert(fb_memfd != -1);
int ret = ftruncate(fb_memfd, FB_SIZE);
assert(ret == 0);
fb = (uint32_t *)mmap(NULL, FB_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED,
fb_memfd, 0);
assert(fb != (void *)-1);
memset(fb, 0, FB_SIZE);
lseek(fb_memfd, 0, SEEK_SET);
SDL_InitSubSystem(SDL_INIT_VIDEO | SDL_INIT_TIMER);
window = SDL_CreateWindow("Simulated Nanos Application",
SDL_WINDOWPOS_UNDEFINED, SDL_WINDOWPOS_UNDEFINED,
WINDOW_W, WINDOW_H, SDL_WINDOW_OPENGL);
surface = SDL_CreateRGBSurfaceFrom(fb, disp_w, disp_h, 32,
disp_w * sizeof(uint32_t), RMASK, GMASK,
BMASK, AMASK);
SDL_CreateThread(event_thread, "event thread", nullptr);
SDL_AddTimer(1000 / FPS, texture_sync, NULL);
}
int open(const char *path, int flags, ...)
{
if (strcmp(path, "/proc/dispinfo") == 0)
{
return dispinfo_fd;
}
else if (strcmp(path, "/dev/events") == 0)
{
return evt_fd;
}
else if (strcmp(path, "/dev/fb") == 0)
{
return fb_memfd;
}
else if (strcmp(path, "/dev/sb") == 0)
{
return sb_fifo[1];
}
else if (strcmp(path, "/dev/sbctl") == 0)
{
return sbctl_fd;
}
else
{
char newpath[512];
return glibc_open(redirect_path(newpath, path), flags);
}
}可以看到,在open_display里面,用memfd_create创建了一个存在于内存中的文件fb_memfd,然后设定其大小。接着用mmap系统调用把文件映射到内存中,得到指针fb。设置画面全0后,把fb作为画面数组扔给SDL库生成一个SDL_Surface,之后每次刷新画面就用这个fb对应的SDL_Surface去画图。这样,我们就可以在navy用户程序中通过向fb_memfd文件写入画面数据进而更新画面内容了。但是memfd_create是有副作用的,手册中写道:
However, unlike a regular file, it lives in RAM and has a volatile backing storage. Once all references to the file are dropped, it is automatically released.
所以我们在一次open()后再用close(),那么这个文件就会不复存在了,之后对它的任何操作也必然是UB了。因此上面我们的NDL_DrawRect的实现如果在native下运行就会导致诡异的Bug:第一次调用NDL_DrawRect,进行一次绘图,非常正常,然后第二次调用NDL_DrawRect的时候就会发生UB,有时候会卡住,卡在lseek的地方,有时候会直接X11服务器崩溃,还有时会导致空指针,让人摸不着头脑。
所以正确的实现应该是在NDL_Init中统一开文件,然后在NDL_Quit中统一关文件,这样fb_memfd就只会被关一次,就不会导致这个文件提前死亡。
实现居中的画布
这其实就是换了一下坐标。具体实现上就是改一下canvas2screen就可以:
static void canvas2screen(int cx, int cy, int *sx, int *sy)
{
*sx = cx + (screen_w - canvas_w) / 2;
*sy = cy + (screen_h - canvas_h) / 2;
}
精彩纷呈的应用程序
比较fixedpt和float
float的小数点是浮动的,这意味着它可以表示更加通过调整幂次等方法表示特别小或者特别大的数字,而用fixedpt只能保证精细度恒定在,无法表示特别小或者特别大的数字。
神奇的fixedpt_rconst
注意到我们编译C源文件时采用的CFLAGS:
CFLAGS += -march=rv32g -mabi=ilp32 #overwriteABI被设为ilp32,意味着只有整数,没有硬件上的浮点运算。阅读了RISC-V的手册后也会知道,ELF文件里的文件头的e_flags字段就会保存一些关于ABI的信息:例如ilp32对应的EF_RISCV_FLOAT_ABI_SOFT就是0,而在navy-apps里面以make ISA=riscv32编译出来的ELF也能发现其ELF头里的e_flags为0。
像这样的EF_RISCV_FLOAT_ABI_SOFT的软浮点,编译器就会用通用寄存器去模拟浮点过程,只是效率会很慢。
实现更多的fixedptc API
对于一个fixedpt数a与一个整数B相乘,得到结果C可以用这样子的数学语言表达:
按照这个思路就可以实现这些函数了:
/* Multiplies two fixedpt numbers, returns the result. */
static inline fixedpt fixedpt_mul(fixedpt A, fixedpt B)
{
int64_t tmp = A * B;
return tmp / 256;
}
/* Divides two fixedpt numbers, returns the result. */
static inline fixedpt fixedpt_div(fixedpt A, fixedpt B)
{
int64_t tmp = A * 256;
return tmp / B;
}
/* Multiplies two fixedpt numbers, returns the result. */
static inline fixedpt fixedpt_mul(fixedpt A, fixedpt B)
{
return (A * B) >> 8;
}
/* Divides two fixedpt numbers, returns the result. */
static inline fixedpt fixedpt_div(fixedpt A, fixedpt B)
{
return (A / B) << 8;
}由于定义里设定a的表示A的相反数就直接是补码相反数,所以fixedpt_abs也很简单:
static inline fixedpt fixedpt_abs(fixedpt A)
{
if (A >= 0)
return A;
else
return -A;
}注意floor(x)的定义是小于等于x的最大的整数。多亏了补码机制,直接将小数位清空即可。
static inline fixedpt fixedpt_floor(fixedpt A)
{
int mask = -256;
return A & mask;
}而ceil(x)的定义是大于等于x的最小的整数。由此需要先判一下小数部分有没有数,没有就是这个数本身,有就加个1再清空小数部分。
static inline fixedpt fixedpt_ceil(fixedpt A)
{
int mask = 255;
if (A & mask)
A += (1 << 8);
int mask2 = -256;
return A & mask2;
}如何将浮点变量转换成fixedpt类型?
虽然这个计算机没有浮点指令,但是我们可以用编译器从软件的角度解析浮点数。首先根据IEEE 754的原则,浮点数是 ,设f是小数字段的值,e是阶码部分的值。f,e和s都是可以直接从内存中读出的“无符号数”。这里的s目前并不重要,所以先当作没有。
对于规格化的值,根据定义实际上浮点数的值是,对应到定点数可以表示成这样:
而对于非规格化的值,根据定义实际上浮点数的值是,对应到定点数就直接表示成这样:
实际上这里非规格化的值、特殊值都不在fixedpt的表示范围中,所以只需要了解规格化的值就可以了。
刚才忽略了符号,如果是负数的话就直接给得到的定点数表示做一个相反数(补码)即可。
神奇的LD_PRELOAD
首先我们看一下路径是如何改变的。如果注意到日志的内容这会很好寻找:
static const char *redirect_path(char *newpath, const char *path)
{
get_fsimg_path(newpath, path);
if (0 == access(newpath, 0))
{
fprintf(stderr, "Redirecting file open: %s -> %s\n", path, newpath);
return newpath;
}
return path;
}是get_fsimg_path重定向了文件的路径。本质上是往前面添加了一个前缀。这个前缀有部分是依靠读环境变量$NAVY_HOME读出来的,这一块并不困难。
不过要想用到这个redirect_path得先调用native.so的fopen,open, execve函数,注意到这是个动态链接库,并不是静态链接上去的,于是注意到native.mk文件中是如何运行的:
run: app env
@LD_PRELOAD=$(NAVY_HOME)/libs/libos/build/native.so $(APP) $(mainargs)网上去man了一下LD_PRELOAD的意思:
LD_PRELOAD
A list of additional, user-specified, ELF shared objects to be loaded before all others. This feature can be used to selectively override functions in other shared objects.The items of the list can be separated by spaces or colons,and there is no support for escaping either separator.
The objects are searched for using the rules given under DESCRIPTION. Objects are searched for and added to the link map in the left-to-right order specified in the list. In secure-execution mode, preload pathnames containing slashes are ignored. Furthermore, shared objects are preloaded only from the standard search directories and only if they have set-user-ID mode bit enabled (which is not typical).
Within the names specified in the LD_PRELOAD list, the dynamic linker understands the tokens $ORIGIN, $LIB, and $PLATFORM (or the versions using curly braces around thenames) as described above in Dynamic string tokens. (See also the discussion of quoting under the description of LD_LIBRARY_PATH.)
There are various methods of specifying libraries to bepreloaded, and these are handled in the following order:
(1) The LD_PRELOAD environment variable.
(2) The —preload command-line option when invoking thedynamic linker directly.
(3) The /etc/ld.so.preload file (described below).
总结一下就是,可以让可执行文件最早地加载某一些动态链接库,就能使这里的native.so里的open等函数覆盖掉其他的open函数。所以这里的bmp-test用的libbmp所调用的fopen链接的是native.so里的fopen而不是libc里的fopen。
运行NSlider
首先实现一下miniSDL库里的函数,实际上这个miniSDL库和真正的SDL库的API还是不太相同的,比如SDL_BlitSurface在miniSDL库里的返回值类型就和真正的SDL库不一样,不过这都是小事情。
static void *get_pixel(const SDL_Surface *surface, int16_t x, int16_t y)
{
uint8_t bytes_per_pixel = surface->format->BytesPerPixel;
size_t offset = bytes_per_pixel * y * surface->w + bytes_per_pixel * x;
return (surface->pixels + offset);
}
void SDL_BlitSurface(SDL_Surface *src, SDL_Rect *srcrect, SDL_Surface *dst,
SDL_Rect *dstrect)
{
assert(dst && src);
assert(dst->format->BitsPerPixel == src->format->BitsPerPixel);
SDL_Rect default_srcrect = {0, 0, src->w, src->h};
if (!srcrect)
srcrect = &default_srcrect;
SDL_Rect default_dstrect = {0, 0, srcrect->w, srcrect->h};
if (!dstrect)
dstrect = &default_dstrect;
int16_t h = srcrect->h;
int16_t w = srcrect->w;
for (int16_t i = 0; i < h; i++)
{
for (int16_t j = 0; j < w; j++)
{
uint32_t *src_pixel =
get_pixel(src, srcrect->x + j, srcrect->y + i);
uint32_t *dst_pixel =
get_pixel(dst, dstrect->x + j, dstrect->y + i);
*dst_pixel = *src_pixel;
}
}
}
void SDL_UpdateRect(SDL_Surface *s, int x, int y, int w, int h)
{
assert(s);
if (!(x | y | w | h))
{
x = y = 0;
w = s->w;
h = s->h;
}
static uint32_t good_pixels[800 * 600];
for (int i = y; i < y + h; i++)
{
for (int j = x; j < x + w; j++)
{
int idx = (i - y) * w + j - x;
good_pixels[idx] = *(uint32_t *)get_pixel(s, j, i);
}
}
NDL_DrawRect((uint32_t *)s->pixels, x, y, w, h);
}然后是解决一下pdf转换的问题,实际上框架代码里给出的$NAVY_HOME/apps/nslider/slides/convert.sh几乎不能用,所以下面给出我的实现。我首先用一个python脚本把一个pdf的每一页转化为了bmp图像,然后再用bash把文件传到合适的地方:
import sys
from pdf2image import convert_from_path
from PIL import Image
pdf_path = "./slides.pdf"
pages = convert_from_path(pdf_path, dpi=300)
for i, page in enumerate(pages):
page_resized = page.resize((400, 300), Image.LANCZOS)
bmp_name = f"slides-{i}.bmp"
page_resized.save(bmp_name, "BMP")#!/bin/bash
python3 ./bmp-generator.py
mkdir -p $NAVY_HOME/fsimg/share/slides/
rm -f $NAVY_HOME/fsimg/share/slides/*
mv *.bmp $NAVY_HOME/fsimg/share/slides/所以说把一个pdf文件放到该目录下然后bash ./convert.sh就可以了,不过应当注意要把$NAVY_HOME/apps/nslider/src/main.cpp里面的常量N改为真实的bmp文件的数目,然后就可以启动了。

运行NSlider(2)
要明白SDL中的是如何打包事件的,主要要看懂这几个结构体和联合:
typedef struct {
uint8_t sym;
} SDL_keysym;
typedef struct {
uint8_t type;
SDL_keysym keysym;
} SDL_KeyboardEvent;
typedef struct {
uint8_t type;
int code;
void *data1;
void *data2;
} SDL_UserEvent;
typedef union {
uint8_t type;
SDL_KeyboardEvent key;
SDL_UserEvent user;
} SDL_Event;这里用了union的一些很有意思的小技巧,这里我把SDL_Event的前2字节画出来一下:
SDL_Event | 0~7 | 8~15 |
|---|---|---|
type | type | |
key | type | sym |
user | type | code |
所以说这里的type就可以判断SDL_Event的类型,然后SDL_KeyboardEvent后面的内容才是用来表示这个类型所对应的事件信息的。对于SDL_WaitEvent,它是一个忙等的函数,在实现的时候就拿一个循环一直读取键盘事件直到读到了为止。我的具体实现如下:
int SDL_WaitEvent(SDL_Event *event)
{
char buf[100];
int rd = NDL_PollEvent(buf, sizeof(buf) / sizeof(char));
while (rd == 0)
{
rd = NDL_PollEvent(buf, sizeof(buf) / sizeof(char));
}
if (buf[0] == 'k')
{
switch (buf[1])
{
case 'd':
event->key.type = SDL_KEYDOWN;
break;
case 'u':
event->key.type = SDL_KEYUP;
break;
default:
assert(0);
}
char *event_key_name = buf + 3;
buf[strlen(buf) - 1] = '\0';
for (int i = 0; i < sizeof(keyname) / sizeof(char *); i++)
{
if (strcmp(keyname[i], event_key_name) == 0)
{
event->key.keysym.sym = i;
break;
}
}
}
else
{
assert(0);
}
return 1;
}关于如何翻页:看一下源码中哪些地方会调用prev和next就懂了,实际上键位和vim差不多。下面是一个演示:
运行开机菜单
实现一个SDL_FillRect就好了:
void SDL_FillRect(SDL_Surface *dst, SDL_Rect *dstrect, uint32_t color)
{
assert(dst);
SDL_Rect default_rect = {0, 0, dst->w, dst->h};
if (!dstrect)
dstrect = &default_rect;
for (int16_t i = 0; i < dstrect->h; i++)
{
for (int16_t j = 0; j < dstrect->w; j++)
{
uint32_t *pixel = get_pixel(dst, dstrect->x + j, dstrect->y + i);
*pixel = color;
}
}
}演示如下:
运行NTerm
首先实现一下miniSDL库,SDL_GetTicks要求从SDL库初始化的时候开始计时,因此要在SDL_Init函数中先得到一开始的毫秒数,然后每次调用SDL_GetTicks的时候再减去初始值,这里就不多做赘述。
然后是SDL_PollEvent,它并不需要忙等,所以像下面这样实现就好:
int SDL_PollEvent(SDL_Event *ev)
{
char buf[100];
int rd = NDL_PollEvent(buf, sizeof(buf) / sizeof(char));
if (rd == 0)
return 0;
if (buf[0] == 'k')
{
switch (buf[1])
{
case 'd':
ev->key.type = SDL_KEYDOWN;
break;
case 'u':
ev->key.type = SDL_KEYUP;
break;
default:
assert(0);
}
char *event_key_name = buf + 3;
buf[strlen(buf) - 1] = '\0';
for (int i = 0; i < sizeof(keyname) / sizeof(char *); i++)
{
if (strcmp(keyname[i], event_key_name) == 0)
{
ev->key.keysym.sym = i;
break;
}
}
}
else
{
assert(0);
}
return 1;
}下面是演示:
实现内建的echo命令
阅读nterm的builtin-sh.cpp代码就会知道sh_handle_cmd就是用来出理每一条命令的。类似于我们在NEMU里面做的sdb,我们用相同的方式解析命令并执行命令:
static int sh_echo(char *cmd);
static struct {
const char *name;
const char *description;
int (*handler) (char *);
} cmd_table[] = {
{"echo", "display a line of text", sh_echo}
};
static int sh_echo(char *args)
{
sh_printf("%s", args);
return 0;
}
static void sh_handle_cmd(const char *cmd)
{
char *command = (char *)cmd;
char *first = strtok(command, " \n");
size_t arrlen = sizeof(cmd_table) / sizeof(cmd_table[0]);
char *args = first + strlen(first) + 1;
int i;
for (i = 0; i < arrlen; i++)
{
if (strcmp(first, cmd_table[i].name) == 0) {
cmd_table[i].handler(args);
break;
}
}
if (i == arrlen)
{
setenv("PATH", "/bin", 0);
execvp(first, NULL);
}
}这样就可以echo啦:
运行Flappy Bird
首先尝试一下在Linux上直接运行sdlbird,这需要我安装这些东西:
sudo apt install libsdl1.2-dev libsdl-image1.2-dev然后make run就可以运行了。
要在riscv32-nemu上运行,还需要实现IMG_Load,实现很简单,通过ftell得到图片文件大小之后在内存中开一段这么大的数组,然后再用STBIMG_LoadFromMemory加载到这个数组中:
SDL_Surface *IMG_Load(const char *filename)
{
FILE *f = fopen(filename, "rb");
fseek(f, 0, SEEK_END);
size_t f_sz = ftell(f);
uint8_t *buf = (uint8_t *)malloc(f_sz);
fseek(f, 0, SEEK_SET);
fread(buf, sizeof(uint8_t), f_sz, f);
fclose(f);
return STBIMG_LoadFromMemory(buf, f_sz);
}可以看到riscv32-NEMU的性能真的不咋的(太慢了),不过一方面也是因为我为了调试,让nanos-lite和navy上的程序都是-O0 -g进行编译的,没有做足够的优化。
我不是南京大学的学生, 如何获取仙剑奇侠传的数据文件?
https://www.52pojie.cn/thread-1011448-1-1.html
然后把这些数据包东拼西凑一下,就勉强能玩了。建议在下面实现代码前在Linux上先运行一下仙剑奇侠传,确保能玩之后再写,不然之后遇到bug可能是数据包的问题。
不过南京大学这个课程应该还会附加几个存档,这就无能为力了。
运行仙剑奇侠传
首先处理关于调色盘的问题,教程中已经说的很明确了,就是把颜色当作下标在调色盘里取值就可以了。不过这里建议在实现SDL_UpdateRect的时候先把整个屏幕换成32位颜色表示了再用NDL_DrawRect写进去,如果你是一个像素一个像素转换了就写的话,系统调用的次数过多,性能会特别差,根本玩不了。所以我们这样修改一下代码:
void SDL_BlitSurface(SDL_Surface *src, SDL_Rect *srcrect, SDL_Surface *dst,
SDL_Rect *dstrect)
{
assert(dst && src);
assert(dst->format->BitsPerPixel == src->format->BitsPerPixel);
SDL_Rect default_srcrect = {0, 0, src->w, src->h};
if (!srcrect)
srcrect = &default_srcrect;
SDL_Rect default_dstrect = {0, 0, srcrect->w, srcrect->h};
if (!dstrect)
dstrect = &default_dstrect;
int16_t h = srcrect->h;
int16_t w = srcrect->w;
int16_t map[256];
for (int i = 0; i < 256; i++)
map[i] = -1;
for (int16_t i = 0; i < h; i++)
{
for (int16_t j = 0; j < w; j++)
{
if (src->format->BitsPerPixel == 32)
{
uint32_t *src_pixel =
get_pixel(src, srcrect->x + j, srcrect->y + i);
uint32_t *dst_pixel =
get_pixel(dst, dstrect->x + j, dstrect->y + i);
*dst_pixel = *src_pixel;
}
else if (src->format->BitsPerPixel == 8)
{
uint8_t *src_pixel =
get_pixel(src, srcrect->x + j, srcrect->y + i);
uint8_t *dst_pixel =
get_pixel(dst, dstrect->x + j, dstrect->y + i);
if (map[*src_pixel] == -1)
{
uint32_t src_color =
src->format->palette->colors[*src_pixel].val;
for (int k = 0; k < dst->format->palette->ncolors; k++)
{
if (dst->format->palette->colors[k].val == src_color)
{
*dst_pixel = k;
map[*src_pixel] = k;
break;
}
}
}
else
{
*dst_pixel = map[*src_pixel];
}
}
else
{
assert(0);
}
}
}
}
void SDL_FillRect(SDL_Surface *dst, SDL_Rect *dstrect, uint32_t color)
{
assert(dst);
SDL_Rect default_rect = {0, 0, dst->w, dst->h};
if (!dstrect)
dstrect = &default_rect;
uint8_t color_idx = -1;
if (dst->format->BitsPerPixel == 8)
{
for (int i = 0; i < dst->format->palette->ncolors; i++)
{
if (dst->format->palette->colors[i].val == color)
{
color_idx = i;
break;
}
}
}
for (int16_t i = 0; i < dstrect->h; i++)
{
for (int16_t j = 0; j < dstrect->w; j++)
{
if (dst->format->BitsPerPixel == 32)
{
uint32_t *pixel =
get_pixel(dst, dstrect->x + j, dstrect->y + i);
*pixel = color;
}
else if (dst->format->BitsPerPixel == 8)
{
uint8_t *pixel = get_pixel(dst, dstrect->x + j, dstrect->y + i);
*pixel = color_idx;
}
else
{
assert(0);
}
}
}
}
void SDL_UpdateRect(SDL_Surface *s, int x, int y, int w, int h)
{
TimerCallbackHelper();
AudioCallbackHelper();
assert(s);
if (!(x | y | w | h))
{
x = y = 0;
w = s->w;
h = s->h;
}
static uint32_t good_pixels[800 * 600];
if (s->format->BitsPerPixel == 32)
{
for (int i = y; i < y + h; i++)
{
for (int j = x; j < x + w; j++)
{
int idx = (i - y) * w + j - x;
good_pixels[idx] = *(uint32_t *)get_pixel(s, j, i);
}
}
NDL_DrawRect(good_pixels, x, y, w, h);
}
else if (s->format->BitsPerPixel == 8)
{
assert(s->format->palette->ncolors == 256);
static uint32_t new_pixels[400 * 300];
for (int i = y; i < y + h; i++)
{
for (int j = x; j < x + w; j++)
{
uint8_t *pixel = get_pixel(s, j, i);
uint32_t real_pixel = s->format->palette->colors[*pixel].val;
new_pixels[(i - y) * w + j - x] = real_pixel;
}
}
ConvertPixelsARGB_ABGR(good_pixels, new_pixels, w * h);
NDL_DrawRect(good_pixels, x, y, w, h);
}
else
{
assert(0);
}
}注意到高亮行的内容,这行的意思是把new_pixels里面的颜色的R域和B域进行调换,然后放到good_pixels。原因是仙剑奇侠传里调色盘里的颜色摆放顺序和我们NEMU的VGA的颜色摆放顺序不同,所以要做这么个转换:
| color | 0~7 | 8~15 | 16~23 | 24~31 |
|---|---|---|---|---|
| palette | r | g | b | a |
| vga | b | g | r | a |
否则,你看到的仙剑奇侠传的颜色可能有点诡异,甚至有点阴森恐怖:
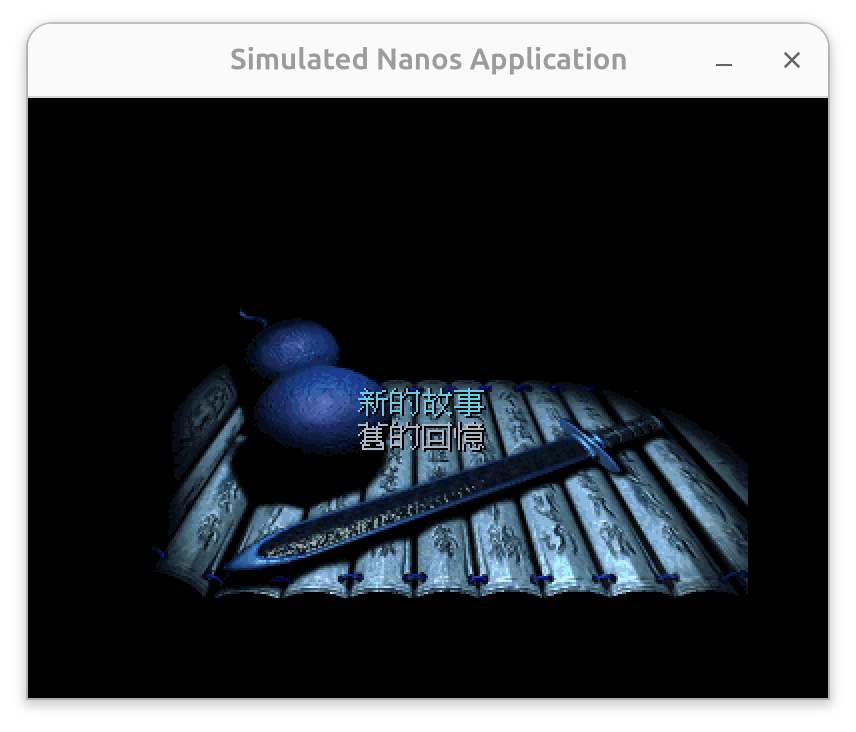 而正常的应该是这样:
而正常的应该是这样:
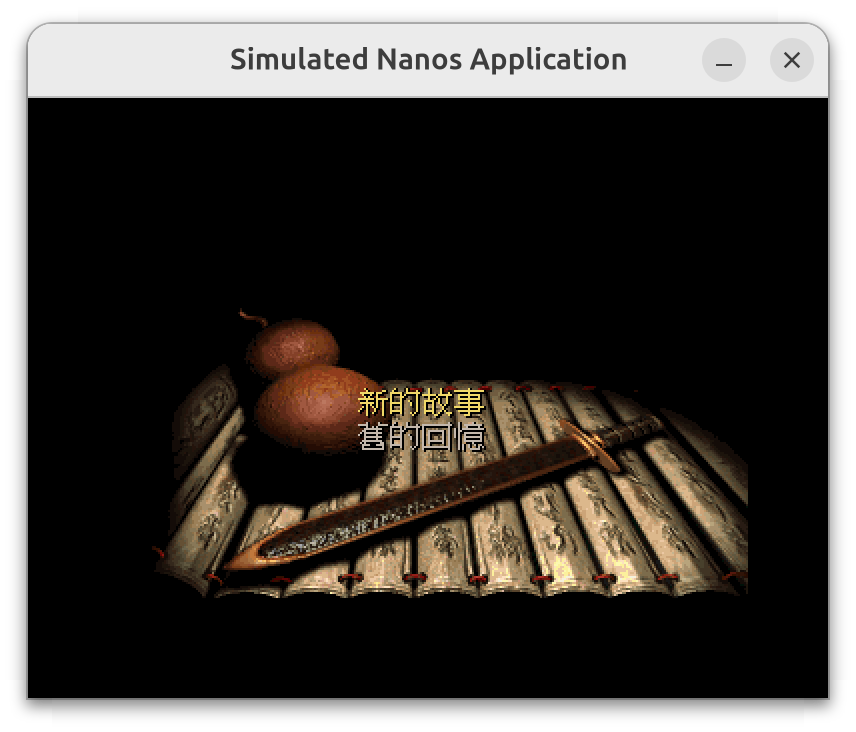 此外还需要实现两个API:
此外还需要实现两个API:SDL_GetKeyState与SDL_Delay。后者很简单,用SDL_GetTicks忙等就可以了。但是前一个需要稍微改动一下之前的代码,即在SDL_PollEvent和SDL_WaitEvent拿到一个键盘事件后更新键盘状态即可,我是这样实现的:
uint8_t key_state[SDLK_PAGEDOWN + 1] = {0};
int analyze_event(char *buf, SDL_Event *ev)
{
if (buf[0] == 'k')
{
switch (buf[1])
{
case 'd':
ev->key.type = SDL_KEYDOWN;
break;
case 'u':
ev->key.type = SDL_KEYUP;
break;
default:
assert(0);
}
char *event_key_name = buf + 3;
buf[strlen(buf) - 1] = '\0';
for (int i = 0; i < sizeof(keyname) / sizeof(char *); i++)
{
if (strcmp(keyname[i], event_key_name) == 0)
{
ev->key.keysym.sym = i;
break;
}
}
key_state[ev->key.keysym.sym] = (ev->key.type == SDL_KEYDOWN);
}
else
{
assert(0);
}
return 1;
}
...
uint8_t *SDL_GetKeyState(int *numkeys)
{
return key_state;
}下面就可以在高达4FPS的帧率下极致畅玩了:
仙剑奇侠传的框架是如何工作的?
看$NAVY_HOME/apps/pal/repo/src/game/play.c,等待帧和获取输入在PAL_DelayUntil函数里,每一帧的渲染工作在PAL_StartFrame函数里,更新游戏逻辑在这个PAL_StartFrame开头调用的PAL_GameUpdate函数里。
突然注意到pal的源码中有个PAL_FadeIn函数,这是用来做渐入效果的:
VOID
PAL_FadeIn(
INT iPaletteNum,
BOOL fNight,
INT iDelay
)
/*++
Purpose:
Fade in the screen to the specified palette.
Parameters:
[IN] iPaletteNum - number of the palette.
[IN] fNight - whether use the night palette or not.
[IN] iDelay - delay time for each step.
Return value:
None.
--*/
{
int i, j;
UINT time;
SDL_Color *palette;
PAL_LARGE SDL_Color *newpalette = malloc(sizeof(newpalette[0]) * 256);
//
// Get the new palette...
//
palette = PAL_GetPalette(iPaletteNum, fNight);
//
// Start fading in...
//
time = SDL_GetTicks() + iDelay * 10 * 60;
while (TRUE)
{
//
// Set the current palette...
//
j = (int)(time - SDL_GetTicks()) / iDelay / 10;
if (j < 0)
{
break;
}
j = 60 - j;
for (i = 0; i < 256; i++)
{
newpalette[i].r = (palette[i].r * j) >> 6;
newpalette[i].g = (palette[i].g * j) >> 6;
newpalette[i].b = (palette[i].b * j) >> 6;
}
VIDEO_SetPalette(newpalette);
UTIL_Delay(10);
}
VIDEO_SetPalette(palette);
free(newpalette);
}这个循环里的内容无疑证明了我之前的猜想,这个效果就是通过换调色盘做出来的。
仙剑奇侠传的脚本引擎
我并没有得到任何新的认识,因为我之前根本不认识游戏引擎。
感觉脚本引擎就和一个NEMU差不多,NEMU会一条条解释指令并执行,相似的,PAL_InterpretInstruction做的事情就是解析其中的一条脚本命令,根据这个命令的操作码和附带的目标物,然后对它做相应的动作,也就是更改了游戏的状态,然后再指向下一个指令。
这样游戏开发者就不用把游戏逻辑写死在代码里,可以把基本逻辑固定下来,其他的就可以写成脚本,然后用这种解释的方式进行运行,这样能方便更改游戏逻辑。
不再神秘的秘技
猜测是因为整型溢出、类型不匹配导致的一些神奇的Bug,pal源码太长了看不下去,所以没得到具体代码的证实。
实现Navy上的AM
看起来有点惊人,不过这确实是可以实现的,我们不妨整理一下程序的依赖关系:
AM应用程序 -> libam -> Navy运行时环境(Newlib,libndl)-> nanos-lite -> …
而目前AM应用程序本身用的是AM的环境,所以我们在libam里做的事情就是用Newlib、libndl实现AM的环境,包装成一个libam静态库,让AM应用程序调用库里的函数即可。AM环境里的klib可以直接用Newlib替代了,需要我们另外实现的其实也就只有IOE和TRM的部分。TRM的_trm_init也不用另外实现,这是因为在Navy环境下有libos,这个libos中有提供一个类似的call_main函数用于启动程序。
了解了整个架构,具体实现其实一点儿都不难,下面给出libam的IOE中的gpu,input,timer和TRM的实现,其他的很简单就不多做赘述:
#include <am.h>
#include <stdio.h>
#include <stdlib.h>
Area heap;
void putch(char ch)
{
putchar(ch);
}
void halt(int code)
{
exit(code);
}#include <NDL.h>
#include <am.h>
#include <stdlib.h>
static int width = 0, height = 0;
static uint32_t *buf = NULL;
void __am_gpu_init()
{
NDL_OpenCanvas(&width, &height);
buf = malloc(width * height * 4);
memset(buf, 0, width * height * 4);
}
void __am_gpu_config(AM_GPU_CONFIG_T *cfg)
{
*cfg = (AM_GPU_CONFIG_T){.present = true,
.has_accel = false,
.width = width,
.height = height,
.vmemsz = width * height * 4};
}
void __am_gpu_fbdraw(AM_GPU_FBDRAW_T *ctl)
{
uint32_t *pixels = (uint32_t *)ctl->pixels;
for (int j = ctl->y; j < ctl->y + ctl->h; j++)
{
for (int i = ctl->x; i < ctl->x + ctl->w; i++)
{
buf[j * width + i] = pixels[(j - ctl->y) * ctl->w + i - ctl->x];
}
}
if (ctl->sync)
{
NDL_DrawRect(buf, 0, 0, width, height);
}
}
void __am_gpu_status(AM_GPU_STATUS_T *status)
{
status->ready = true;
}#include <NDL.h>
#include <am.h>
#include <assert.h>
#include <string.h>
#define keyname(k) #k,
static const char *keyname[] = {"NONE", AM_KEYS(keyname)};
void __am_input_config(AM_INPUT_CONFIG_T *cfg)
{
cfg->present = true;
}
void __am_input_keybrd(AM_INPUT_KEYBRD_T *kbd)
{
char buf[100];
int ret = NDL_PollEvent(buf, 99);
if (ret == 0)
{
kbd->keycode = AM_KEY_NONE;
kbd->keydown = false;
}
else
{
if (buf[0] == 'k')
{
switch (buf[1])
{
case 'd':
kbd->keydown = true;
break;
case 'u':
kbd->keydown = false;
break;
default:
assert(0);
}
char *event_key_name = buf + 3;
buf[strlen(buf) - 1] = '\0';
for (int i = 0; i < sizeof(keyname) / sizeof(char *); i++)
{
if (strcmp(keyname[i], event_key_name) == 0)
{
kbd->keycode = i;
break;
}
}
}
else
{
assert(0);
}
}
}#include <NDL.h>
#include <am.h>
void __am_timer_config(AM_TIMER_CONFIG_T *cfg)
{
cfg->present = true;
cfg->has_rtc = true;
}
void __am_timer_rtc(AM_TIMER_RTC_T *rtc)
{
rtc->second = 0;
rtc->minute = 0;
rtc->hour = 0;
rtc->day = 0;
rtc->month = 0;
rtc->year = 1900;
}
void __am_timer_uptime(AM_TIMER_UPTIME_T *uptime)
{
uptime->us = NDL_GetTicks() * 1000;
}在Navy中运行microbench
比如我们以make ISA=native ALL=microbench run来运行,程序会在读取main函数的唯一的参数args的地方崩溃。其原因是AM中对main函数的定义并不标准。具体而言,我们在native下链接的时候,GCC会认为的main函数原型应该是这样的:int main(int argc, char *argv[], char *envp[]),所以实际传给main函数的参数排布也是这样子的。然而在microbench中的main是这个样子int main(const char *args),就会导致拿到的args是一个异常值。
而如果是在riscv32-nemu上的nanos-lite中运行,同样的道理,也会导致拿到的args是一个异常值。不过恰好在$NAVY_HOME/libs/libos/src/crt0/crt0.c的实现中,传给main的参数全是0,这就使得microbench程序拿到的也是0,正好让它变成空指针,让microbench自动选择ref模式了,反而能跑。🤣
不过除此之外microbench还会有问题:它的内存申请方式不是用malloc/free,而是直接操作图灵机的heap。因此我们开一个足够大的内存作为在Navy上虚拟出来的一个heap:
static constexpr size_t HEAP_SIZE = 1024 * 1024 * 4;
static uint32_t heap_buf[HEAP_SIZE];
Area heap = RANGE(heap_buf, heap_buf + HEAP_SIZE);这样microbench就可以跑起来了,我的跑分是534分。
运行FCEUX
FCEUX和microbench一样,都有main函数不标准的问题。不过由于Navy支持文件系统,所以我们完全可以在Makefile里面去掉宏__NO_FILE_SYSTEM__,然后就会变成正常的main函数了。不过这样会使得FCEUX会使用超过TRM的东西(比如文件读写),但是无所谓了,毕竟这样功能更全面。
#ifdef __NO_FILE_SYSTEM__
int main(const char *romname)
#else
int main(int argc, char *argv[])
#endif注意到框架代码里有如下配置:
#if defined(__ARCH_NATIVE) || defined(__PLATFORM_QEMU)
#define PERF_CONFIG PERF_HIGH
#elif defined(__PLATFORM_NEMU)
#define PERF_CONFIG PERF_MIDDLE
#else
#define PERF_CONFIG PERF_LOW
#endif
#if PERF_CONFIG == PERF_HIGH
#define NR_FRAMESKIP 0
#define SOUND_CONFIG SOUND_HQ
#define FUNC_IDX_MAX256
#elif PERF_CONFIG == PERF_MIDDLE
#define NR_FRAMESKIP 1
#define SOUND_CONFIG SOUND_LQ
#define FUNC_IDX_MAX256
#else
#define NR_FRAMESKIP 2
#define SOUND_CONFIG SOUND_NONE
#define FUNC_IDX_MAX16
#endif这就意味着如果我们以Navy的环境运行,编译的时候只会定义一个__ISA_NATIVE__,这将导致上面的代码确定PERF_CONFIG是PERF_LOW,进而在高亮处定义一个FUNC_IDX_MAX16,这会导致游戏里面一个注册函数的模块因为BWrite数组不够大而报错:
static int RegisterBWrite(writefunc func) {
int i;
for (i = 0; i < FUNC_IDX_MAX; i ++) {
if (BWrite[i] == NULL) BWrite[i] = func;
if (BWrite[i] == func) return i;
}
assert(i < FUNC_IDX_MAX);
return -1;
}所以我把这个FUNC_IDX_MAX16改成了FUNC_IDX_MAX256,就能够在$NAVY_HOME/apps/fceux下以make ISA=native run运行FCEUX了。这里有个小提示,在编译的时候添上-g3,就可以在GDB里通过info macro xxx查看xxx这个宏的值。
下面是让FCEUX运行在riscv32-nemu上的nanos-lite上的Navy上的真实影像,真的很卡:
如何在Navy上运行Nanos-lite?
难点在于CTE,也就是用来注册事件处理函数的cte_init。一个比较粗暴的方式就是把“启动一个事件”和“接收一个事件”用函数链接的形式做出来,这种方法很简单但是不太安全。还有个方式是在nanos-lite中做一个新的系统调用,这个系统调用的语义逻辑就是根据传入的事件信息用事件处理函数进行处理。
诞生于”未来”的游戏
在native上的Navy上挺好玩的,因为不卡。当然在riscv32-nemu上的nanos-lite上也是可以玩的,不过要注意这些文件有点多,要防止生成的ramdisk.img过大。
这是171240518这个游戏的一个胜利结算:
RTFSC???
感觉这些代码的生成过程就是用PA1表达式求值里的token分析类似的方法获取源代码的各个符号,然后把各个符号用乱码进行一个整体的替换。但是AM那些接口函数没变,所以我由此发现了我的TRM的申请内存的一个小bug。
运行NPlayer
已知要实现在NPlayer中播放音频需要经过如下的层次:
NPlayer->Navy(libminiSDL, libndl)->nanos-lite(syscall, fs, device)->AM->…
AM以及右边的已经在PA2都实现了,首先需要在nanos-lite中的VFS中添加教程中所规定的两个设备:
Finfo file_table[] __attribute__((used)) = {
[FD_STDIN] = {"stdin", 0, 0, 0, 1, invalid_read, invalid_write},
[FD_STDOUT] = {"stdout", 0, 0, 0, 1, invalid_read, serial_write},
[FD_STDERR] = {"stderr", 0, 0, 0, 1, invalid_read, serial_write},
[FD_FBINFO] = {"/proc/dispinfo", 0, 0, 0, 1, dispinfo_read, invalid_write},
[FD_EVENT] = {"/dev/events", 0, 0, 0, 1, events_read, invalid_write},
[FD_FB] = {"/dev/fb", 0, 0, 0, 0, invalid_read, fb_write},
[FD_SB] = {"/dev/sb", 0, 0, 0, 1, invalid_read, sb_write},
[FD_SBCTL] = {"/dev/sbctl", 0, 0, 0, 1, sbctl_read, sbctl_write},
#include "files.h"
};然后就是具体实现对/dev/sb和/dev/sbctl的IO操作,需要注意的是教程中介绍/dev/sbctl的有句话很具有迷惑性:
读出时用于查询声卡设备的状态, 应用程序可以读出一个
int整数, 表示当前声卡设备流缓冲区的空闲字节数. 该设备不支持lseek.
这里所说的“应用程序可以读出一个int整数”,指的是nanos-lite提供的是这个整数的字符串表示,而非是一个int32_t!所以下面的实现中我用sprintf把数字以字符串的形式写到了buf中。
具体实现如下:
static int sb_size = -1;
size_t sb_write(const void *buf, size_t offset, size_t len)
{
io_write(AM_AUDIO_PLAY, {(void *)buf, (void *)buf + len});
return len;
}
size_t sbctl_read(void *buf, size_t offset, size_t len)
{
int32_t free = sb_size - io_read(AM_AUDIO_STATUS).count;
int ret = sprintf(buf, "%d", free);
return ret;
}
size_t sbctl_write(const void *buf, size_t offset, size_t len)
{
assert(len == 12);
uint32_t *ctl_buf = (uint32_t *)buf;
io_write(AM_AUDIO_CTRL, ctl_buf[0], ctl_buf[1], ctl_buf[2]);
return len;
}
void init_device()
{
Log("Initializing devices...");
ioe_init();
AM_GPU_CONFIG_T gpu_conf = io_read(AM_GPU_CONFIG);
screen_width = gpu_conf.width;
screen_height = gpu_conf.height;
AM_AUDIO_CONFIG_T audio_conf = io_read(AM_AUDIO_CONFIG);
sb_size = audio_conf.bufsize;
}这样,应用程序就可以通过调用SYS_write和SYS_read系统调用来使用音频设备了。所以现在实现一下libndl,包装一下调用系统调用的过程。
void NDL_OpenAudio(int freq, int channels, int samples)
{
uint32_t buf[3] = {freq, channels, samples};
write(sbctldev, buf, sizeof(buf));
}
void NDL_CloseAudio()
{
}
int NDL_PlayAudio(void *buf, int len)
{
return write(sbdev, buf, len);
}
int NDL_QueryAudio()
{
char buf[100];
read(sbctldev, buf, sizeof(buf));
int32_t count = 0;
for (int i = 0; i < sizeof(buf); i++)
{
if (buf[i] == 0)
break;
count *= 10;
count += (buf[i] - '0');
}
return count;
}接下来就是实现libminiSDL,其实现并不复杂:
SDL_AudioSpec audiospec;
bool pause = true;
int SDL_OpenAudio(SDL_AudioSpec *desired, SDL_AudioSpec *obtained)
{
NDL_OpenAudio(desired->freq, desired->channels, desired->samples);
audiospec = *desired;
if (obtained)
{
*obtained = *desired;
}
return 0;
}
void SDL_CloseAudio()
{
pause = true;
}
void SDL_PauseAudio(int pause_on)
{
pause = pause_on;
}难点在于用户程序传入给SDL_OpenAudio的参数desire中的callback回调函数。首先明确一下这个回调函数的意义:SDL库会周期性调用这个回调函数,然后用户的回调函数实现就会把len长度的音频数据放到stream指向的内存区域里,因此SDL库访问stream就可以知道用户想要播放的音频数据了。
那第一个问题就是周期性调用的周期是多少?首先通过这篇文章了解一下freq,samples和channels是什么意思。看完文章后就能知道一次回调函数实质上就得到了一个音频帧。所以设调用回调函数的周期是,单位是秒,则根据简单的数学知识,有:
这样就可以计算出的值了,不过我在实现中用的是毫秒为单位,这样和NDL_GetTicks对得上。
第二个问题在于如何定时调用回调函数。在这里教程中说可以实现一个辅助函数,然后尽可能在miniSDL库中经常调用,就假装像是有信号机制,会定时运行似的。所以就按教程这样来吧:
SDL_AudioSpec audiospec;
bool pause = true;
uint32_t callback_cycle; // ms
uint32_t last_call_time = 0; // ms
static uint8_t *frame;
static int frame_size = 0;
void CallbackHelper()
{
uint32_t current = NDL_GetTicks();
if (current - last_call_time < callback_cycle || pause)
return;
int len = NDL_QueryAudio();
if (len > frame_size)
len = frame_size;
audiospec.callback(audiospec.userdata, frame, len);
NDL_PlayAudio(frame, len);
last_call_time = current;
}
int SDL_OpenAudio(SDL_AudioSpec *desired, SDL_AudioSpec *obtained)
{
NDL_OpenAudio(desired->freq, desired->channels, desired->samples);
audiospec = *desired;
if (obtained)
{
*obtained = *desired;
}
callback_cycle = (int32_t)audiospec.samples * 1000 / audiospec.freq;
last_call_time = NDL_GetTicks();
frame_size = audiospec.samples * audiospec.channels * sizeof(int16_t);
frame = malloc(frame_size);
return 0;
}
void SDL_CloseAudio()
{
pause = true;
free(frame);
}在尝试运行NPlayer时,发现了它所调用的vorbis可以检查出差劲的fixedpt_div的实现:好的实现一定是先乘再除的,不然如果先除后乘,因为C语言的除法是整除,那么一旦,那直接就变成了,小数部分就没了。
可通过键盘的等于号和减号进行音量加减。
播放自己喜欢的音乐
来点朝鲜🇰🇵金曲,不过在nanos-lite上是真的有点卡,所以我选择在native上运行:
让运行时环境支持C++全局对象的初始化
单完成这个任务是非常简单的,教程已经说的很明白了,Newlib里已经定义了一个会调用C++的全局对象的构造函数的函数__libc_init_array了,所以在$NAVY_HOME/libs/libos/src/crt0/crt0.c调用main函数前调用__libc_init_array就可以了。
在nanos-lite上正确的输入如下:
Test,8: Hello, Project-N!
main,20: Hello world!
~Test,12: Goodbye, Project-N!
理解全局对象构造函数的调用过程
首先我们可以看一下编译器编译出来的main.o的反汇编究竟长什么样。首先我们能够确定在它的.text段里肯定会有main函数的定义,然后会发现除了main之外还多了两个函数,猜测这可能会与全局变量test的初始化有关:
00000044 <_Z41__static_initialization_and_destruction_0v>:
44: ff010113 addi sp,sp,-16
48: 00112623 sw ra,12(sp)
4c: 00812423 sw s0,8(sp)
50: 01010413 addi s0,sp,16
54: 00000517 auipc a0,0x0
58: 00050513 mv a0,a0
5c: 00000097 auipc ra,0x0
60: 000080e7 jalr ra # 5c <_Z41__static_initialization_and_destruction_0v+0x18>
64: 00000617 auipc a2,0x0
68: 00060613 mv a2,a2
6c: 00000597 auipc a1,0x0
70: 00058593 mv a1,a1
74: 00000517 auipc a0,0x0
78: 00050513 mv a0,a0
7c: 00000097 auipc ra,0x0
80: 000080e7 jalr ra # 7c <_Z41__static_initialization_and_destruction_0v+0x38>
84: 00000013 nop
88: 00c12083 lw ra,12(sp)
8c: 00812403 lw s0,8(sp)
90: 01010113 addi sp,sp,16
94: 00008067 ret
00000098 <_GLOBAL__sub_I_test>:
98: ff010113 addi sp,sp,-16
9c: 00112623 sw ra,12(sp)
a0: 00812423 sw s0,8(sp)
a4: 01010413 addi s0,sp,16
a8: 00000097 auipc ra,0x0
ac: 000080e7 jalr ra # a8 <_GLOBAL__sub_I_test+0x10>
b0: 00c12083 lw ra,12(sp)
b4: 00812403 lw s0,8(sp)
b8: 01010113 addi sp,sp,16
bc: 00008067 ret接下来看链接后的产物cpp-test-riscv32的反汇编:
83000118 <_Z41__static_initialization_and_destruction_0v>:
83000118: ff010113 addi sp,sp,-16
8300011c: 00112623 sw ra,12(sp)
83000120: 00812423 sw s0,8(sp)
83000124: 01010413 addi s0,sp,16
83000128: 00009517 auipc a0,0x9
8300012c: 77050513 addi a0,a0,1904 # 83009898 <test>
83000130: 00000097 auipc ra,0x0
83000134: 064080e7 jalr 100(ra) # 83000194 <_ZN4TestC1Ev>
83000138: 00009617 auipc a2,0x9
8300013c: 76460613 addi a2,a2,1892 # 8300989c <__dso_handle>
83000140: 00009597 auipc a1,0x9
83000144: 75858593 addi a1,a1,1880 # 83009898 <test>
83000148: 00000517 auipc a0,0x0
8300014c: 09050513 addi a0,a0,144 # 830001d8 <_ZN4TestD1Ev>
83000150: 00000097 auipc ra,0x0
83000154: 164080e7 jalr 356(ra) # 830002b4 <__cxa_atexit>
83000158: 00000013 nop
8300015c: 00c12083 lw ra,12(sp)
83000160: 00812403 lw s0,8(sp)
83000164: 01010113 addi sp,sp,16
83000168: 00008067 ret
8300016c <_GLOBAL__sub_I_test>:
8300016c: ff010113 addi sp,sp,-16
83000170: 00112623 sw ra,12(sp)
83000174: 00812423 sw s0,8(sp)
83000178: 01010413 addi s0,sp,16
8300017c: 00000097 auipc ra,0x0
83000180: f9c080e7 jalr -100(ra) # 83000118 <_Z41__static_initialization_and_destruction_0v>
83000184: 00c12083 lw ra,12(sp)
83000188: 00812403 lw s0,8(sp)
8300018c: 01010113 addi sp,sp,16
83000190: 00008067 ret
83000194 <_ZN4TestC1Ev>:
83000194: fe010113 addi sp,sp,-32
83000198: 00112e23 sw ra,28(sp)
8300019c: 00812c23 sw s0,24(sp)
830001a0: 02010413 addi s0,sp,32
830001a4: fea42623 sw a0,-20(s0)
830001a8: 00800613 li a2,8
830001ac: 00006597 auipc a1,0x6
830001b0: 0e858593 addi a1,a1,232 # 83006294 <__libc_init_array+0x94>
830001b4: 00006517 auipc a0,0x6
830001b8: 0e850513 addi a0,a0,232 # 8300629c <__libc_init_array+0x9c>
830001bc: 00000097 auipc ra,0x0
830001c0: 0a4080e7 jalr 164(ra) # 83000260 <printf>
830001c4: 00000013 nop
830001c8: 01c12083 lw ra,28(sp)
830001cc: 01812403 lw s0,24(sp)
830001d0: 02010113 addi sp,sp,32
830001d4: 00008067 ret
830001d8 <_ZN4TestD1Ev>:
830001d8: fe010113 addi sp,sp,-32
830001dc: 00112e23 sw ra,28(sp)
830001e0: 00812c23 sw s0,24(sp)
830001e4: 02010413 addi s0,sp,32
830001e8: fea42623 sw a0,-20(s0)
830001ec: 00c00613 li a2,12
830001f0: 00006597 auipc a1,0x6
830001f4: 0c858593 addi a1,a1,200 # 830062b8 <__libc_init_array+0xb8>
830001f8: 00006517 auipc a0,0x6
830001fc: 0c850513 addi a0,a0,200 # 830062c0 <__libc_init_array+0xc0>
83000200: 00000097 auipc ra,0x0
83000204: 060080e7 jalr 96(ra) # 83000260 <printf>
83000208: 00000013 nop
8300020c: 01c12083 lw ra,28(sp)
83000210: 01812403 lw s0,24(sp)
83000214: 02010113 addi sp,sp,32
83000218: 00008067 ret可以看到这里的逻辑是:首先_GLOBAL__sub_I_test调用了_Z41__static_initialization_and_destruction_0v这个函数,然后这个函数会用到_ZN4TestC1Ev和_ZN4TestD1Ev这两个函数。这两个函数看上去很有可能是构造函数与析构函数,因为他们都调用了printf函数。通过看ELF文件的二进制数据,结合传给printf的参数也证实了这一点:
00006290: 6780 0000 5465 7374 0000 0000 2573 2c25 g...Test....%s,%
000062a0: 643a 2048 656c 6c6f 2c20 5072 6f6a 6563 d: Hello, Projec
000062b0: 742d 4e21 0a00 0000 7e54 6573 7400 0000 t-N!....~Test...
000062c0: 2573 2c25 643a 2047 6f6f 6462 7965 2c20 %s,%d: Goodbye,
000062d0: 5072 6f6a 6563 742d 4e21 0a00 6d61 696e Project-N!..main于是我们就可以知道调用了_GLOBAL__sub_I_test就可以确保调用了全局变量的构造函数并且注册全局变量的析构函数。也就是说这个函数应该就是教程中介绍的g++所包装出来的一个辅助函数。那么现在注意到这个符号的Bind属性,问题就来了:它是LOCAL的,这意味着Newlib之类的库是无法找到这个函数的:
Num: Value Size Type Bind Vis Ndx Name
43: 00000098 40 FUNC LOCAL DEFAULT 33 _GLOBAL__sub_I_test
所以,链接器就会把这个辅助函数的地址填写到一个.init_array的节中:
Disassembly of section .init_array:
83008ffc <__init_array_start>:
83008ffc: 016c .insn 2, 0x016c
83008ffe: 8300 .insn 2, 0x8300这里反汇编程序无法识别这个指令,这很正常,因为这实际上保存的是_GLOBAL__sub_I_test函数的地址,因为是小端机器,所以拼一下就是0x8300016c这个地址了。同时链接器还定义了这么一些符号:
147: 83009000 0 NOTYPE LOCAL DEFAULT 4 __init_array_end
148: 83008ffc 0 NOTYPE LOCAL DEFAULT 4 __preinit_array_end
149: 83008ffc 0 NOTYPE LOCAL DEFAULT 4 __init_array_start
150: 83008ffc 0 NOTYPE LOCAL DEFAULT 4 __preinit_array_start
于是,这些符号就被Newlib用于遍历辅助函数进而调用全局变量的构造函数了:
#ifdef HAVE_INITFINI_ARRAY
/* These magic symbols are provided by the linker. */
extern void (*__preinit_array_start[])(void) __attribute__((weak));
extern void (*__preinit_array_end[])(void) __attribute__((weak));
extern void (*__init_array_start[])(void) __attribute__((weak));
extern void (*__init_array_end[])(void) __attribute__((weak));
#ifdef HAVE_INIT_FINI
extern void _init(void);
#endif
/* Iterate over all the init routines. */
void __libc_init_array(void)
{
size_t count;
size_t i;
count = __preinit_array_end - __preinit_array_start;
for (i = 0; i < count; i++)
__preinit_array_start[i]();
#ifdef HAVE_INIT_FINI
_init();
#endif
count = __init_array_end - __init_array_start;
for (i = 0; i < count; i++)
__init_array_start[i]();
}
#endif运行带音乐和音效的仙剑奇侠传
比如这个调用链条是这样的:
A -> B -> A -> B -> …
那么只需要在B里面添加一个标志,若标志为1则表示不可继续执行。那么在我们的实现中在其第一次运行时标为1,则在第二次时就不可以继续运行下去,便防止了重入问题。虽然可以在nanos-lite上跑,但是实在是太卡了,所以还是在native上演示一下
运行带音效的Flappy Bird
首先实现一下SDL_LoadWAV,这需要我们看看教程上的网站稍微了解了WAV文件格式。因为本课程中的wav文件都是非压缩的PCM格式,所以我们甚至只需要从文件的第44字节开始读到文件尾作为音频数据,然后再读一下频率、通道数和其他一些参数即可。不过我在这里为了保险还是做了很多的assert:
SDL_AudioSpec *SDL_LoadWAV(const char *file, SDL_AudioSpec *spec,
uint8_t **audio_buf, uint32_t *audio_len)
{
FILE *f = fopen(file, "rb");
char type_buf[10] = {0};
fread(type_buf, 1, 4, f);
assert(strcmp(type_buf, "RIFF") == 0);
uint32_t data_size = 0;
fread(&data_size, 4, 1, f);
data_size -= 36;
memset(type_buf, 0, 10);
fread(type_buf, 1, 4, f);
assert(strcmp(type_buf, "WAVE") == 0);
long chunk1_off = 12;
long chunk2_off = 36;
memset(type_buf, 0, 10);
fread(type_buf, 1, 4, f);
assert(strcmp(type_buf, "fmt ") == 0);
memset(type_buf, 0, 10);
fseek(f, 20, SEEK_SET);
uint16_t audio_format;
fread(&audio_format, 2, 1, f);
assert(audio_format == 1);
uint16_t channels;
fread(&channels, 2, 1, f);
spec->channels = channels;
uint32_t freq;
fread(&freq, 4, 1, f);
spec->freq = freq;
fseek(f, 6, SEEK_CUR);
uint16_t bits_per_sample;
fread(&bits_per_sample, 2, 1, f);
if (bits_per_sample == 8)
spec->format = AUDIO_S16;
else if (bits_per_sample == 16)
spec->format = AUDIO_U8;
else
assert(0);
spec->samples = 1024;
fseek(f, chunk2_off, SEEK_SET);
fread(type_buf, 1, 4, f);
assert(strcmp(type_buf, "data") == 0);
fseek(f, 44, SEEK_SET);
uint8_t *data_buf = malloc(data_size);
fread(data_buf, 1, data_size, f);
*audio_buf = data_buf;
*audio_len = data_size;
return spec;
}需要注意的是函数参数uint8_t **audio_buf的意思,不是让我们往里面传数据,而是自己申请内存把音频数据放里面,然后把*audio_buf这个指针直接改了。
接着是处理SDL_MixAudio的实现,具体而言就是把源音频先做一个与音量相关的比例调整(乘法),再和目标音频做加法。因为要处理溢出问题,所以我这里直接用int去存储中间值,就能很好判断溢出了。不过我这里只能处理16位有符号格式的音频,因为我不清楚单靠这个函数如何分辨出指针指向的音频是什么格式的。
void SDL_MixAudio(uint8_t *dst, uint8_t *src, uint32_t len, int volume)
{
assert(len % 2 == 0);
int16_t *ddst = (int16_t *)dst;
int16_t *ssrc = (int16_t *)src;
for (size_t i = 0; i < len / 2; i++)
{
int ssrc_vol = (int)ssrc[i] * (int)volume / (int)SDL_MIX_MAXVOLUME;
int mixed = (int)ddst[i] + ssrc_vol;
uint16_t val;
if (mixed > 32767)
val = 32767;
else if (mixed < -32768)
val = -32768;
else
val = mixed;
ddst[i] = val;
}
}在这里我选择用native上运行的nanos-lite上进行演示:
实现可自由开关的DiffTest
之前支持异常的DiffTest就没做明白,这个就实在是没办法做,因为没法测。
在NEMU中实现快照
NEMU的状态首先包含NEMU模拟器的内存数据、各个寄存器(GPR,PC,CSR)的数据以及nemu_state,然后就是NEMU的这些设备的状态,将它们当前的状态存放在文件中即可。这个任务看似不难,实则并不简单,这是因为设备的状态是很复杂的,特别是对于声卡而言,它会有一个SDL不断触发的回调函数,而这一状态是很难在NEMU上记录下来的。因此我只能实现一个大概能用的快照功能,它并不完美:
static int cmd_save(char *args)
{
char *path = strtok(NULL, " ");
if (path == NULL)
{
printf("Invalid parameters! Need file path here.\n");
return 0;
}
FILE *f = fopen(path, "wb");
int _;
// save nemu_state
_ = fwrite(&nemu_state, sizeof(nemu_state), 1, f);
// save cpu
_ = fwrite(&cpu, sizeof(cpu), 1, f);
// save memory
_ = fwrite(guest_to_host(RESET_VECTOR), 1, CONFIG_MSIZE, f);
// save device
void save_device(FILE *);
save_device(f);
fclose(f);
assert(_);
return 0;
}加载部分要注意audio不能从保存快照照抄,因为它存在一个初始化的过程,所以还要多添加一个变量inited指示是否初始化过。而vga也有一个同步到屏幕的过程,同理也要添加。不过这里我不多做赘述,给出audio的实现即可:
void save_audio(FILE *f)
{
int _;
_ = fwrite(audio_base, 4, nr_reg, f);
_ = fwrite(sbuf, 1, CONFIG_SB_SIZE, f);
_ = fwrite(&buf_l, sizeof(buf_l), 1, f);
_ = fwrite(&buf_r, sizeof(buf_r), 1, f);
_ = fwrite(&inited, sizeof(inited), 1, f);
assert(_);
}
void load_audio(FILE *f)
{
int _;
_ = fread(audio_base, 4, nr_reg, f);
_ = fread(sbuf, 1, CONFIG_SB_SIZE, f);
_ = fread(&buf_l, sizeof(buf_l), 1, f);
_ = fread(&buf_r, sizeof(buf_r), 1, f);
_ = fread(&inited, sizeof(inited), 1, f);
if (inited)
init_sound();
assert(_);
}而对于其他的设备,只需要保存其在内存中的一些寄存器映射及其状态即可。
可以运行其它程序的开机菜单
SYS_execve系统调用就是启动另一个程序的执行,因此我们需要用naive_uload把新程序加载到内存中去,并让PC指向这个新程序的入口。显然,通过naive_uload进入新程序之后,新程序的退出会依靠SYS_exit,而这在当前的实现中会导致NEMU直接停机,因而这个系统调用并不会返回到当前程序。
实现很简单,就不用多做赘述了:
static int sys_execve(Context *c, uintptr_t *a)
{
const char *pathname = (const char *)a[1];
char **argv __attribute__((unused)) = (char **)a[2];
char **envp __attribute__((unused)) = (char **)a[3];
#ifdef CONFIG_STRACE
printf("%s\n", pathname);
#endif
void naive_uload(PCB * pcb, const char *filename);
naive_uload(NULL, pathname);
return 0;
}展示你的批处理系统
稍微修改一下SYS_exit的实现即可:
__attribute__((unused)) char path[] = "/bin/menu";
switch (a[0])
{
case SYS_yield:
yield();
c->GPRx = 0;
break;
case SYS_exit:
#ifdef CONFIG_STRACE
printf("%d\n", a[1]);
#endif
a[1] = (uintptr_t)path;
c->GPRx = sys_execve(c, a);
// halt(a[1]);
break;
...展示你的批处理系统(2)
因为之前我做了echo命令的实现,所以这个问题就变得很简单了——其实就是识别不出来命令是什么内建命令的时候,就把它当作是执行程序即可。
static void sh_handle_cmd(const char *cmd)
{
char *command = (char *)cmd;
char *first = strtok(command, " \n");
size_t arrlen = sizeof(cmd_table) / sizeof(cmd_table[0]);
char *args = first + strlen(first) + 1;
int i;
for (i = 0; i < arrlen; i++)
{
if (strcmp(first, cmd_table[i].name) == 0)
{
cmd_table[i].handler(args);
break;
}
}
if (i == arrlen)
{
execve(first, NULL, NULL);
}
}为NTerm中的內建Shell添加环境变量的支持
还是很简单,稍微修改一下上述的代码中执行程序的地方就可以了:
static void sh_handle_cmd(const char *cmd)
{
char *command = (char *)cmd;
char *first = strtok(command, " \n");
size_t arrlen = sizeof(cmd_table) / sizeof(cmd_table[0]);
char *args = first + strlen(first) + 1;
int i;
for (i = 0; i < arrlen; i++)
{
if (strcmp(first, cmd_table[i].name) == 0)
{
cmd_table[i].handler(args);
break;
}
}
if (i == arrlen)
{
setenv("PATH", "/bin", 0);
execvp(first, NULL);
}
}终极拷问
新的认识:终端从键盘获取到输入后,发现以./开头,于是在当前目录下找到hello程序,并fork出来一个新进程,在新进程上用execve执行这个新程序。
添加开机音乐
这个任务很简单啊,从nplayer那边随便抄点代码过来就可以了。我用的是Windows Vista的开机音乐,演示如下:
必答题 - 理解计算机系统
前三个已经回答过了这里就不多做赘述,重点讲一下第四个:
调用库函数fread,这实际上会在libos中导致调用一个系统调用SYS_read,这个系统调用被编译成一个ecall指令,当NEMU执行这个指令的时候就会跳转到异常处理入口,开始处理这个异常,接着被识别为Nanos-lite的系统调用而被处理,进而把文件中的数据复制到要读取到的buffer中,接着退出事件处理,恢复上下文回到程序。
将像素信息更新到屏幕上其实就是系统调用的过程相对于上面的过程其实也就多了一步操作设备的过程。