PA4的主要任务就是让我们实现虚存管理和上下文切换,进而实现一个多道程序系统。要完成必做任务,它的代码量并不多,但是需要我们对计算机系统的理解更加透彻,这会导致我的调试起来比较的困难,不过不用担心,这也只不过是一个简单的小实验罢了。
阶段1
多道程序
其实我在骗你!
现在我们的所编译出来的Navy上的程序都是编译到一个固定位置的,很难把不同的进程加载到不同的内存位置。
为什么需要使用不同的栈空间?
这会导致进程间不存在隔离可言:一方面一个进程可以监视另一个进程的栈,另一方面,一个程序对栈的误操作可能导致其他程序也跟着崩溃。
进程控制块
这里的进程控制块的结构非常有意思:
typedef union
{
uint8_t stack[STACK_SIZE];
struct
{
Context *cp;
};
} PCB;在riscv32下,这个联合的大小是STACK_SIZE字节的,它之所以被成为PCB,一方面它为进程开辟了STACK_SIZE字节的栈,另一方面,它将进程的上下文结构的指针存放在了栈的底部。因此,除掉这个上下文结构的指针,进程的可用栈大小为 。为什么非要用联合,而不是单独把这个上下文结构的指针拿出来呢?我认为这确保了上下文的指针也在对应进程的地址空间中,进而能让进程自己可以访问它。
为什么不叫”内核进程”?
等我学了OS课之后再解释吧~至少做了PA4会知道,内核线程不需要加载额外的程序,所使用的栈也是内核之前分配好了的。
实现上下文切换
首先我们实现kcontext函数,这个函数用于创建内核线程的上下文,这个创建出来的上下文实质上可以让这个进程恢复到一个初始执行的状态,所以我们事实上只需要在上下文里设置mepc为entry,这样根据trap.S里恢复上下文的逻辑,就可以在恢复上下文之后让PC指向entry,进而开始内核线程的运行。
这里kcontext要求不允许在entry处ret,原因是kcontext构造的上下文的ra是无法正常规定的,因而返回回去的地址是无法确定的,往往会导致程序的崩溃。
Context *kcontext(Area kstack, void (*entry)(void *), void *arg)
{
Context *ctx = kstack.end - sizeof(Context);
memset(ctx, 0, sizeof(Context));
ctx->mepc = (uintptr_t)entry;
ctx->mstatus = 0x1800;
return ctx;
}阅读了yield-os.c,能知道这个操作系统的事件处理函数会返回与当前不同的进程的上下文的指针,而这个指针会被传到__am_irq_handle的返回值里,因此要在trap.S调用了__am_irq_handle之后把sp指针设成__am_irq_handle的返回值,这样才可以恢复另一个进程的上下文:
.align 3
.globl __am_asm_trap
__am_asm_trap:
addi sp, sp, -CONTEXT_SIZE
MAP(REGS, PUSH)
csrr t0, mcause
csrr t1, mstatus
csrr t2, mepc
STORE t0, OFFSET_CAUSE(sp)
STORE t1, OFFSET_STATUS(sp)
STORE t2, OFFSET_EPC(sp)
# set mstatus.MPRV to pass difftest
li a0, (1 << 17)
or t1, t1, a0
csrw mstatus, t1
mv a0, sp
call __am_irq_handle
mv sp, a0
LOAD t1, OFFSET_STATUS(sp)
LOAD t2, OFFSET_EPC(sp)
csrw mstatus, t1
csrw mepc, t2
MAP(REGS, POP)
addi sp, sp, CONTEXT_SIZE
mret为什么是a0寄存器呢?我们可以看RISCV的ABI手册,里面写明了a0寄存器是充当返回值的。
mips32和riscv32的调用约定
返回值都从手册里看到了,看看函数调用的参数应该不难吧~其实就是从a0排到a7,再多就排到栈上去。
实现上下文切换(2)
由于这个参数就是线程所启动的函数的参数,而我们恢复上下文之后PC会直接指向这个函数的入口,所以我们需要在构造的上下文中把参数放在函数参数应该放的地方,这样就能在运行函数时就可以成功读到正确的参数了。
既然参数就只有一个,那么设置上下文a0寄存器就可以了(话说a0寄存器真是劳模啊)
Context *kcontext(Area kstack, void (*entry)(void *), void *arg)
{
Context *ctx = kstack.end - sizeof(Context);
memset(ctx, 0, sizeof(Context));
ctx->mepc = (uintptr_t)entry;
ctx->mstatus = 0x1800;
ctx->gpr[10] = (uintptr_t)arg;
return ctx;
}保持kcontext()的特性
x86的内容,以后再说吧。不过原理倒是看懂了,就是为了防止kcontext直接往栈里填参数,于是就引入辅助函数,把参数先放到寄存器里,然后这个辅助函数再把放在寄存器里的参数放到栈上,然后再执行真正的线程入口函数。
构建RT-Thread
因为我不是南京大学的学生,因而本来就不用上交作业,所以我就把RT-Thread的仓库直接克隆到ics2024下面了。
要成功构建RT-Thread并非教程中那么简单。如果你做了PA3的Navy上的FCEUX选作任务,那么你需要把Makefile里的CFLAGS中的宏定义恢复原样,否则。此外,有关可变参数的一些宏定义可能存在重复定义的问题,需要在rt-thread-am/include/rtdef.h中用#ifndef括起来,比如像这样:
/* the version of GNU GCC must be greater than 4.x */
typedef __builtin_va_list __gnuc_va_list;
typedef __gnuc_va_list va_list;
#ifndef va_start
#define va_start(v, l) __builtin_va_start(v, l)
#endif
#ifndef va_end
#define va_end(v) __builtin_va_end(v)
#endif
#ifndef va_arg
#define va_arg(v, l) __builtin_va_arg(v, l)
#endif危险的全局变量(2)
会导致数据被另一个线程篡改的问题,很常见的并发问题。
危险的全局变量(3)
第一次的全局变量信息被第二次覆盖了,也是很常见的并发问题。
通过CTE实现RT-Thread的上下文创建和切换
首先来实现rt_hw_stack_init函数。根据教程所说,为了防止一些并发问题,要用一个包裹函数把真正的入口包起来,然后把包裹函数的参数放到栈上,在最后用kcontext构造好启动包裹函数的上下文即可。因此这里需要我们自己规定一下栈里的结构,我规定的模式如下(实际实现中因为要对齐可能会有些缝隙,不过大概是这个样子的):
| |
+---------------+ <---- kstack.end
| arg |
+---------------+ <---- 1
| |
| context |
| |
+---------------+
| |
| |
| |
| |
| |
+---------------+ <---- kstack.start
| |
所以在rt_hw_stack_init中,我们首先把tentry,parameter,texit作为图中的arg压入栈内,然后再在下面构造上下文,此时构造的上下文的参数kstack.end就应该是图中标1的位置,入口则是包装函数,参数则是图中标1的位置的地址。之后若启动这个线程,就会首先跳到包装函数里面,然后包装函数利用传给它的指针获取到这三个参数,进而执行真正的入口函数。具体实现如下:
struct dummy_entry_parameter
{
void (*tentry)(void *);
void *parameter;
void (*texit)();
};
void dummy_entry_fun(void *arg)
{
struct dummy_entry_parameter *dep = arg;
dep->tentry(dep->parameter);
dep->texit();
}
rt_uint8_t *rt_hw_stack_init(void *tentry, void *parameter,
rt_uint8_t *stack_addr, void *texit)
{
stack_addr = (rt_uint8_t *)ROUNDDOWN(stack_addr, sizeof(uintptr_t));
struct dummy_entry_parameter *dep =
(struct dummy_entry_parameter *)(stack_addr -
sizeof(struct dummy_entry_parameter));
dep->tentry = tentry;
dep->parameter = parameter;
dep->texit = texit;
stack_addr = (rt_uint8_t *)ROUNDDOWN(dep, sizeof(uintptr_t));
Context *ctx = kcontext((Area){0, stack_addr}, dummy_entry_fun, dep);
return (rt_uint8_t *)ctx;
}然后就是实现一下上下文切换的函数,这个比较简单,因为目前用全局变量来传递信息也是可以的,不过要注意的是传递给rt_hw_context_switch_to的参数是二级指针。下面是我的实现:
Context **switch_from = NULL;
Context **switch_to = NULL;
static Context *ev_handler(Event e, Context *c)
{
switch (e.event)
{
case EVENT_YIELD:
if (switch_from != NULL)
*switch_from = c;
if (switch_to != NULL)
c = *switch_to;
switch_from = NULL;
switch_to = NULL;
break;
case EVENT_IRQ_TIMER:
break;
default:
printf("Unhandled event ID = %d\n", e.event);
assert(0);
}
return c;
}
...
void rt_hw_context_switch_to(rt_ubase_t to)
{
switch_from = NULL;
switch_to = (Context **)to;
yield();
}
void rt_hw_context_switch(rt_ubase_t from, rt_ubase_t to)
{
switch_from = (Context **)from;
switch_to = (Context **)to;
yield();
}在实现过程中要合理的使用AM的CTE所提供的API,不能想当然只针对一种架构编写代码。
在native上进行上下文切换
上面我已经解决好了。
危险的全局变量(4)
这里教程中所提到的方法就是把同一个线程用到的东西放到其PCB里,进而不需要用比较危险的全局变量。因为这里的同一个线程需要用到from和to两个指针,我们先把他俩包装成一个结构体压到栈里面,然后把对应线程PCB的user_data设置为指向这个结构体的指针,这样在ev_handler里面就可以通过访问PCB的user_data来得到from和to两个指针了。不过这会篡改掉user_data,所以在yield之后需要恢复一下。具体实现如下:
struct context_switcher
{
Context **from;
Context **to;
};
static Context *ev_handler(Event e, Context *c)
{
switch (e.event)
{
case EVENT_YIELD:
rt_thread_t current = rt_thread_self();
struct context_switcher *switcher =
(struct context_switcher *)(current->user_data);
if (switcher->from != NULL)
*(switcher->from) = c;
if (switcher->to != NULL)
c = *(switcher->to);
break;
case EVENT_IRQ_TIMER:
break;
default:
printf("Unhandled event ID = %d\n", e.event);
assert(0);
}
return c;
}
...
void rt_hw_context_switch_to(rt_ubase_t to)
{
// switch_from = NULL;
// switch_to = (Context **)to;
rt_thread_t current = rt_thread_self();
rt_ubase_t old_user_data = current->user_data;
struct context_switcher switcher =
(struct context_switcher){NULL, (Context **)to};
current->user_data = (rt_ubase_t)&switcher;
yield();
current->user_data = old_user_data;
}
void rt_hw_context_switch(rt_ubase_t from, rt_ubase_t to)
{
// switch_from = (Context **)from;
// switch_to = (Context **)to;
rt_thread_t current = rt_thread_self();
rt_ubase_t old_user_data = current->user_data;
struct context_switcher switcher =
(struct context_switcher){(Context **)from, (Context **)to};
current->user_data = (rt_ubase_t)&switcher;
yield();
current->user_data = old_user_data;
}在RT-Thread上运行AM程序
这个任务并不难,要运行AM上的程序,我们得在内置的Shell命令中添加启动这些程序的命令就行了:
static int _uart_getc(struct rt_serial_device *serial)
{
static const char *p = "help\ndate\nversion\nfree\nps\npwd\nls\nmemtrace\nm"
"emcheck\nutest_list\nam_hello\nam_microbench\nam_"
"typing_game\nam_snake\nam_fceux_am\n";
return (*p != '\0' ? *(p++) : -1);
}要注意的是,如果想要在native上运行程序,则还需要在事件处理函数ev_handler里注册EVENT_IRQ_IODEV,让它能识别出来就好,其他什么都不用做的。
这是如何实现的?
这些AM的程序都有各自的main,如果不加处理直接链接,会有重复定义的问题。所以这个python程序会给这些AM程序编译出来的.o文件的符号进行重命名,也就是给这些符号加上前缀__am_{app_name}_。例如typing-game的main会被重命名为__am_typing_game_main。
而am和klib库里的函数的处理会更加复杂一些,因为这相当于要用RT-Thread虚拟出一个AM的环境,所以引入了一些伪AM库函数,比如__dummy_ioe_init和__rt_am_halt这样的函数。这些函数会使得符号比较的复杂,因此python程序里就构造了一个符号重命名表redefine_sym.txt来进行更加细致的替换。具体细节可以去看看这个python程序的integrate函数的实现,特别是构造redefine_sym.txt和使用objcopy的那一块。
在Nanos-lite中实现上下文切换
首先实现context_kload函数,这只是在kcontext的基础上,把返回的上下文的指针记录到PCB中即可。
然后是schedule函数,首先我们确定我们的调度原则是让两个线程轮流调度,因此原则上我们只需要判断当前线程是哪一个,然后返回另一个线程的上下文地址就可以了,这样之后就会恢复另一个线程的上下文进而运行另一个线程。不过为了能再次运行当前线程,还需要把当前线程的上下文的地址记录到当前线程的PCB中。
最后是修改事件处理函数,这个太简单就不多做赘述了。
void context_kload(PCB *pcb, void (*entry)(void *), void *arg)
{
pcb->cp = kcontext((Area){pcb, pcb + 1}, entry, arg);
}
void init_proc()
{
context_kload(&pcb[0], hello_fun, (void *)1);
context_kload(&pcb[1], hello_fun, (void *)0);
switch_boot_pcb();
Log("Initializing processes...");
// // load program here
// void naive_uload(PCB * pcb, const char *filename);
// naive_uload(NULL, "/bin/nterm");
}
Context *schedule(Context *prev)
{
current->cp = prev;
PCB *switch_to = (current == &pcb[0] ? &pcb[1] : &pcb[0]);
current = switch_to;
return current->cp;
}static Context *do_event(Event e, Context *c)
{
switch (e.event)
{
case EVENT_YIELD:
// printf("yield\n");
c = schedule(c);
break;
case EVENT_SYSCALL:
do_syscall(c);
break;
case EVENT_IRQ_TIMER:
break;
default:
panic("Unhandled event ID = %d", e.event);
}
return c;
}在native上进行上下文切换
上面的代码已经弄好了的。
实现多道程序系统
首先是实现构造运行用户程序的环境,而这就需要先把用户程序加载进来,然后利用ucontext构造上下文。其目前的实现与kcontext大同小异。不过教程中提到是用GPRx作为媒介来设置用户程序的用户栈,所以要额外设置一下:
Context *ucontext(AddrSpace *as, Area kstack, void *entry)
{
Context *ctx = kstack.end - sizeof(Context);
memset(ctx, 0, sizeof(Context));
ctx->mepc = (uintptr_t)entry;
ctx->mstatus = 0x1800;
return ctx;
}void context_uload(PCB *pcb, const char *path)
{
uintptr_t entry = loader(pcb, path);
pcb->cp = ucontext(&pcb->as, (Area){pcb, pcb + 1}, (void *)entry);
pcb->cp->GPRx = (uintptr_t)heap.end;
}然后是在Navy的start.S中把GPRx传递给栈指针寄存器,在RISCV中我们规定的GPRx为a0寄存器:
#elif defined(__riscv)
mv s0, zero
mv sp, a0
jal call_main为了让AM native也可以运行,也需要把GPRx传递给栈指针寄存器,阅读AM native的代码后可以知道AM native的GPRx是rax寄存器,而x86-64的栈指针寄存器是rsp,所以这样加一行就可以:
#if defined(__ISA_AM_NATIVE__)
movq $0, %rbp
movq %rax, %rsp
// (rsp + 8) should be multiple of 16 when
// control is transfered to the function entry point.
// See amd64 ABI manual for more details
andq $0xfffffffffffffff0, %rsp
movq %rax, %rdi
call call_main此外,虽然教程中说现在ucontext函数的as参数没用,但是为了对上AM native的接口,还是要传一个as才行。(上面已经做好了)
要验证仙剑奇侠传确实在使用用户栈而不是内核栈,可以在call_main函数里面打印一下empty变量的地址。因为在riscv32-nemu中,我们规定的heap.end为0x88000000,所以如果我们实现正确,empty变量的地址应该就是一个比0x88000000稍微小一点点的数字。事实证明也是如此,我得到的地址是0x87ffffec。
一山不能藏二虎?
会导致模拟器直接崩掉。因为这两个用户程序链接到的是同一个地方,第二次加载会覆盖掉上一次的,所以执行第一个加载的程序会直接崩掉。
给用户进程传递参数
其实这就是一个小小的C语言练习。不过需要注意的是,RISC-V是要求必须对齐访存的,而ABI中规定了一些Unspecified的块正好就可以用来对齐内存。
然后之前教程中我们用a0(也就是GPRx)作为媒介来传递用户栈还是很有意思的,因为a0这会儿正好又作为了call_main的参数,恰恰它又指向了argc,没错就是这么巧合,我们不需要特地地设置call_main的函数参数了。
下面是我的实现:
void context_uload(PCB *pcb, const char *filename, char *const argv[],
char *const envp[])
{
int argc = 0, envc = 0;
size_t strlen_tot = 0;
while (argv[argc] != NULL)
{
strlen_tot += strlen(argv[argc]) + 1;
argc++;
}
while (envp[envc] != NULL)
{
strlen_tot += strlen(envp[envc]) + 1;
envc++;
}
char **env_ptr =
(char **)ROUNDDOWN(heap.end - strlen_tot - sizeof(*env_ptr),
sizeof(*env_ptr));
*(env_ptr--) = NULL;
char *str_ptr = heap.end - strlen_tot;
for (int i = envc - 1; i >= 0; i--)
{
char *env = envp[i];
*(env_ptr--) = str_ptr;
strcpy(str_ptr, env);
str_ptr += strlen(env) + 1;
}
char **arg_ptr = env_ptr;
*(arg_ptr--) = NULL;
for (int i = argc - 1; i >= 0; i--)
{
char *arg = argv[i];
*(arg_ptr--) = str_ptr;
strcpy(str_ptr, arg);
str_ptr += strlen(arg) + 1;
}
int *argc_ptr = (int *)((uintptr_t)arg_ptr + sizeof(char *) - sizeof(int));
*argc_ptr = argc;
uintptr_t entry = loader(pcb, filename);
pcb->cp = ucontext(pcb->as, (Area){pcb, pcb + 1}, (void *)entry);
pcb->cp->GPRx = (uintptr_t)argc_ptr;
}然后在crt0.c也要做相应的改动来获取参数:
void call_main(uintptr_t *args)
{
int argc = *(int *)args;
// printf("argc = %d\n", argc);
char **argv = (char **)((uintptr_t)args + sizeof(int));
// printf("argv0 = %s, argv1 = %s\n", argv[0], argv[1]);
char **envp = argv + argc + 1;
environ = envp;
__libc_init_array();
exit(main(argc, argv, envp));
assert(0);
}最后就是修改一下仙剑奇侠传的代码,这也很简单,读取一下参数,判断是否含有--skip就可以了。
char *arg_skip = "--skip";
bool skip = false;
for (int i = 0; i < argc; i++)
{
if (strcmp(argv[i], arg_skip) == 0)
skip = true;
}
if (!skip)
PAL_TrademarkScreen();关于如何传递实参,这样子就可以:
context_uload(&pcb[1], "/bin/pal", (char *const[]){"--skip", NULL},(char *const[]){NULL});为什么少了一个const?
传递给execve的内容可能在程序的一个只读区域,那么去更改它就会导致发生错误。此外,从可传入的参数的多样性来看,const的能允许const和非const的都能作为实参,而非const的只允许非const的传入。
对于main而言,它的参数都在栈上,显然是可读可写的,所以就没添加const。
实现带参数的execve()
首先实现一下用户栈的申请,new_page的实现还是挺简单的,然后是在context_uload中调用new_page以得到用户栈,太简单了,就不多废话了。
static void *pf = NULL;
void *new_page(size_t nr_page)
{
void *ret = pf;
pf += nr_page * PGSIZE;
return ret;
}接着是完善SYS_execve的实现,首先应该改为用context_uload给当前进程加载新的程序(对于教程中提及的调用context_uload用的pcb参数的问题,显然我们应该用current,因为SYS_execve的语义就是让当前进程执行程序),并构造好用户栈和内核栈。这并不会像naive_uload一样直接就可以执行了,而是应该利用yield触发Nanos-lite的调度机制,再次调度到这个进程进而执行新程序。而你这时候一定不希望这个yield会保存当前进程的上下文(因为这个进程的执行的新程序的初始上下文已经构造好了,不用再动),所以需要在yield之前利用switch_boot_pcb修改current指针成一个“无害”的用来占位的PCB即可。
需要注意的是,目前的SYS_execve对context_uload的实现有要求:必须是先分配好用户栈并写入参数,然后在加载新的程序。如果你先加载新的程序,那么就会覆盖掉原先的程序,这就会导致一些在原先的程序里的参数(比如字符串字面量)就会变成垃圾值,使得写入的参数有误。
事实上,在完成了新程序加载到内存和构造上下文的任务后,这个进程原先的程序已经被篡改得面目全非了,也不可能再被调度回来了,所以我这里的return 0纯粹是用来防止LSP报错的,本身是没意义的。
此外,因为我们在这里修改了SYS_execve的接口与内部实现,所以按照之前的调用规范调用SYS_execve的地方都应该检查一下是否有问题。
static int sys_execve(Context *c, uintptr_t *a)
{
const char *filename = (const char *)a[1];
char *const *argv = (char *const *)a[2];
char *const *envp = (char *const *)a[3];
#ifdef CONFIG_STRACE
printf("%s\n", pathname);
#endif
void switch_boot_pcb();
void context_uload(PCB * pcb, const char *filename, char *const argv[],
char *const envp[]);
context_uload(current, filename, argv, envp);
switch_boot_pcb();
yield();
return 0;
}实现以上代码就可以跑exec-test了,注意要给它传递参数!这个程序在riscv32-nemu上成功跑了359次才崩溃,说明上面的实现应该是正确的。然后MENU也是可以直接跑的。NTerm这里稍微改一下也可以跑:
static void sh_handle_cmd(const char *cmd)
{
char *command = (char *)cmd;
char *first = strtok(command, " \n");
size_t arrlen = sizeof(cmd_table) / sizeof(cmd_table[0]);
char *args = first + strlen(first) + 1;
int i;
for (i = 0; i < arrlen; i++)
{
if (strcmp(first, cmd_table[i].name) == 0)
{
cmd_table[i].handler(args);
break;
}
}
if (i == arrlen)
{
SDL_Quit();
char *cmd_args[20];
cmd_args[0] = first;
for (int i = 1; i < 20; i++)
{
cmd_args[i] = strtok(NULL, " \n");
}
setenv("PATH", "/bin", 0);
execvp(first, cmd_args);
}
}不过我发现了框架的一个小缺陷:声卡没有关闭功能。这就导致用NTerm里面播放的开机音乐的声音配置初始化声卡(SDL_Init(SDL_INIT_AUDIO))之后,无法进行SDL_QuitSubSystem,进而启动PAL再次初始化声卡,声音配置可能不一样,导致听出来的效果很奇怪。不过这不是主要问题,就先搁置一边了。
运行Busybox
显然是可以运行的。不过要注意的是NTerm中构造的argv[0]一定得是要执行的程序的路径字符串,否则Busybox无法正常路由。
运行Busybox(2)
阅读了navy-apps/libs/libc/src/posix/execvp.c就会发现,其实遍历PATH这一块execvp是已经实现好了的,其策略就是按照;把PATH进行分割,然后逐个去用execv试着执行,如果发现执行失败且错误码是2(找不到文件),那么就继续看下一个。所以我们实际上需要做的是完善execve的返回值和错误码。
int execvp(const char *file, char *const argv[])
{
char *path = getenv("PATH");
char buf[MAXNAMLEN];
/* If $PATH doesn't exist, just pass FILE on unchanged. */
if (!path)
return execv(file, argv);
/* If FILE contains a directory, don't search $PATH. */
if (strchr(file, '/'))
return execv(file, argv);
while (*path)
{
strccpy(buf, path, PATH_DELIM);
/* An empty entry means the current directory. */
if (*buf != 0 && buf[strlen(buf) - 1] != '/')
strcat(buf, "/");
strcat(buf, file);
if (execv(buf, argv) == -1 && errno != ENOENT)
return -1;
while (*path && *path != PATH_DELIM)
path++;
if (*path == PATH_DELIM)
path++; /* skip over delim */
}
return -1;
}首先应该修改Nanos-lite中fs_open的实现,使其找不到文件时不要直接panic,而是返回一个-1,然后在SYS_execve处调用fs_open判断是否能找到文件,如果找不到就返回-2。
static int sys_execve(Context *c, uintptr_t *a)
{
const char *filename = (const char *)a[1];
char *const *argv = (char *const *)a[2];
char *const *envp = (char *const *)a[3];
#ifdef CONFIG_STRACE
printf("%s\n", pathname);
#endif
int fd = fs_open(filename, 0, 0);
if (fd == -1)
return -2;
fs_close(fd);
void switch_boot_pcb();
void context_uload(PCB * pcb, const char *filename, char *const argv[],
char *const envp[]);
context_uload(current, filename, argv, envp);
switch_boot_pcb();
yield();
return 0;
}接着就要在Navy的libos中处理系统调用的返回值了,按照教程所说的办就行,确保能和execvp的实现对接得上。
int _execve(const char *fname, char *const argv[], char *const envp[])
{
intptr_t ret = _syscall_(SYS_execve, (uintptr_t)fname, (uintptr_t)argv,
(uintptr_t)envp);
if (ret < 0)
{
errno = -ret;
return -1;
}
return 0;
}阶段2
虚实交错的魔法
实现基于PIE的loader (建议二周目思考)
有点感兴趣,但是目前不打算做这个。因为缺乏测试用例,而且我自己对程序的链接、加载也不是很熟悉。
超越容量的界限
虚存管理中PIC的好处
如果有多个程序会用到一个动态库,那么可以把动态库加载到任意一个空闲位置,然后利用虚存管理将多个程序的一部分关于库的虚拟页都映射到之前动态库所加载到的物理页,这样就避免多次重复加载动态库了。
理解分页细节
- 因为基地址是关于页对齐的,而页的大小为字节,就会导致基地址的低12位一定都是0,所以基地址信息只需要高20位就可以表示基地址了。
- 采用物理地址是必须的。因为如果这些表项(CR3)为虚拟地址,那么要找到其物理地址则又需要访问它们本身,这会导致死循环。
- 如果采用一级页表,那么这个页表将会有个表项,也就是说这个每个一级页表都会占用高达4MB的空间,而实际上因为基本上也没几个程序会占那么多的空间,所以页表的利用率很低,很浪费内存。此外这个页表得跨多个页,会让操作系统的内存分配机制变得更加复杂。
理解分页机制
因为我这里做的是riscv32,所以就简单贴出riscv32的页表相关的内容。实际上这些内容和i386的极其类似。
RV32的分页方案叫作Sv32,支持4GiB的虚拟地址空间,每一个基页为4KiB。
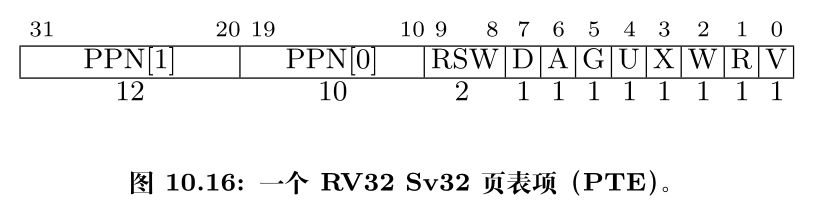

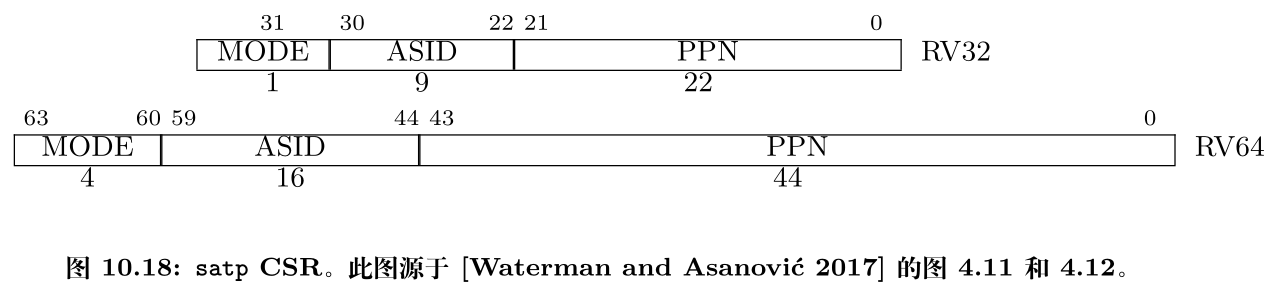
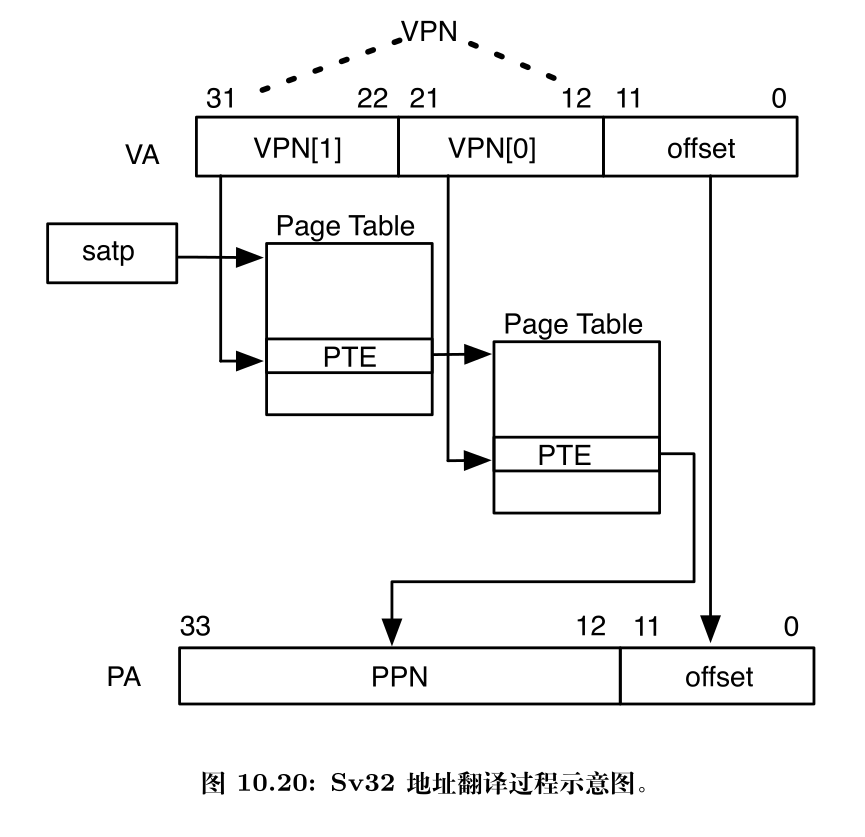
空指针真的是”空”的吗?
解引用的时候就是访0地址的存,这个0地址会被当作虚拟地址,于是会发现它在页表中没有映射,所以才导致的程序崩溃。
mips32的TLB管理是否更简单?
那我不好说啊,因为我不是做mips32的。
在分页机制上运行Nanos-lite
在Nanos-lite中实现pg_alloc
#ifdef HAS_VME
static void *pg_alloc(int n)
{
assert(n % PGSIZE == 0);
void *ret = new_page(n / PGSIZE);
memset(ret, 0, n);
return ret;
}
#endif这个时候可以在AM-native上试着运行一下Nanos-lite,检测你的pg_alloc是否正确。这很重要,因为在AM的VME中就是靠这个函数申请的物理页。
实现VME的map
VME的map是用来设置一个虚拟页到物理页的映射的,因此对于页表来说十分重要。在这里我规定了map函数接收的虚拟地址和物理地址都必须是标准的按页对齐的地址,也只关心了页表项里的V位,其他的权限位都没管,这样方便实现。我的实现如下:
void map(AddrSpace *as, void *va, void *pa, int prot)
{
assert(as->ptr);
assert((uintptr_t)va % PGSIZE == 0);
assert((uintptr_t)pa % PGSIZE == 0);
uintptr_t pt1 = (uintptr_t)as->ptr;
uintptr_t *pte1 = (uintptr_t *)(pt1 + ((uintptr_t)va >> 22) * 4);
uintptr_t pt2 = *pte1 >> 10 << 12;
if ((*pte1 & 1) == 0)
{
pt2 = (uintptr_t)pgalloc_usr(PGSIZE);
*pte1 = 0;
*pte1 |= 1;
*pte1 |= pt2 >> 12 << 10;
}
uintptr_t *pte2 = (uintptr_t *)(pt2 + ((uintptr_t)va << 10 >> 22) * 4);
assert((*pte2 & 1) == 0);
*pte2 = 0;
*pte2 |= 1;
*pte2 |= (uintptr_t)pa >> 12 << 10;
}在NEMU中实现分页机制
刚才在AM的VME把页表的设置工作都做好了,实际上在NEMU的isa_mmu_translate中做的是更加简单的页表的读取工作。可以看到它和上面的map函数长得其实差不太多。
paddr_t isa_mmu_translate(vaddr_t vaddr, int len, int type)
{
assert(cpu.satp >> 31);
paddr_t pt1 = (cpu.satp & 0x3FFFFF) << 12;
word_t pte1 = paddr_read(pt1 + (vaddr >> 22) * 4, 4);
assert(pte1 & 1);
paddr_t pt2 = pte1 >> 10 << 12;
word_t pte2 = paddr_read(pt2 + (vaddr << 10 >> 22) * 4, 4);
assert(pte2 & 1);
paddr_t pa = (pte2 >> 10 << 12) | (vaddr & 0xFFF);
return pa;
}此外还需要实现一个检测函数用以检测satp寄存器是否开启了分页模式。
#define isa_mmu_check(vaddr, len, type) \
({ \
int ret = MMU_FAIL; \
if (cpu.satp >> 31) \
ret = MMU_TRANSLATE; \
else \
ret = MMU_DIRECT; \
ret; \
})现在既然已经可以检测分页模式,也能够转换地址了,所以就要在vaddr.c中稍微修改一下实现,使其支持虚拟地址。可以说,现在的vaddr.c才是名副其实的vaddr.c。
word_t vaddr_ifetch(vaddr_t addr, int len)
{
switch (isa_mmu_check(addr, len, MEM_TYPE_IFTECH))
{
case MMU_DIRECT:
return paddr_read(addr, len);
case MMU_TRANSLATE:
return paddr_read(isa_mmu_translate(addr, len, MEM_TYPE_IFETCH), len);
default:
assert(0);
}
}做完了以上工作,暂时还不可以运行仙剑奇侠传,因为在AM的VME中的vme_init函数中并没有给内核地址空间中的声卡的缓冲区做映射。因而这需要我们人为修改一下NEMU_PADDR_SPACE这个宏。
#define NEMU_PADDR_SPACE \
RANGE(&_pmem_start, PMEM_END), \
RANGE(FB_ADDR, FB_ADDR + 0x200000), \
RANGE(AUDIO_SBUF_ADDR, AUDIO_SBUF_ADDR + 0x10000), \
RANGE(MMIO_BASE, MMIO_BASE + 0x1000) /* serial, rtc, screen, keyboard */让DiffTest支持分页机制
做不了😮💨,PA3里的DiffTest就跑不起来。
在分页机制上运行用户进程
之前的程序都是让它运行在内核地址空间的,现在我们要让每个进程运行在它自己的虚拟地址空间中。首先我们要在Navy-apps里面执行命令make clean-all清除之前的构建出来的东西,然后在Nanos-lite中执行命令make ARCH=riscv32-nemu VME=1 update,这样生成的可执行文件就是被链接到0x40000000附近的了。
然后我们会在构建用户进程上下文的时候创建用户进程的地址空间(我的实现是在context_uload的一开始就调用了protect来创建用户进程的地址空间,而非是教程中所说的ucontext中才调用),其初始实际上就是一份内核的地址空间的拷贝。接着考虑用户进程的加载过程:这需要我们申请若干的物理页,然后把需要加载的程序段放进去,并添加对应的映射,对于进程的栈也是同样的道理。
需要注意的是,教程中要求调用map()的时候需要将prot设置成可读可写可执行,实际上也就是把prot设置为MMAP_READ | MMAP_WRITE即可,这在$AM_HOME/am/src/native/platform.c中的__am_pmem_map得到了体现。
修改loader的实现
loader的实现是最复杂的,因为程序段会长的比较千奇百怪,比如它们的段在虚拟内存的起始地址很可能不是按页对齐的,也有可能某个段的起始正好和在上一个段的结尾在同一个页面上。比如下面这个程序就是这样的:
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
RISCV_ATTRIBUT 0x080b37 0x00000000 0x00000000 0x0004e 0x00000 R 0x1
LOAD 0x000000 0x40000000 0x40000000 0x7d378 0x7d378 R E 0x1000
LOAD 0x07dffc 0x4007effc 0x4007effc 0x02b10 0xf3d78 RW 0x1000
GNU_STACK 0x000000 0x00000000 0x00000000 0x00000 0x00000 RW 0x10
GNU_RELRO 0x07dffc 0x4007effc 0x4007effc 0x00004 0x00004 R 0x1
所以我们写的加载器一定要可以加载这些奇怪的程序段,这就需要写代码时更加地细心。
static uintptr_t loader(PCB *pcb, const char *filename)
{
#if defined(__ISA_AM_NATIVE__)
#define EXPECT_TYPE EM_X86_64
#elif defined(__ISA_RISCV32__)
#define EXPECT_TYPE EM_RISCV
#else
#error Unsupported ISA
#endif
int fd = fs_open(filename, 0, 0);
Elf_Ehdr ehdr;
fs_read(fd, &ehdr, sizeof(Elf_Ehdr));
assert(ehdr.e_ident[EI_MAG0] == ELFMAG0);
assert(ehdr.e_ident[EI_MAG1] == ELFMAG1);
assert(ehdr.e_ident[EI_MAG2] == ELFMAG2);
assert(ehdr.e_machine == EXPECT_TYPE);
size_t phdr_num = ehdr.e_phnum;
Elf_Phdr phdr;
uintptr_t max_vp = 0;
uintptr_t last_pp = 0;
for (size_t i = 0; i < phdr_num; i++)
{
fs_lseek(fd, ehdr.e_phoff + i * sizeof(Elf_Phdr), SEEK_SET);
fs_read(fd, &phdr, sizeof(Elf_Phdr));
if (phdr.p_type != PT_LOAD)
continue;
fs_lseek(fd, phdr.p_offset, SEEK_SET);
// load file_sz
for (uintptr_t va = (uintptr_t)phdr.p_vaddr,
vp = ROUNDDOWN(phdr.p_vaddr, PGSIZE);
va < (uintptr_t)phdr.p_vaddr + phdr.p_filesz;
vp += PGSIZE, va = vp)
{
uintptr_t cur_pp = last_pp;
if (vp > max_vp)
{
cur_pp = (uintptr_t)new_page(1);
map(&pcb->as, (void *)vp, (void *)cur_pp,
MMAP_READ | MMAP_WRITE);
last_pp = cur_pp;
max_vp = vp;
}
size_t len = phdr.p_vaddr + phdr.p_filesz - va < PGSIZE + vp - va
? phdr.p_vaddr + phdr.p_filesz - va
: PGSIZE + vp - va;
fs_read(fd, (void *)cur_pp + va - vp, len);
}
// load memsz - file_sz
for (uintptr_t va = (uintptr_t)phdr.p_vaddr + phdr.p_filesz,
vp = ROUNDDOWN(phdr.p_vaddr + phdr.p_filesz, PGSIZE);
va < (uintptr_t)phdr.p_vaddr + phdr.p_memsz; vp += PGSIZE, va = vp)
{
uintptr_t cur_pp = last_pp;
if (vp > max_vp)
{
cur_pp = (uintptr_t)new_page(1);
map(&pcb->as, (void *)vp, (void *)cur_pp,
MMAP_READ | MMAP_WRITE);
last_pp = cur_pp;
max_vp = vp;
}
size_t len = phdr.p_vaddr + phdr.p_memsz - va < PGSIZE + vp - va
? phdr.p_vaddr + phdr.p_memsz - va
: PGSIZE + vp - va;
memset((void *)cur_pp + va - vp, 0, len);
}
}
fs_close(fd);
return (uintptr_t)ehdr.e_entry;
}修改用户栈的实现
对于修改构造用户栈这一块,最主要是要把用户栈做个页表的映射,然后就是记得把之前用户栈里的那些内核地址空间的指针转换为相应用户程序地址空间的指针(虽然暂时不是很必要),对于这个转换函数,我自己编写了一个kas2uas的宏来表示这个转换。
void context_uload(PCB *pcb, const char *filename, char *const argv[],
char *const envp[])
{
// create user-process address space
protect(&pcb->as);
// generate user-process user-stack
int stack_pages = 8;
void *stack_beg = new_page(stack_pages);
void *stack_end = stack_beg + stack_pages * PGSIZE;
#define kas2uas(kaddr) \
((uintptr_t)pcb->as.area.end - ((uintptr_t)stack_end - (uintptr_t)kaddr))
int argc = 0, envc = 0;
size_t strlen_tot = 0;
while (argv[argc] != NULL)
{
strlen_tot += strlen(argv[argc]) + 1;
argc++;
}
while (envp[envc] != NULL)
{
strlen_tot += strlen(envp[envc]) + 1;
envc++;
}
char **env_ptr =
(char **)ROUNDDOWN(stack_end - strlen_tot - sizeof(*env_ptr),
sizeof(*env_ptr));
*(env_ptr--) = NULL;
char *str_ptr = stack_end - strlen_tot;
for (int i = envc - 1; i >= 0; i--)
{
char *env = envp[i];
*(env_ptr--) = (char *)kas2uas(str_ptr);
strcpy(str_ptr, env);
str_ptr += strlen(env) + 1;
}
char **arg_ptr = env_ptr;
*(arg_ptr--) = NULL;
for (int i = argc - 1; i >= 0; i--)
{
char *arg = argv[i];
*(arg_ptr--) = (char *)kas2uas(str_ptr);
strcpy(str_ptr, arg);
str_ptr += strlen(arg) + 1;
}
int *argc_ptr = (int *)((uintptr_t)arg_ptr + sizeof(char *) - sizeof(int));
*argc_ptr = argc;
// map user-process stack
for (void *stack_uas = pcb->as.area.end - stack_pages * PGSIZE,
*stack_kas = stack_beg;
stack_uas < pcb->as.area.end; stack_uas += PGSIZE, stack_kas += PGSIZE)
{
map(&pcb->as, stack_uas, stack_kas, MMAP_READ | MMAP_WRITE);
}
// load user-process program segments
uintptr_t entry = loader(pcb, filename);
// generate user-process context in kernel-stack
pcb->cp = ucontext(&pcb->as, (Area){pcb, pcb + 1}, (void *)entry);
// set the user-stack pointer
pcb->cp->GPRx = (uintptr_t)kas2uas(argc_ptr);
#undef kas2uas
}修改MMU
最后我们需要把地址空间的转化落实到MMU中,具体的就是保存与恢复satp寄存器。所以按照教程中修改ucontext和__am_irq_handle的实现就好了。
最后按照教程所说单独运行dummy进行测试即可。如果实现没有问题,那么目前在riscv32-nemu和AM-native上应该都可以成功运行。
内核映射的作用
肯定会运行错误,毕竟用户进程的上下文就是放在内核栈的,如果用户进程的地址空间中没有了内核映射,那么内核栈都是无法访问的,上下文更是不可能恢复得了的。
而在实际实验发现,因为从内核切换到dummy进程时靠的是__am_irq_handle的__am_switch函数,那么在更改satp为用户地址空间后,因为__am_irq_handle的代码段是在内核地址空间的,会直接导致取指令都取不了。
在分页机制上运行仙剑奇侠传
首先我们需要在加载程序的过程中获取max_brk,它的初始值其实就是ELF符号表里的end,那么我们可以从ELF文件的符号表里把end给读出来。当然这有点麻烦,而根据end的定义,我们也可以通过获取程序的数据段的末尾地址来得到,所以在之前的loader函数里每遍历一个可LOAD的程序段就更新一下pcb->max_brk = phdr.p_vaddr + phdr.p_memsz;这样max_brk就会是最后的一个数据段的末尾了。
紧接着让SYS_brk系统调用调用mm_brk函数。最后实现mm_brk函数,让它根据brk和max_brk的关系动态地申请内存。
int mm_brk(uintptr_t brk)
{
if (brk <= current->max_brk)
return 0;
for (uintptr_t va = current->max_brk,
vp = ROUNDDOWN(current->max_brk, PGSIZE);
va < brk; vp += PGSIZE, va = vp)
{
if (va % PGSIZE == 0)
{
uintptr_t pp = (uintptr_t)new_page(1);
map(¤t->as, (void *)vp, (void *)pp, MMAP_READ | MMAP_WRITE);
}
}
current->max_brk = brk;
return 0;
}让DiffTest支持分页机制(2)
DiffTest弄不明白,现在不做。
支持声音
早就遇到错误了~在上面已经修好了。
native的VME实现
简要阅读后,发现native中用了一个哈希表来存储虚拟地址到物理地址的映射关系。为了让AM上的程序访存,它创建了一个文件,并在每次map的时候用mmap系统调用把虚拟地址空间映射到了这个文件里面。
用哈希表来管理显然是可以的,因为本质上虚拟地址到物理地址就是个映射关系。
可以在用户栈里面创建用户进程上下文吗?
不可以。如果ucontext在用户栈上创建用户进程上下文,那么调度到这个进程时,user_handler返回给__am_irq_handle的将会是用户地址空间下的用户栈中的进程上下文的地址。紧接着就会调用__am_switch函数,它会在当前的内核地址空间中试着读取用户地址空间下的用户栈的进程上下文,这显然是读不出来东西的。
支持虚存管理的多道程序
按照教程中所说,略微修改一下kcontext就可以运行了。现在的仙剑奇侠传是真的超级卡。
不过要注意的是,目前的实现下只可以先调度到用户进程,再调度到内核线程。假设说我们先调度到了内核线程,那么在这个内核线程又调度到用户线程的时候,__am_irq_handle就会把内核地址空间的第一级页表的指针写入刚保存的内核线程的上下文的pdir里面。这会导致用户线程又切回内核线程的时候,内核线程的上下文的pdir不是NULL,这就会使得__am_irq_handle的__am_switch会把satp切成内核地址空间。但是问题就来了,现在的__am_irq_handle函数是跑在用户进程的用户栈里的,你要访问用户栈里的东西都得是用户地址空间才访问得到,而现在又被切成了内核地址空间,就会导致运行错误。
并发执行多个用户进程
Nanos-lite加载仙剑奇侠传和hello这两个用户进程
错误原因跟上面比较相似。假设首先调度到hello进程,这是没有问题的。但是当hello进程切换到仙剑奇侠传进程时,由于__am_irq_handle还在hello进程的用户栈里,但是在__am_switch中切成了仙剑奇侠传的用户地址空间,就会导致运行错误。
加载NTerm和hello内核线程, 然后从NTerm启动仙剑奇侠传
错误原因和上面一样,也是在从Nterm的用户地址空间切换到仙剑奇侠传的用户地址空间时会出错。
如果要解决上面的问题,最好的方法就是把用户的上下文以及异常处理所产生的函数栈帧都放到内核栈上。这样在切换了地址空间后,由于所有的用户地址空间都包含有内核地址空间,因而总是能顺利运行下去。
阶段3
来自外部的声音
灾难性的后果(这个问题有点难度)
回答问题前我们先假定中断后的中断处理程序的函数栈帧不在构造上下文附近的地方,也就是说中断处理过程所产生的函数栈帧不会相互干扰。
那么发生中断嵌套后,第一次保存的上下文信息将会被优先级更高的中断处理过程所覆盖,因此在执行完优先级更高的中断处理过程后,恢复优先级更高的中断处理过程的上下文时尚且正常,但是恢复第一次保存的上下文信息时因为读取的是被覆盖后的上下文,所以又会恢复到发生优先级更高的中断处理过程时候的状态。这就会使得一直重复“发生优先级更高的中断处理过程的状态”->“恢复上下文信息”这一过程,导致死循环。
如何支持中断嵌套
对于riscv32,软件上应该采取堆栈的形式保存中断上下文信息,不可以把上下文信息保存在固定的地方。硬件上则应该能够判断中断请求的优先级并选择允许在低优先级的中断中相应高优先级的中断。
实现抢占多任务
这是一个实打实的从NEMU到Nanos-lite的任务,但是如果你对之前的异常处理的过程很熟悉,那么这也很简单。
在NEMU中,需要我们在每条指令结束执行后判断当前有无中断信号,若有且mstatus处于开中断状态,那么就准备执行中断处理程序即可。大体框架在教程中已经明确了,这里我记录一下一些细节:
#define IRQ_TIMER 0x80000007 // for riscv32
word_t isa_raise_intr(word_t NO, vaddr_t epc)
{
cpu.mstatus &= ~(1 << 7);
cpu.mstatus |= (cpu.mstatus >> 3 & 1) << 7;
cpu.mstatus &= ~(1 << 3);
print_etrace(NO, epc);
cpu.mepc = epc;
cpu.mcause = NO;
return cpu.mtvec;
}
word_t isa_query_intr()
{
if (cpu.INTR && cpu.mstatus >> 3 & 1)
{
cpu.INTR = false;
return IRQ_TIMER;
}
return INTR_EMPTY;
}INSTPAT("0011000 00010 00000 000 00000 11100 11", mret, R,
s->dnpc = cpu.mepc;
cpu.mstatus &= ~(1 << 3);
cpu.mstatus |= (cpu.mstatus >> 7 & 1) << 3;
cpu.mstatus |= 1 << 7;);其中判断mstatus的MIE位十分重要,因为如果不判断,那么模拟器一启动就有可能去响应中断,但是这个时候mtvec都还没被操作系统所设置,那么就会直接跳到0地址导致崩溃。上面的一些位运算是用来设置mstatus的。此外,我们还需要实现dev_raise_intr和在CPU里添加INTR成员,这些我就不多做赘述了。
然后是在AM上正确处理好事件,因为在硬件上我们采用IRQ_TIMER作为mcause,那么在__am_irq_handle中自然也要把它识别出来并且设置事件为EVENT_IRQ_TIMER。注意这里并不需要给MEPC加4,因为中断发生时PC所指的指令在处理完中断后还是要继续执行的。为了让程序启动后的mstatus开中断,就应该在ucontext和kcontext里的上下文构造好mstatus,注意这个上下文里的mstatus是会经过mret的,所以应该设置为0x1880而不是0x1808。
最后则是在Nanos-lite中如何处置这个事件。按教程中的叙述,调用schedule进行调度即可。
中断和用户进程初始化
对于目前的实现,当_start设置正确的栈指针前,栈指针sp应该正好指向一个刚刚用于恢复的上下文的末尾地址。此时若发生中断,则会就地又保存一个上下文并处理中断。所以应该是没有问题的。
优先级调度
很简单,我这里用了一个数组表示其调用顺序:
Context *schedule(Context *prev)
{
static int schedule_table[] = {1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 0};
static int ptr = 0;
current->cp = prev;
PCB *switch_to = &pcb[schedule_table[ptr]];
ptr = (ptr + 1) % (sizeof(schedule_table) / sizeof(int));
current = switch_to;
return current->cp;
}打破循环依赖的方法
这虽然打破了循环依赖,但是还是有问题的。就如同上面所说,即便成功切换到另一个进程的地址空间,其异常处理过程的函数栈帧还是在原先的进程的用户栈里,属于是原先的进程的独有的地址空间,这会导致运行错误。
用户态和栈指针
不能。考虑一个程序加载到内存时,我们会在其内核栈上构造一个上下文。当调度到该进程时,会首先根据这个上下文进行恢复,然后PC会被改到程序入口处。但是在sp寄存器被_start里的代码改到用户栈前,sp寄存器还在内核栈上,而此时实际上在运行用户程序了,所以不能用栈指针判断当前位于用户态还是内核态。
系统的复杂性
首先是关于pp,ksp,np和usp该放在哪里的问题:np和usp显然是应该放在上下文里面的。而另外两个可以放在全局变量里。
此外就是当sp切换成了内核栈的时候并没有把pp切换成KERNEL,这会导致嵌套异常的时候(比如A异常处理中又发生了B异常),由于没有在进入CTE时修改pp,那么B异常会以为自己进入CTE前还是用户态,于是会又把sp切到ksp,导致覆盖了A异常处理的上下文以及一系列函数栈帧。
系统的复杂性(2)
其实就是这几个变量放在哪里的问题,上面已经说清楚了,显然np和usp是和对应的上下文高度相关的,所以应该保存在上下文里。
系统的复杂性(3)
上面也分析到了。
下面这个伪代码就是最容易读懂的一版:
void __am_asm_trap() {
if (pp == USER) { // pp is global
c->usp = $sp; // usp should be in Context
$sp = ksp; // ksp is global
}
c->np = pp; // np should be in Context
pp = KERNEL; // support re-entry of CTE
// save context
__am_irq_handle(c);
// restore context
pp = c->np;
if (c->np == USER) {
ksp = $sp;
$sp = c->usp;
}
return_from_trap();
}然后教程中对上述的方案实现给出了一定的优化:
void __am_asm_trap() {
c->sp = $sp;
if (ksp != 0) { // ksp is global
$sp = ksp;
}
c->np = (ksp == 0 ? KERNEL : USER); // np should be in Context
ksp = 0; // support re-entry of CTE
// save context
__am_irq_handle(c);
// restore context
if (c->np == USER) {
ksp = $sp;
}
$sp = c->sp;
return_from_trap();
}临时寄存器的方案
mips32这种就是让硬件上更复杂,则软件上更加轻松。riscv32这里硬件给的资源偏少,则软件上就要更下功夫,用一些巧方法。
实现内核栈和用户栈之间的切换
因为我这里做的是riscv32的内容,所以主要是以riscv32进行分析:
对于保存上下文,实质上是一个用户栈->内核栈或者内核栈->内核栈的过程。它俩都需要干的事情就是:
- 上下文中保存
c->sp = $sp - 最后把
ksp = 0
对于用户栈->内核栈,它还需要做的事情是:
- 改到内核栈
$sp = ksp - 修改上下文
c->np = USER
对于内核栈->内核栈,它需要做的额外的事情就是:
- 修改上下文
c->np = KERNEL
上述的这些保存上下文的过程,因为涉及到读取内存和获取CSR,在riscv32中不得不用到GPR作为媒介,所以会在跳转到内核栈后立马保存一些必要数量的GPR用作临时变量,然后再恢复回来。对于恢复上下文的过程,因为策略较为简单,则直接按照伪代码编写也没有问题。具体我修改的trap.S代码如下:
#define concat_temp(x, y) x ## y
#define concat(x, y) concat_temp(x, y)
#define MAP(c, f) c(f)
#if __riscv_xlen == 32
#define LOAD lw
#define STORE sw
#define XLEN 4
#else
#define LOAD ld
#define STORE sd
#define XLEN 8
#endif
#define REGS_LO16(f) \
f( 1) f( 3) f( 4) f( 5) f( 6) f( 7) f( 8) f( 9) \
f(10) f(11) f(12) f(13) f(14) f(15)
#ifndef __riscv_e
#define REGS_HI16(f) \
f(16) f(17) f(18) f(19) \
f(20) f(21) f(22) f(23) f(24) f(25) f(26) f(27) f(28) f(29) \
f(30) f(31)
#define NR_REGS 32
#else
#define REGS_HI16(f)
#define NR_REGS 16
#endif
#define REGS(f) REGS_LO16(f) REGS_HI16(f)
#define PUSH(n) STORE concat(x, n), (n * XLEN)(sp);
#define POP(n) LOAD concat(x, n), (n * XLEN)(sp);
#define CONTEXT_SIZE ((NR_REGS + 5) * XLEN)
#define OFFSET_SP ( 2 * XLEN)
#define OFFSET_CAUSE ((NR_REGS + 0) * XLEN)
#define OFFSET_STATUS ((NR_REGS + 1) * XLEN)
#define OFFSET_EPC ((NR_REGS + 2) * XLEN)
#define OFFSET_NP ((NR_REGS + 3) * XLEN)
#define USER 1
#define KERNEL 0
.align 3
.globl __am_asm_trap
.globl save_context
.globl save_context_user
.globl save_context_kernel
.globl handler
__am_asm_trap:
csrrw sp, mscratch, sp // exchange $sp and $mscratch
bnez sp, save_context_user// if (ksp != 0), goto save_context_user
csrr sp, mscratch // after this inst, sp is in $sp
j save_context_kernel
save_context_user: // now, usp is in $mscratch, ksp is in $sp
addi sp, sp, -CONTEXT_SIZE
PUSH(1)
li x1, USER
STORE x1, OFFSET_NP(sp) // set c->np = USER
csrr x1, mscratch // after this inst, usp is in $x1
STORE x1, OFFSET_SP(sp) // set c->sp = usp
POP(1)
csrw mscratch, x0 // set ksp = 0
j save_context
save_context_kernel: // sp is in $sp
addi sp, sp, -CONTEXT_SIZE
STORE x0, OFFSET_NP(sp) // set c->np = KERNEL
PUSH(1)
addi x1, sp, CONTEXT_SIZE
STORE x1, OFFSET_SP(sp) // set c->sp = sp
POP(1)
csrw mscratch, x0 // set ksp = 0
j save_context
save_context:
MAP(REGS, PUSH)
csrr t0, mcause
csrr t1, mstatus
csrr t2, mepc
STORE t0, OFFSET_CAUSE(sp)
STORE t1, OFFSET_STATUS(sp)
STORE t2, OFFSET_EPC(sp)
# set mstatus.MPRV to pass difftest
li a0, (1 << 17)
or t1, t1, a0
csrw mstatus, t1
mv a0, sp
call __am_irq_handle
mv sp, a0
LOAD t1, OFFSET_STATUS(sp)
LOAD t2, OFFSET_EPC(sp)
csrw mstatus, t1
csrw mepc, t2
MAP(REGS, POP)
# after restoring context
LOAD x1, OFFSET_NP(sp)
beqz x1, .+8 // if (c->np == KERNEL), no need to store ksp
addi x1, sp, CONTEXT_SIZE // after this inst, sp is in $x1
csrw mscratch, x1 // set ksp = $sp
POP(1)
LOAD sp, OFFSET_SP(sp) // set $sp = c->sp
mret在trap.S中完善了上下文切换的主体实现后,需要在cte_init中初始化mscratch为0(因为一开始肯定是内核栈上),然后我们还要在ucontext中设置np为USER,在kcontext中设置np为KERNEL即可。最后,我们还要在kcontext里设置sp为内核栈,而ucontext比较特殊,虽然从原则上来说还是要把sp设为用户栈,但是ucontext的函数原型不允许传个用户栈的地址进去,而且在Nanos-lite里强行设置会使得Nanos-lite变成仅供riscv32的不可移植软件,所以还是将其设到内核栈上,反正之后程序的_start会帮忙重新设置好用户栈的。
Context *ucontext(AddrSpace *as, Area kstack, void *entry)
{
Context *ctx = kstack.end - sizeof(Context);
memset(ctx, 0, sizeof(Context));
ctx->mepc = (uintptr_t)entry;
ctx->mstatus = 0x1880;
ctx->pdir = as->ptr;
ctx->np = 1; // USER
ctx->gpr[2] = (uintptr_t)kstack.end; //kernel-stack
return ctx;
}此外,肯定还要在NEMU里加一个名叫mscratch的CSR了。
Nanos-lite与并发bug (建议二周目/学完操作系统课思考)
目前我们的NEMU并不支持嵌套中断也只是单线程的模拟器,而且这两个用户进程的max_brk是在各自的PCB里维护的,况且二者的地址空间也不一样,应该是不存在并发bug的。
编写不朽的传奇
展示你的计算机系统
这个任务相较于上面做的上下文切换可谓是十分甚至九分的简单,只需要在Nanos-lite的events_read这个地方对从AM读到的键盘键位做个判断即可:
static char event_buf[300] = {0};
extern int fg_pcb;
size_t events_read(void *buf, size_t offset, size_t len)
{
size_t event_buf_len = strlen(event_buf);
if (event_buf_len == 0)
{
AM_INPUT_KEYBRD_T keybrd = io_read(AM_INPUT_KEYBRD);
switch (keybrd.keycode)
{
case AM_KEY_NONE:
return 0;
case AM_KEY_F1:
fg_pcb = 1;
return 0;
case AM_KEY_F2:
fg_pcb = 2;
return 0;
case AM_KEY_F3:
fg_pcb = 3;
return 0;
default:
sprintf(event_buf, "k%c %s\n", keybrd.keydown ? 'd' : 'u',
keyname[keybrd.keycode]);
}
}
event_buf_len = strlen(event_buf);
size_t ret = (event_buf_len < len ? event_buf_len : len);
memcpy(buf, event_buf, ret);
memmove(event_buf, event_buf + ret, event_buf_len - ret + 1);
return ret;
}然后真正的fg_pcb的定义在proc.c里,充当调度用的变量。
int fg_pcb = 1;
Context *schedule(Context *prev)
{
static int schedule_table[] = {0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
static int ptr = 0;
current->cp = prev;
PCB *switch_to = &pcb[schedule_table[ptr] * fg_pcb];
ptr = (ptr + 1) % (sizeof(schedule_table) / sizeof(int));
current = switch_to;
return current->cp;
}下面是成果演示,确实很酷呢:
编译ONScripter到Linux native
在我的电脑需要额外安装一些软件,比如:
sudo apt install libsdl-mixer1.2-dev libsdl-ttf2.0-dev其他的按照教程走就很容易了。
缓存和字体光栅化
因为这个函数是对字体库的一个字符进行光栅化,所以调色盘的内容和传入的fg和bg是相关的,因此代码这里在生成了一个fg和bg对应的调色盘之后就会保存下来,下次再需要生成的时候会判断是不是之前的fg和bg,如果是,那么就沿用上次的,否则就重新生成。如果多次用同样的fg和bg参数调用该函数应该会有一定的性能提升,当然了如果fg和bg老是在变就没啥用。
运行ONScripter
完善miniSDL库
在timer.c里面,这个计时器的回调函数和PA3里面填充音频数据的回调函数实现方法差不太多,都得用一个辅助函数。而timer.c和audio.c的区别在于这里的计时器可能会有多个,所以在实现上我们可以开一个合适的固定大小的计时器信息数组,每次分配的时候就分配可用的下标最小的那一个。这样一来似乎每次跑回调函数的时候都需要遍历整个数组,效率可能比较低下,因而实际上我们可以维护一个被分配的最大下标,这样就可以仅遍历到最大下标即可。
#define SDL_TIMER_RECORD_MAX 1024
typedef struct
{
bool enabled;
uint32_t last_time;
uint32_t interval;
void *param;
SDL_NewTimerCallback callback;
} SDL_Timer_Record;
static SDL_Timer_Record tr[SDL_TIMER_RECORD_MAX];
static int tr_max = 0;
void TimerCallbackHelper()
{
static bool flag = false;
if (flag)
return;
flag = true;
for (int i = 1; i <= tr_max; i++)
{
if (!tr[i].enabled)
continue;
uint32_t before = SDL_GetTicks();
if (before - tr[i].last_time < tr[i].interval)
continue;
uint32_t ret = tr[i].callback(tr[i].interval, tr[i].param);
tr[i].last_time = before;
tr[i].interval = ret;
}
flag = false;
}
SDL_TimerID SDL_AddTimer(uint32_t interval, SDL_NewTimerCallback callback,
void *param)
{
int id = 0;
for (int i = 1; i <= tr_max; i++)
{
if (!tr[i].enabled)
{
id = i;
break;
}
}
if (id == 0)
{
if (tr_max + 1 >= SDL_TIMER_RECORD_MAX)
{
assert(0);
return 0;
}
id = ++tr_max;
}
tr[id] =
(SDL_Timer_Record){true, SDL_GetTicks(), interval, param, callback};
return (void *)(uintptr_t)id;
}
int SDL_RemoveTimer(SDL_TimerID id)
{
int int_id = (int)(uintptr_t)id;
tr[int_id].enabled = false;
return 1;
}感觉框架代码中给出的SDL_TimerId是void *类型的感觉有点奇怪。于是我就去看了下源码,看了SDL1.2的源码后发现是官方的实现方法是链表,因而官方的SDL_TimerId就是一个指向链表里的元素的指针。看来这里教程是想让我们的实现更加自由。
接着是完善一下event.c,之前我们只有键盘事件,而现在会有其他用户自定义的事件了,因而我们要用一个队列来缓冲一下没有处理的事件。在我的实现中我用的是环形队列,这在之前已经写过好多次了,没有什么难度了。在实现完这个队列后,我们也要把之前的获取键盘事件的操作添加到队列中去,这样方便用统一的方式处理各类事件。
需要注意的是,SDL_PeepEvents的SDL_GETEVENT要求是找到符合mask(阅读SDL_EVENTMASK宏,会知道mask其实就是一个关于SDL_Event.type的bitset)的事件,写入到ev中并删除。因为有用mask过滤的过程,所以不一定是开头第一个事件就正好是,因而在做了SDL_GETEVENT后,需要把环形队列中开头到被删除的事件之间的事件整体往后挪一下,不然会造成空间的浪费,也容易导致后续取到一个之前取过的事件。
#define SDL_EVENTS_MAX 1024
SDL_Event evt[SDL_EVENTS_MAX];
static int evt_l = 0, evt_r = 0, evt_len = 0;
void AudioCallbackHelper();
void TimerCallbackHelper();
static int pull_keyboard_event()
{
SDL_Event ev;
char buf[100];
int rd = NDL_PollEvent(buf, sizeof(buf) / sizeof(char));
if (rd == 0)
return 0;
if (buf[0] == 'k')
{
switch (buf[1])
{
case 'd':
ev.key.type = SDL_KEYDOWN;
break;
case 'u':
ev.key.type = SDL_KEYUP;
break;
default:
assert(0);
}
char *event_key_name = buf + 3;
buf[strlen(buf) - 1] = '\0';
for (int i = 0; i < sizeof(keyname) / sizeof(char *); i++)
{
if (strcmp(keyname[i], event_key_name) == 0)
{
ev.key.keysym.sym = i;
break;
}
}
key_state[ev.key.keysym.sym] = (ev.key.type == SDL_KEYDOWN);
}
else
{
assert(0);
}
SDL_PushEvent(&ev);
return 1;
}
int pop_event(SDL_Event *ev)
{
if (evt_len == 0)
return 0;
assert(evt_len > 0);
*ev = evt[evt_l];
evt_l = (evt_l + 1) % SDL_EVENTS_MAX;
evt_len--;
assert(evt_len >= 0);
return 1;
}
int SDL_PushEvent(SDL_Event *ev)
{
TimerCallbackHelper();
AudioCallbackHelper();
evt[evt_r] = *ev;
evt_r = (evt_r + 1) % SDL_EVENTS_MAX;
evt_len++;
assert(evt_len <= SDL_EVENTS_MAX);
return 1;
}
int SDL_PollEvent(SDL_Event *ev)
{
TimerCallbackHelper();
AudioCallbackHelper();
pull_keyboard_event();
return pop_event(ev);
}
int SDL_WaitEvent(SDL_Event *event)
{
TimerCallbackHelper();
AudioCallbackHelper();
while (evt_len == 0)
{
pull_keyboard_event();
}
return pop_event(event);
}
int SDL_PeepEvents(SDL_Event *ev, int numevents, int action, uint32_t mask)
{
TimerCallbackHelper();
AudioCallbackHelper();
assert(numevents == 1);
assert(action == SDL_GETEVENT);
int used = 0;
switch (action)
{
case SDL_GETEVENT:
for (int ptr = evt_l; ptr != evt_r && used < numevents;
ptr = (ptr + 1) % SDL_EVENTS_MAX)
{
if ((SDL_EVENTMASK(evt[ptr].type) & mask) == 0)
continue;
ev[used++] = evt[ptr];
// remove evt[ptr]
if (ptr > evt_l)
{
for (int i = ptr; i > evt_l; i--)
evt[i] = evt[(i - 1 + SDL_EVENTS_MAX) % SDL_EVENTS_MAX];
}
else if (ptr < evt_l)
{
for (int i = ptr; i >= 0; i--)
evt[i] = evt[(i - 1 + SDL_EVENTS_MAX) % SDL_EVENTS_MAX];
for (int i = SDL_EVENTS_MAX - 1; i > evt_l; i--)
evt[i] = evt[(i - 1 + SDL_EVENTS_MAX) % SDL_EVENTS_MAX];
}
evt_len--;
evt_l++;
}
break;
default:
assert(0);
}
return used;
}最后是file.c。这是最难实现的,因为在网上找不到SDL1.2的关于SDL_RWFromFile和SDL_RWFromMem的文档,特别是SDL_RWops的各个函数的具体语义……只能靠SDL2的文档进行合理猜测了🤣。这个地方其实就是把普通文件和内存文件都抽象成SDL的抽象文件,然后你给出这个抽象文件的读取、写入等一系列函数,使得这个抽象文件能用就可以了。
对于SDL_RWFromFile,就是让你把普通文件抽象成SDL的抽象文件。这只需要我们用glibc的fopen得到FILE *,然后用glibc里面的比如fseek,fread实现那一堆回调函数就可以了。那堆回调函数的语义跟glibc的差不太多,但还是有所不同,比如SDL的seek需要返回文件偏移量,而glibc的fseek可不会,所以要用ftell得到文件偏移量才行。
而对于SDL_RWFromMem,就是让你把一段连续内存抽象成SDL的抽象文件。教程里说过可以用glibc的fmemopen把这一段内存装化为FILE *来用,因此在调用fmemopen后基本上和SDL_RWFromFile差不多的。
static int64_t seek(struct SDL_RWops *f, int64_t offset, int whence)
{
fseek(f->fp, offset, whence);
return ftell(f->fp);
}
static size_t read(struct SDL_RWops *f, void *buf, size_t size, size_t nmemb)
{
return fread(buf, size, nmemb, f->fp);
}
static size_t write(struct SDL_RWops *f, const void *buf, size_t size,
size_t nmemb)
{
return fwrite(buf, size, nmemb, f->fp);
}
static int close(struct SDL_RWops *f)
{
free(f);
return fclose(f->fp);
}
static int64_t _size(struct SDL_RWops *f)
{
return f->mem.size;
}
SDL_RWops *SDL_RWFromFile(const char *filename, const char *mode)
{
SDL_RWops *ret = malloc(sizeof(SDL_RWops));
FILE *f = fopen(filename, mode);
fseek(f, 0, SEEK_END);
int size_val = ftell(f);
fseek(f, 0, SEEK_SET);
*ret = (SDL_RWops){.size = _size,
.seek = seek,
.read = read,
.write = write,
.close = close,
.type = RW_TYPE_FILE,
.fp = f,
.mem = {.size = size_val}};
return ret;
}
SDL_RWops *SDL_RWFromMem(void *mem, int size)
{
SDL_RWops *ret = malloc(sizeof(SDL_RWops));
FILE *f = fmemopen(mem, size, "r+");
*ret = (SDL_RWops){.size = _size,
.seek = seek,
.read = read,
.write = write,
.close = close,
.type = RW_TYPE_MEM,
.fp = f,
.mem = {.size = size, .base = mem}};
return ret;
}完善SDL_image库
IMG_Load_RW实际上实现很简单,和IMG_Load差不太多:
SDL_Surface *IMG_Load_RW(SDL_RWops *src, int freesrc)
{
assert(src->type == RW_TYPE_MEM);
assert(freesrc == 0);
size_t size_val = src->size(src);
uint8_t *buf = (uint8_t *)malloc(size_val);
src->seek(src, 0, RW_SEEK_SET);
src->read(src, buf, sizeof(*buf), size_val);
return STBIMG_LoadFromMemory(buf, size_val);
}而实现IMG_isPNG则需要知道PNG格式的图片的魔数,这个维基百科上有写。
int IMG_isPNG(SDL_RWops *src)
{
src->seek(src, 0, RW_SEEK_SET);
uint8_t buf[8];
uint8_t correct[8] = {0x89, 0x50, 0x4E, 0x47, 0x0d, 0x0a, 0x1a, 0x0a};
src->read(src, buf, sizeof(*buf), 8);
return memcmp(buf, correct, 8) == 0;
}这样,现在就可以在Navy native上运行ONScripter了:
在ONScripter中播放BGM
显然,你要去实现上面的那些API,并且还要实现Mix_OpenAudio和Mix_CloseAudio两个函数。说实话SDL的文档并不是那么易懂,还是来简要地梳理一下吧:首先Mix_OpenAudio和Mix_CloseAudio是用来调用SDL_OpenAudio和SDL_CloseAudio的,所以它们是用来注册音频的回调函数的,这非常重要,不然就播不出来声音。而Mix_PlayMusic是为回调函数里的声音提供声音来源信息的,而这个信息是从Mix_LoadMUS_RW所打开的音频文件所得来的。因此回调函数里面就是根据Mix_PlayMusic的声音来源信息解码音频,进而把声音信息塞进stream中的。具体实现如下:
static SDL_AudioSpec spec;
static Mix_Music *cur_music = NULL;
static int music_volume = MIX_MAX_VOLUME;
static int music_loops = 0;
static bool music_stopped = true;
static uint8_t *frame = NULL;
static void callback(void *userdata, uint8_t *stream, int len)
{
memset(stream, 0, len);
if (!music_stopped)
{
int samples_per_channel =
stb_vorbis_get_samples_short_interleaved((stb_vorbis *)cur_music,
spec.channels,
(void *)frame,
len / sizeof(int16_t));
int nbyte = samples_per_channel * spec.channels * (spec.format / 8);
SDL_MixAudio(stream, frame, nbyte, music_volume);
}
}
int Mix_OpenAudio(int frequency, uint16_t format, int channels, int chunksize)
{
spec = (SDL_AudioSpec){.freq = frequency,
.format = format,
.channels = channels,
.samples = chunksize / (format / 8) / channels,
.callback = callback,
.size = chunksize,
.userdata = NULL};
frame = malloc(chunksize);
SDL_OpenAudio(&spec, NULL);
SDL_PauseAudio(false);
return 0;
}
void Mix_CloseAudio()
{
SDL_CloseAudio();
}
Mix_Music *Mix_LoadMUS_RW(SDL_RWops *src)
{
size_t size_val = src->size(src);
uint8_t *buf = malloc(size_val);
src->seek(src, 0, RW_SEEK_SET);
src->read(src, buf, sizeof(*buf), size_val);
int error;
return (Mix_Music *)stb_vorbis_open_memory(buf, size_val, &error, NULL);
}
void Mix_FreeMusic(Mix_Music *music)
{
if (music == cur_music)
music_stopped = true;
stb_vorbis_close((stb_vorbis *)music);
}
int Mix_PlayMusic(Mix_Music *music, int loops)
{
cur_music = music;
music_loops = loops;
music_stopped = false;
return 0;
}
int Mix_VolumeMusic(int volume)
{
int old_volume = music_volume;
music_volume = volume;
return old_volume;
}
int Mix_HaltMusic()
{
music_stopped = true;
return 0;
}
int Mix_PlayingMusic()
{
return !music_stopped;
}然后你可能会发现你得按一个键才能播一会儿声音,这是因为ONScripter往往在SDL_WaitEvent里面忙等。所以在SDL_WaitEvent的循环里也添上回调函数的辅助调用函数即可,而且这样可以解决之前需要按多次键盘才能让游戏播放下一页的问题。
在ONScripter中实现BGM的自动重放
这个实现起来很舒服啊,至少你知道你要干什么,之前看SDL2的文档猜SDL1.2的函数的语义可并不这么有意思。简而言之就是,loops参数代表会重复播放多少次(如果是0,就是直播1次;如果是1,就是播2次)。所以小改一下回调函数,在播完一次后检测是否可以再播,然后用stb_vorbis_seek_start复位即可。
static int64_t music_loops = 0;
...
static void callback(void *userdata, uint8_t *stream, int len)
{
memset(stream, 0, len);
if (!music_stopped)
{
int samples_per_channel =
stb_vorbis_get_samples_short_interleaved((stb_vorbis *)cur_music,
spec.channels,
(void *)frame,
len / sizeof(int16_t));
if (samples_per_channel == 0)
{
if (music_loops != 0)
{
music_loops--;
stb_vorbis_seek_start((stb_vorbis *)cur_music);
samples_per_channel = stb_vorbis_get_samples_short_interleaved(
(stb_vorbis *)cur_music, spec.channels, (void *)frame,
len / sizeof(int16_t));
}
}
int nbyte = samples_per_channel * spec.channels * (spec.format / 8);
SDL_MixAudio(stream, frame, nbyte, music_volume);
}
}演示如下,这BGM还挺好听的:
在ONScripter中播放音效
首先解释一下这里的播放的音效和播放的音乐的区别:音乐就是游戏的BGM,它一直存在,在回调函数中肯定是要考虑它的音频数据的;而SDL_mixer里有多个通道(channel,我更想把它说成音轨),音效的声音数据(chunk)就可以放在某个音轨上,让某一个音轨播放这段声音数据。最终回调函数里将会是音乐+各个音轨的声音的混合。弄明白了这一点,就能够实现这些API了。
这里需要我们注意一些API的文档,比如Mix_LoadWAV_RW,它并不一定是只读取WAV格式的音乐文件,而是如同文档里所说的,“Load a supported audio format into a chunk.”。而我们目前支持ogg格式的音频文件,所以可以简单地用vorbis库加载一下就行。
由于这里的通道和之前BGM在回调函数中做的事情比较类似,所以可以照着写一个即可。不过如果这里的某个通道把自己的音乐播放完了,就应该把自己设置成空闲状态,否则可能会出现有时候播不出来声音的问题。
我的实现如下,可能会有一点小问题,但是总体大问题还是没有的:
typedef struct
{
void *v;
int volume;
int64_t loops;
} Mix_Music;
typedef struct
{
void *v;
int64_t loops;
} Mix_Chunk;static SDL_AudioSpec spec;
static Mix_Music *cur_music = NULL;
#define SDL_CHANNEL_MAX 128
typedef struct
{
Mix_Chunk *chunk;
int64_t loops;
int volume;
bool paused;
} Mix_Channel;
static void (*channel_finished_callback)(int channel);
static void call_callback(int channel)
{
if (channel_finished_callback != NULL)
channel_finished_callback(channel);
}
static Mix_Channel channels[SDL_CHANNEL_MAX];
static int channel_num = 8;
static uint8_t *frame = NULL;
static int play_audio(uint8_t *stream, int len, stb_vorbis *v, int64_t *loops,
int volume)
{
int samples_per_channel =
stb_vorbis_get_samples_short_interleaved(v, spec.channels,
(void *)frame,
len / sizeof(int16_t));
if (samples_per_channel == 0)
{
if (*loops != 0)
{
(*loops)--;
stb_vorbis_seek_start(v);
samples_per_channel =
stb_vorbis_get_samples_short_interleaved(v, spec.channels,
(void *)frame,
len / sizeof(int16_t));
}
}
int nbyte = samples_per_channel * spec.channels * (spec.format / 8);
SDL_MixAudio(stream, frame, nbyte, volume);
return nbyte;
}
static void callback(void *userdata, uint8_t *stream, int len)
{
memset(stream, 0, len);
if (Mix_PlayingMusic())
{
play_audio(stream, len, cur_music->v, &cur_music->loops,
cur_music->volume);
}
for (int i = 0; i < channel_num; i++)
{
if (channels[i].paused)
continue;
if (channels[i].chunk == NULL)
continue;
int nbyte = play_audio(stream, len, channels[i].chunk->v,
&channels[i].loops, channels[i].volume);
if (nbyte == 0 && channels[i].loops == 0)
{
channels[i].chunk = NULL;
}
}
}
// General
int Mix_OpenAudio(int frequency, uint16_t format, int channels, int chunksize)
{
spec = (SDL_AudioSpec){.freq = frequency,
.format = format,
.channels = channels,
.samples = chunksize / (format / 8) / channels,
.callback = callback,
.size = chunksize,
.userdata = NULL};
frame = malloc(chunksize);
SDL_OpenAudio(&spec, NULL);
SDL_PauseAudio(false);
return 0;
}
void Mix_CloseAudio()
{
SDL_CloseAudio();
}
// Samples
Mix_Chunk *Mix_LoadWAV_RW(SDL_RWops *src, int freesrc)
{
Mix_Chunk *ret = malloc(sizeof(Mix_Chunk));
size_t data_size = src->size(src);
uint8_t *data_buf = malloc(data_size);
src->seek(src, 0, RW_SEEK_SET);
src->read(src, data_buf, 1, data_size);
int error;
*ret = (Mix_Chunk){
.v = stb_vorbis_open_memory(data_buf, data_size, &error, NULL),
.loops = 0,
};
if (freesrc)
src->close(src);
return ret;
}
void Mix_FreeChunk(Mix_Chunk *chunk)
{
for (int i = 0; i < channel_num; i++)
{
if (channels[i].chunk != chunk)
continue;
channels[i].chunk = NULL;
call_callback(i);
}
stb_vorbis_close(chunk->v);
free(chunk);
}
// Channels
int Mix_AllocateChannels(int numchans)
{
assert(numchans <= SDL_CHANNEL_MAX);
if (numchans < 0)
return channel_num;
for (int i = numchans; i < channel_num; i++)
call_callback(i);
for (int i = channel_num; i < numchans; i++)
{
channels[i].volume = MIX_MAX_VOLUME;
channels[i].chunk = NULL;
channels[i].loops = 0;
channels[i].paused = true;
}
channel_num = numchans;
return numchans;
}
int Mix_Volume(int channel, int volume)
{
assert(channel != -1 || volume != -1);
if (volume == -1)
return channels[channel].volume;
if (channel == -1)
{
int avg = 0;
for (int i = 0; i < channel_num; i++)
avg += channels[channel].volume;
avg /= channel_num;
for (int i = 0; i < channel_num; i++)
channels[channel].volume = volume;
return avg;
}
volume = volume < MIX_MAX_VOLUME ? volume : MIX_MAX_VOLUME;
int old_volume = channels[channel].volume;
channels[channel].volume = volume;
return old_volume;
}
int Mix_PlayChannel(int channel, Mix_Chunk *chunk, int loops)
{
if (channel == -1)
{
for (int i = 0; i < channel_num; i++)
{
if (channels[i].chunk != NULL)
continue;
channel = i;
break;
}
if (channel == -1)
return -1;
}
channels[channel].chunk = chunk;
channels[channel].loops = loops;
channels[channel].paused = false;
channels[channel].volume = MIX_MAX_VOLUME;
return channel;
}
void Mix_Pause(int channel)
{
channels[channel].paused = true;
}
void Mix_ChannelFinished(void (*channel_finished)(int channel))
{
channel_finished_callback = channel_finished;
}
// Music
Mix_Music *Mix_LoadMUS_RW(SDL_RWops *src)
{
size_t size_val = src->size(src);
uint8_t *buf = malloc(size_val);
src->seek(src, 0, RW_SEEK_SET);
src->read(src, buf, sizeof(*buf), size_val);
int error;
Mix_Music *ret = malloc(sizeof(Mix_Music));
ret->v = stb_vorbis_open_memory(buf, size_val, &error, NULL);
ret->loops = 0;
ret->volume = MIX_MAX_VOLUME;
return ret;
}
void Mix_FreeMusic(Mix_Music *music)
{
if (music == cur_music)
{
cur_music = NULL;
}
stb_vorbis_close(music->v);
free(music);
}
int Mix_PlayMusic(Mix_Music *music, int loops)
{
cur_music = music;
cur_music->loops = loops;
return 0;
}
int Mix_VolumeMusic(int volume)
{
if (!Mix_PlayingMusic())
return MIX_MAX_VOLUME;
int old_volume = cur_music->volume;
if (volume != -1)
cur_music->volume = volume;
return old_volume;
}
int Mix_HaltMusic()
{
cur_music = NULL;
return 0;
}
int Mix_PlayingMusic()
{
return cur_music != NULL;
}下面是个简单的演示:
在ONScripter中播放音效(2)
从教程中可以看到,单纯频率提升会带来样本数的增多,而单纯的增加声道则会增加每个样本的的比特数。所以说,如果我们最终要播放的是总共B的Hz的双声道音频,而输入的是Hz的声道音频,那么输入的音频字节数量就应该是
这样在扩展之后才能生成字节的用于播放的音频。在实现上只需要小改一下上面我自己定义的play_audio函数,增加一个临时缓冲区就够了:
static uint8_t *input_frame = NULL;
static uint8_t *frame = NULL;
static int play_audio(uint8_t *stream, int stream_len, stb_vorbis *v,
int64_t *loops, int volume)
{
stb_vorbis_info info = stb_vorbis_get_info(v);
int input_len = stream_len * info.channels / spec.channels *
info.sample_rate / spec.freq;
int samples_per_channel =
stb_vorbis_get_samples_short_interleaved(v, info.channels,
(void *)input_frame,
input_len / sizeof(int16_t));
if (samples_per_channel == 0)
{
if (*loops != 0)
{
(*loops)--;
stb_vorbis_seek_start(v);
samples_per_channel =
stb_vorbis_get_samples_short_interleaved(v, info.channels,
(void *)input_frame,
input_len /
sizeof(int16_t));
}
}
int input_nbyte = samples_per_channel * info.channels * sizeof(int16_t);
int16_t *frame16 = (int16_t *)frame;
for (int i = 0; i < input_nbyte; i += sizeof(int16_t))
{
int16_t sample = *(int16_t *)(&input_frame[i]);
for (int j = 0; j < (spec.freq / info.sample_rate) *
(spec.channels / info.channels);
j++)
*(frame16++) = sample;
}
int nbyte = (uint8_t *)frame16 - frame;
SDL_MixAudio(stream, frame, nbyte, volume);
return input_nbyte;
}在游戏“星之梦”中,可以听游戏刚开始男主走近并打开“天象馆”大门时候的声音来判断是否实现正确,这段音频是22050Hz单声道的,所以要在原先的基础上乘4倍即可。
实现AM native的磁盘
教程中让我们首先实现一下AM native的IOE中的磁盘。在这里我们直接把一个环境变量的路径对应的文件当作磁盘的,所以实现起来很简单,用一些glibc里操作文件的库函数就够了。况且框架代码都已经编写完了,不用我们亲自操刀。但是有个地方需要小改一下,因为往磁盘里读取、写入数据时的块数量可能是0,此时fread和fwrite的返回值不是1,要做个判断才行:
void __am_disk_blkio(AM_DISK_BLKIO_T *io)
{
if (fp)
{
fseek(fp, io->blkno * BLKSZ, SEEK_SET);
int ret;
if (io->write)
ret = fwrite(io->buf, io->blkcnt * BLKSZ, 1, fp);
else
ret = fread(io->buf, io->blkcnt * BLKSZ, 1, fp);
if (io->blkcnt > 0)
assert(ret == 1);
else
assert(ret == 0);
}
}然后就是在Nanos-lite上添加磁盘设备的支持了。在Nanos-lite上的磁盘读写和AM native上的读写并不一样:Nanos-lite上是针对于字节的,而AM native上则是针对于磁盘的各个块。为了把字节序列用块序列表示,我们可以把这个字节序列分成三大块:
- 字节序列左端点所在的块
l_blk - 字节序列右端点所在的块
r_blk - 字节序列左右端点之间的块
l_blk~r_blk
这样我们只需要多申请一个块大小的临时缓冲区,就可以拿它作为中间量处理一些边缘的块,然后再调用AM的IOE接口。而中间的块因为都是完整的块,所以可以直接调用AM的IOE接口。具体实现如下:
static int disk_blk_size = 0, disk_blk_cnt = 0;
#define BLKSZ 512
static uint8_t blkbuf[BLKSZ] = {0};
size_t disk_read(void *buf, size_t offset, size_t len)
{
size_t l = offset;
size_t l_blk = l / disk_blk_size;
size_t r = offset + len;
size_t r_blk = r / disk_blk_size;
if (l_blk == r_blk)
{
io_write(AM_DISK_BLKIO, false, blkbuf, l_blk, 1);
memcpy(buf, blkbuf + l % disk_blk_size, r - l);
}
else
{
io_write(AM_DISK_BLKIO, false, blkbuf, l_blk, 1);
memcpy(buf, blkbuf + l % disk_blk_size,
disk_blk_size - l % disk_blk_size);
buf += disk_blk_size - l % disk_blk_size;
io_write(AM_DISK_BLKIO, false, buf, l_blk + 1, r_blk - l_blk - 1);
buf += (r_blk - l_blk - 1) * disk_blk_size;
io_write(AM_DISK_BLKIO, false, blkbuf, r_blk, 1);
memcpy(buf, blkbuf, r % disk_blk_size);
}
return len;
}
size_t disk_write(const void *buf, size_t offset, size_t len)
{
size_t l = offset;
size_t l_blk = l / disk_blk_size;
size_t r = offset + len;
size_t r_blk = r / disk_blk_size;
if (l_blk == r_blk)
{
io_write(AM_DISK_BLKIO, false, blkbuf, l_blk, 1);
memcpy(blkbuf + l % disk_blk_size, buf, r - l);
io_write(AM_DISK_BLKIO, true, blkbuf, l_blk, 1);
}
else
{
io_write(AM_DISK_BLKIO, false, blkbuf, l_blk, 1);
memcpy(blkbuf + l % disk_blk_size, buf,
disk_blk_size - l % disk_blk_size);
io_write(AM_DISK_BLKIO, true, blkbuf, l_blk, 1);
buf += disk_blk_size - l % disk_blk_size;
io_write(AM_DISK_BLKIO, true, (void *)buf, l_blk + 1,
r_blk - l_blk - 1);
buf += (r_blk - l_blk - 1) * disk_blk_size;
io_write(AM_DISK_BLKIO, false, blkbuf, r_blk, 1);
memcpy(blkbuf, buf, r % disk_blk_size);
io_write(AM_DISK_BLKIO, true, blkbuf, r_blk, 1);
}
return len;
}
void init_disk()
{
AM_DISK_CONFIG_T cfg = io_read(AM_DISK_CONFIG);
assert(cfg.present);
disk_blk_cnt = cfg.blkcnt;
disk_blk_size = cfg.blksz;
}注意到如果这个字节序列只跨了2个块,那么我将会以0的块长调用一次AM的IOE接口,所以上面才需要修改一下框架代码的assert。
因为我们的磁盘跟ramdisk的地位一样,只是它相较于ramdisk的容量更大,所以我们可以在实现了磁盘的读写操作后,让ramdisk的读写操作直接调用磁盘的读写操作,就不需要修改其他的有关ramdisk的代码了。
接下来应该在nanos-lite/src/resources.S中去掉.incbin "build/ramdisk.img",这样就不会把生成的ramdisk嵌入到内存中了。
最后是让AM native支持大屏幕,教程上的链接 是已经过时的实现,不适合ICS2024的AM native了。实际上现在只需要取消掉$AM_HOME/am/src/native/ioe/gpu.c的#define MODE_800x600这一行的注释就可以了。
为了玩上“星之梦”,还需要把“星之梦”的游戏数据放到磁盘上,这很简单,在$NAVY_HOME/fsimg/share/games下创建一个软链接就可以了。如果你实现正确,现在应该就可以在AM native上的Nanos-lite里启动ONScripter,进而玩上“星之梦”了。
实现NEMU的磁盘
教程中首先谈到的是程序给出的地址buf因为是虚拟地址无法被磁盘设备所理解,所以需要在Nanos-lite上添加一个专门用于磁盘读写的单个块大小的小缓存,因为这个缓存是在Nanos-lite的内核地址空间上,虚拟地址和物理地址是恒等映射的,所以拿它跟磁盘进行交互是可以让磁盘理解buf的地址的。我之前的disk_read和disk_write的实现中也不约而同地用上了这个小缓存(虽然用意不同),只需要小改一下就可以了:
size_t disk_read(void *buf, size_t offset, size_t len)
{
size_t l = offset;
size_t l_blk = l / disk_blk_size;
size_t r = offset + len;
size_t r_blk = r / disk_blk_size;
if (l_blk == r_blk)
{
io_write(AM_DISK_BLKIO, false, blkbuf, l_blk, 1);
memcpy(buf, blkbuf + l % disk_blk_size, r - l);
}
else
{
io_write(AM_DISK_BLKIO, false, blkbuf, l_blk, 1);
memcpy(buf, blkbuf + l % disk_blk_size,
disk_blk_size - l % disk_blk_size);
buf += disk_blk_size - l % disk_blk_size;
for (int i = l_blk + 1; i <= r_blk - 1; i++)
{
io_write(AM_DISK_BLKIO, false, blkbuf, i, 1);
memcpy(buf, blkbuf, disk_blk_size);
buf += disk_blk_size;
}
io_write(AM_DISK_BLKIO, false, blkbuf, r_blk, 1);
memcpy(buf, blkbuf, r % disk_blk_size);
}
return len;
}
size_t disk_write(const void *buf, size_t offset, size_t len)
{
size_t l = offset;
size_t l_blk = l / disk_blk_size;
size_t r = offset + len;
size_t r_blk = r / disk_blk_size;
if (l_blk == r_blk)
{
io_write(AM_DISK_BLKIO, false, blkbuf, l_blk, 1);
memcpy(blkbuf + l % disk_blk_size, buf, r - l);
io_write(AM_DISK_BLKIO, true, blkbuf, l_blk, 1);
}
else
{
io_write(AM_DISK_BLKIO, false, blkbuf, l_blk, 1);
memcpy(blkbuf + l % disk_blk_size, buf,
disk_blk_size - l % disk_blk_size);
io_write(AM_DISK_BLKIO, true, blkbuf, l_blk, 1);
buf += disk_blk_size - l % disk_blk_size;
for (int i = l_blk + 1; i < r_blk - 1; i++)
{
memcpy(blkbuf, buf, disk_blk_size);
io_write(AM_DISK_BLKIO, true, (void *)blkbuf, i, 1);
buf += disk_blk_size;
}
io_write(AM_DISK_BLKIO, false, blkbuf, r_blk, 1);
memcpy(blkbuf, buf, r % disk_blk_size);
io_write(AM_DISK_BLKIO, true, blkbuf, r_blk, 1);
}
return len;
}上面只是把Nanos-lite的内容写好了,实际上还需要完善riscv32-nemu的AM和NEMU中的有关磁盘的内容。那我们就首先实现一下NEMU中的内容。由于我们是把物理机上的一个文件当作磁盘用的,所以要先让NEMU知道这个文件在哪儿,注意到$NEMU_HOME/include/generated/autoconf.h有一个宏CONFIG_DISK_IMG_PATH,它就可以用来表示磁盘文件的路径,我们只需要在Kconfig里设置一下就行。
默认情况下,磁盘设备的设备寄存器被放在了0xa0000300的位置,而在它上面则有地址为0xa00003f8的串口设备的设备寄存器,所以我们的磁盘设备的设备寄存器的大小一定不能超过0xf8字节,因此这需要我们较为谨慎地考虑设备寄存器。对于AM中的抽象寄存器AM_DISK_CONFIG,有3个变量;对于AM_DISK_STATUS,虽然我们认为磁盘一直都会处于就绪状态,但还是给它分配1个变量;而对于AM_DISK_BLKIO,有4个变量。因为额外还有一个CMD命令寄存器,所以总共需要在设备寄存器里放9个变量,每个变量都是word_t大小的,对于riscv32而言就是0x24个字节,这显然是能够放得进去的。
此外,NEMU的disk获取到的buf的地址是它在模拟器里的地址,并不是pmem里的位置,所以要用guest_to_host进行一次转换。教程里给出的转换似乎有误,可能是因为教程这一块太久没更新过了,实际上直接调用guest_to_host(pa)就可以了。因此我的NEMU上的disk设备是如下进行实现的:
#define BLKSZ 512
enum
{
reg_present,
reg_blksz,
reg_blkcnt,
reg_ready,
reg_iowrite,
reg_iobuf,
reg_ioblkno,
reg_ioblkcnt,
reg_cmd,
nr_reg
};
static uint32_t space_size = nr_reg * sizeof(uint32_t);
static uint32_t *disk_base = NULL;
static FILE *f = NULL;
void do_io()
{
if (!disk_base[reg_cmd])
return;
paddr_t pa = disk_base[reg_iobuf];
void *buf = guest_to_host(pa);
size_t size = disk_base[reg_ioblkcnt] * BLKSZ;
size_t offset = disk_base[reg_ioblkno] * BLKSZ;
fseek(f, offset, SEEK_SET);
int ret;
if (disk_base[reg_iowrite])
ret = fwrite(buf, size, 1, f);
else
ret = fread(buf, size, 1, f);
if (size > 0)
assert(ret == 1);
else
assert(ret == 0);
disk_base[reg_cmd] = 0;
}
static void disk_ctl_io_handler(uint32_t offset, int len, bool is_write)
{
assert(len == 4);
switch (offset / 4)
{
case reg_present:
case reg_blkcnt:
case reg_blksz:
case reg_ready:
assert(!is_write);
break;
case reg_iowrite:
case reg_iobuf:
case reg_ioblkcnt:
case reg_ioblkno:
assert(is_write);
break;
case reg_cmd:
assert(is_write);
do_io();
break;
default:
assert(0);
}
}
void init_disk()
{
disk_base = (uint32_t *)new_space(space_size);
f = fopen(CONFIG_DISK_IMG_PATH, "r+");
Assert(f, "unable to initialize disk, wrong diskimg path = %s",
CONFIG_DISK_IMG_PATH);
disk_base[reg_present] = 1;
disk_base[reg_blksz] = BLKSZ;
fseek(f, 0, SEEK_END);
int file_size = ftell(f);
rewind(f);
disk_base[reg_blkcnt] = (file_size + BLKSZ - 1) / BLKSZ;
disk_base[reg_ready] = 1;
disk_base[reg_cmd] = 0;
#ifdef CONFIG_HAS_PORT_IO
add_pio_map("disk", CONFIG_DISK_CTL_PORT, disk_base, space_size,
disk_ctl_io_handler);
#else
add_mmio_map("disk", CONFIG_DISK_CTL_MMIO, disk_base, space_size,
disk_ctl_io_handler);
#endif
}如上文所述,我的设备寄存器是按照抽象寄存器设计的,所以我的AM就很好实现了:
#define DISK_PRESENT_ADDR (DISK_ADDR + 0x00)
#define DISK_BLKSZ_ADDR (DISK_ADDR + 0x04)
#define DISK_BLKCNT_ADDR (DISK_ADDR + 0x08)
#define DISK_READY_ADDR (DISK_ADDR + 0x0c)
#define DISK_IOWRITE_ADDR (DISK_ADDR + 0x10)
#define DISK_IOBUF_ADDR (DISK_ADDR + 0x14)
#define DISK_IOBLKNO_ADDR (DISK_ADDR + 0x18)
#define DISK_IOBLKCNT_ADDR (DISK_ADDR + 0x1c)
#define DISK_IOCMD_ADDR (DISK_ADDR + 0x20)
void __am_disk_config(AM_DISK_CONFIG_T *cfg)
{
cfg->present = inl(DISK_PRESENT_ADDR);
cfg->blkcnt = inl(DISK_BLKCNT_ADDR);
cfg->blksz = inl(DISK_BLKSZ_ADDR);
}
void __am_disk_status(AM_DISK_STATUS_T *stat)
{
stat->ready = inl(DISK_READY_ADDR);
}
void __am_disk_blkio(AM_DISK_BLKIO_T *io)
{
outl(DISK_IOWRITE_ADDR, io->write);
outl(DISK_IOBUF_ADDR, (uintptr_t)io->buf);
outl(DISK_IOBLKCNT_ADDR, io->blkcnt);
outl(DISK_IOBLKNO_ADDR, io->blkno);
outl(DISK_IOCMD_ADDR, 1);
}现在从原则上就可以成功在riscv32-nemu上的Nanos-lite上运行OnScripter了。不过你可能会发现一个Bug:某些时候播放的音乐总是还没播放完毕就被重置播放了。这是因为我在libSDL_mixer的不合适的实现导致的,具体而言是我在play_audio中,以为stb_vorbis_get_samples_short_interleaved返回的samples_per_channel为0就代表这个音乐已经播放完毕,需要重新复位。实际上不是这样的,因为有可能NEMU的audio缓冲区没空间了,导致向回调函数索要的数据长度也为0,即stream_len为0,那这样肯定也会导致stb_vorbis_get_samples_short_interleaved的返回值为0。所以应该把判断音乐播放完毕的条件改成是stream_len != 0 && samples_per_channel == 0,或者说发现stream_len为0就提前返回。
下面是一段演示,很卡,但是能运行是真的:
DMA和CPU cache
这个之后再简单了解一下吧。
如何在操作系统中实现fork()?
首先是应该创建一个新的地址空间,把原进程的地址空间原样地复制一份,这样就能克隆原进程的堆栈等信息,接着是
把创建一个新的PCB,并把原进程的PCB原样复制一份。为了能让这个新进程能跑,还要在它的内核栈上构建上下文用于之后进行恢复,新进程的上下文的信息基本上就是原进程的信息,不过需要修改一下a0寄存器,因为它会被用来表示fork的返回值。
体验窗口管理器NWM (NJU Window Manager)
出了好多Bug,有图像显示Bug,还有音频Bug,还有键盘事件Bug,最近没什么时间就先不弄了。
体验PA中的并发bug
因为NEMU里的显存缓冲区并没有加锁,因此有可能在一个进程写入显存但是尚未刷新的过程中,另一个进程切换过来写显存且没有覆盖上一个进程写入的内容,这样就会导致最终刷新输出的屏幕上的内容会有部分是之前进程写入的内容。
体验PA中的”崩溃不一致性”
之后再打算做一下。
必答题
分时多任务的具体过程
不失一般性地,我们假定是从hello程序切换到了仙剑奇侠传。
首先,NEMU的时钟设备给CPU传入中断信号(设置INTR为true),NEMU会在每一条指令执行完毕后检查是否有中断信号,如果有中断信号并且mstatus开中断,那么就会进入中断处理程序。
接着来到AM中的CTE部分,此时会根据上文所叙述的上下文切换的策略,在hello程序的内核栈上构造上下文并把satp寄存器调整为hello程序的地址空间。然后根据mcause的值被认定为时钟事件,接着会把这个事件传给Nanos-lite。
当Nanos-lite接收到该事件,就会调度进程,进而把进程切换成仙剑奇侠传,这实质上是把仙剑奇侠传的内核栈上的上下文地址传回去了。
AM的CTE收到这个上下文地址后,则会拿这个上下文来恢复上下文,恢复完毕后会切换成仙剑奇侠传的地址空间,并正确地设置pc和sp寄存器,使得仙剑奇侠传能够正常运行。
理解计算机系统
应该是"abc"这个字符串字面量被编译器放到了程序的.rodata段,这个段是只读的段。加载这个程序的时候.rodata所在的段所在的页也会是一个只读页,当程序试图在这个只读页上做写操作的时候,硬件将不会允许这样做。
我们用gdb调试能很容易找到问题:
Program received signal SIGSEGV, Segmentation fault.
0x0000555555555140 in main () at main.c:3
3 p[0] = 'A';
这说明程序试图用不应该的方式访问了内存或者访问了不该访问的内存。
打印数组p的地址,发现是0x555555556004。
输入命令info proc mappings,检查当前状态下的进程的地址空间的映射,发现有:
0x555555556000 0x555555557000 0x1000 0x2000 r--p /home/lijn/Templates/main
如果进一步看各个段的情况会更加明显,我们输入命令maintenance info sections:
[15] 0x555555556000->0x555555556008 at 0x00002000: .rodata ALLOC LOAD READONLY DATA HAS_CONTENTS
很显然证实了我们的猜想。
然而,在我通过dmesg看日志了后却发现了这个:
[55134.806066] main[164633]: segfault at 58f38c572004 ip 000058f38c571140 sp 00007ffe65da5660 error 6 in main[58f38c571000+1000] likely on CPU 2 (core 1, socket 0)
这个错误6很有意思,因为根据英特尔的手册,P位在这里不应该是0啊,但是我也无法理解了。
